本篇文章主要羅列了pandas模塊中serie的基本使用。環境是jupyter notebook python 3.7。
serie是能夠保存任何類型數據的一維數組,軸標簽統稱為索引,索引必須是唯一的散列且與數據的長度相同,默認情況下為np.arange(n)。
首先是import pandas模塊
import pandas as pd
1.創建一個系列series create
\space\space\space\space????a.通過python list創建serie
arr = [0, 1, 2, 3, 4]
s1 = pd.Series(arr)
結果如下 :

\space\space\space\space????b.創建系列時,可以自定義index索引
arr = [0, 1, 2, 3, 4]
order = [1,2,3,4,5]
s2 = pd.Series(arr, index=order)
結果如下 :

\space\space\space\space????c.通過numpy Ndarray 創建系列
和python list一樣,使用numpy ndarray也可以創建serie,同時索引不一定需要是自然數,可以是自定義的任何確定的數字,字符串。
import numpy as np
n = np.random.randn(5) # 創建一個隨機的Ndarray
index = ['a','b','c','d','e']
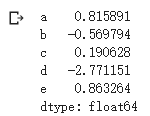
s3 = pd.Series(n,index=index) #索引可以不是自然數
結果如下 :
\space\space\space\space????d. 通過字典創建serie
d = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5}
s4 = pd.Series(d)
結果如下 :

2.對系列進行操作 serie manipulation
\space\space\space\space????a. 改變索引
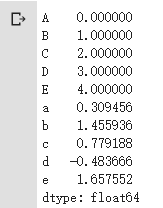
s1.index = np.array(['A','B','C','D','E'])
結果如下:
將原先的0-5索引改為ABCDE

\space\space\space\space????b. 對serie進行切片
使用中括號可以獲取serie的一部分,注意冒號是前包含后不包含的關系,例如在下面的例子中,切片部分索引的范圍是[1,4)。
s1[1:4]
#s1[:]
#s1[3:]
#s1[:3]
結果如下:

\space\space\space\space????c. 在serie的末尾添加另一個serie
s4 = s1.append(s3)
print(s4)
結果如下:
\space\space\space\space????d.丟棄serie中的某一項
s4 = s4.drop('e')
print(s4)
結果如下:

\space\space\space\space????e.基本運算加減乘除
arr1 = [0,1,2,3,4,5,7]
arr2 = [6,7,8,9,5]
s5 = pd.Series(arr2)
s6 = pd.Series(arr1)
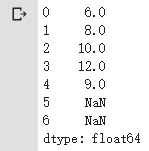
s5 = s5.add(s6)
print(s5)
#s5.sub(s6)
#s5.mul(s6)
#s5.div(s6)
使用add方法會對相對應的項進行加法運算,未定義的項在進行加減乘除運算后會變為np.nan未定義。
兩個serie進行加法運算的結果如下:
其余的基本運算與加法類似。
\space\space\space\space???? f. serie的統計學屬性
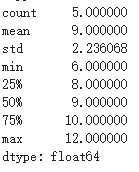
使用describe方法可以輸出serie的統計學屬性
s5.describe()
結果如下:
參考:
pandas入門之serie
Youtube pandas tutorial



![[十二省聯考2019]皮配](http://pic.xiahunao.cn/[十二省聯考2019]皮配)










,交易流水記錄的查詢)


,100億數據,1萬字段屬性的秒級檢索)

)