機器學習的理論部分學習知識點比較亂且雜。我這里通過幾篇文章,簡單總結一下自己對機器學習理論的理解,以防遺忘。第一篇文章主要概述了機器學習的基本任務以及一個常用的降維方法,主成分分析。
機器學習的基本任務
機器學習能實現許多不同的任務,基本分為以下幾類:
- 分類 : 算法需要判斷輸入屬于哪一種類別。例如通過一張人像圖片判斷人的身份。
- 回歸 : 算法需要將一個數值與輸入聯系起來。例如通過氣象學的
參數判斷24小時的溫度。 - 重寫 : 通過觀察輸入,將其重寫為文字形式。例如通過一張谷歌街道的圖片,識別街道的名稱。
- 翻譯 : 將一系列的符號文字轉化為另一種語言的符號和文字。例如將英語翻譯成中文,將Java代碼翻譯為對應的C++代碼。
- 異常尋找: 判斷輸入是不是非典型的。例如檢測是否有逆行的車輛。
- 合成 : 生成與樣本數據類似的新的樣本。例如合成另一個角度的風景圖。
- 降噪 : 對樣本數據進行降噪處理。
協方差矩陣
協方差矩陣用于描述各個維度之間的聯系,其元素是各個向量元素之間的協方差。
例如如果我們我們有N個維度為n的向量數據xix_ixi?,他們的協方差矩陣如下
Σ=1N∑i=1N(xi?μ)(xi?μ)T\Sigma = \frac{1}{N}\sum_{i=1}^{N}(x_i-\mu)(x_i-\mu)^TΣ=N1?i=1∑N?(xi??μ)(xi??μ)T
其中μ\muμ是數據xix_ixi?的平均向量。協方差矩陣維度為n*n且對稱。協方差矩陣中編碼了數據各個維度之間的相互關系,以及各個維度的方差。例如在n=2,二維平面中,協方差矩陣可以表示為 :
Σ=(σxxσxyσyxσyy)\Sigma = \left( \begin{matrix} \sigma_{xx}\space\space \sigma_{xy}\\ \sigma_{yx}\space\space\sigma_{yy} \end{matrix} \right) Σ=(σxx???σxy?σyx???σyy??)
主對角線描述了該維度上數據的方差,副對角線描述了各個維度之間的協方差,當各個維度處于相同數量級時可以一定程度上反應各個維度之間的相關性。
主成分分析
現實生活中的樣本數據的分布可能與很多的潛在因素有關,因此使得我們的數據往往呈現出高維的形式。高維度的數據會對我們進行數據分析造成很多干擾,例如在我們進行分類分析時,隨著樣本容量的不斷增大,維度越高,計算量將呈幾何倍數的增長且難以避免的會有噪聲的影響。因此如何降維也是數據預處理十分重要的步驟。其中,主成分分析可以有效地降低樣本數據的維度,減少計算量的同時使得樣本數據對噪音干擾更不敏感。
主成分分析 principal component analysis, 其中心思想是將高維度的數據,投影到低維度,以此來實現降維。例如下圖中,將原本的二維空間(O,i1i_1i1?,i2i_2i2?)中的數據,投影到向量i1′i{_1}'i1?′上。主成分分析的要點,即是將數據投影到新的坐標系中,其中坐標系的前幾個基底向量應該包含樣本數據最多的信息量。在進行主成分分析之間,要對數據進行預處理,中心化規格化數據,即對每個數據作減去平均值并除以標準差的操作。
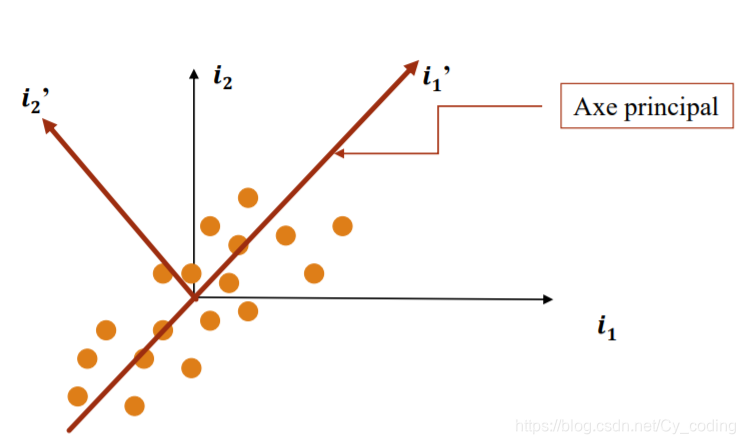
主成分分析的數學表示如下:
對于每個在原始坐標系中的數據點xix_ixi?,xi=xi1i1+xi2i1+...+xini1x_i = x_{i1}i_1 + x_{i2}i_1 +... +x_{in}i_1xi?=xi1?i1?+xi2?i1?+...+xin?i1?,其中xinx_{in}xin?是xix_ixi?在各個維度的分量。將數據投影到新的坐標軸i1′i{_1}'i1?′后,新的坐標為xi1′=xiTi1′x{_{i1}}' = x{_i}^Ti{_1}'xi1?′=xi?Ti1?′。數據集沿著新的坐標軸i1′i{_1}'i1?′的方差計算如下:
σ=1N∑i=1Nxi1′2=1N∑i=1Nxi1′Txi1′=1N∑i=1Ni1′TxixiTi1′\sigma = \frac{1}{N}\sum_{i=1}^{N}x{_{i1}}'^2 = \frac{1}{N}\sum_{i=1}^{N}x{_{i1}}'^Tx{_{i1}}' = \frac{1}{N}\sum_{i=1}^{N}i{_1}'^Tx_ix_{i}^Ti{_1}' σ=N1?i=1∑N?xi1?′2=N1?i=1∑N?xi1?′Txi1?′=N1?i=1∑N?i1?′Txi?xiT?i1?′
=1Ni1′T(∑i=1NxixiT)i1′= \frac{1}{N}i{_1}'^T (\sum_{i=1}^{N}x_ix_i^T)i{_1}'=N1?i1?′T(i=1∑N?xi?xiT?)i1?′
σ=i1′TΣi1′\sigma = i{_1}'^T\Sigma i{_1}' σ=i1?′TΣi1?′
其中 Σ\SigmaΣ 是協方差矩陣 Σ=1N(∑i=1NxixiT)\Sigma = \frac{1}{N}(\sum_{i=1}^{N}x_ix_i^T)Σ=N1?(i=1∑N?xi?xiT?)
在進行主成分分析時,我們假設某一維度所包含的信息量,與該維度數據的方差是呈正相關的,因此主成分分析問題就轉化成了最大值問題,使用拉格朗日乘數法,找到使方差最大化的剩余維度:
L=i1′TΣi1?λ(i1′Ti1′?1)L = i{_1}'^T \Sigma i_1 - \lambda(i{_1}'^T i{_1}' - 1)L=i1?′TΣi1??λ(i1?′Ti1?′?1)
?L?i1′=0即Σi1′=λi1′\frac{\partial L}{\partial i{_1}'} = 0 即 \Sigma i{_1}' = \lambda {i_1}'?i1?′?L?=0即Σi1?′=λi1?′
其中,i1′i{_1}'i1?′ 和 λ\lambdaλ 分別是數據協方差矩陣的特征向量和對應的特征值。第一個投影維度對應協方差矩陣的第一個特征向量(特征值最大的特征向量)。第二個投影維度對應第二個特征向量以此類推,我們可以得到一組對應特征值遞減的特征向量。通過選出協方差矩陣的前K個特征向量,我們就能選出包含信息量最大的主成分維度,實現對原始數據的降噪,排除掉高維度的干擾,使得后續的數據分析成果更穩定。
Tips : 協方差矩陣是對稱構成的且至少是半正定矩陣,因此其所有的特征向量都是實數,所有的特征值都是正數或0,所有的特征向量互相垂直不相關。









,交易流水記錄的查詢)


,100億數據,1萬字段屬性的秒級檢索)

)




