dataframe是一種表格型的數據存儲結構,可以看作是幾個serie的集合。dataframe既有行索引,也有列索引。
以下代碼環境為google colab/jupyter notebook。
接下來就對dataframe的基本使用進行整理。
dataframe也從屬于pandas模塊,因此還是老規矩,先import pandas。
import pandas as pd
import numpy as np
1. dataframe的創建
dataframe的創建有很多方法,下面列舉了幾種主要的創建方法。
a. 通過numpy ndarray創建dataframe
在創建dataframe時,可以自定義行索引index和列索引columns。
arr = np.random.randn(6,4)
index_rows = pd.date_range('today', periods=6)
index_columns = ['A','B','C','D']
dataframe1 =
pd.DataFrame(arr,index=index_rows,columns=index_columns)
dataframe1
運行結果:

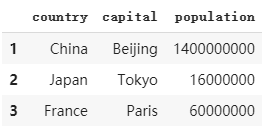
b. 通過字典dictionary創建dataframe
data = {'country': ['China','Japan','France'],'capital': ['Beijing','Tokyo','Paris'],'population' : [1400000000, 16000000, 60000000]}
index = np.array([1,2,3])
dataframe2 = pd.DataFrame(data,index=index)
dataframe2
# 字典中每個鍵對應每一列的列標
運行結果:
2.dataframe的基本操作
a.使用head/tail取dataframe中前n行或后n行
dataframe2.head(2) #使用head取dataframe中的前n行
運行結果 :

dataframe2.tail(2) #使用tail取dataframe中的后n行
運行結果:

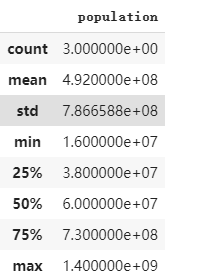
b. 獲取dataframe的統計學屬性
dataframe2.describe()
運行結果 :
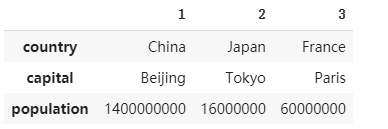
c. 翻轉dataframe的行與列
dataframe2.T
運行結果 :
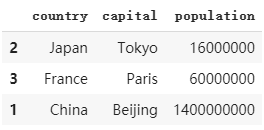
d. 排序
dataframe2.sort_values(by='population') # 升序排列 對一整行都進行移動變換
運行結果 :
e. 切片
dataframe2[0:2] # [0,2)包括前不包括后,例子中就是輸出第0行和第1行
運行結果 :

f. 通過列名tag查詢
dataframe2[['country','population']] #只顯示country和population兩列,如果想要存儲在另外一個dataframe中只需要用賦值語句
運行結果 :
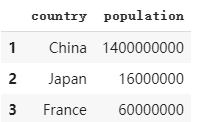
g. 備份dataframe
使用dataframe的copy方法對dataframe進行備份。使用copy方法的好處是,兩個dataframe是完全分開的,改變其中一個的任何屬性都不會對另外一個dataframe造成影響。而如果使用賦值語句進行備份,兩個dataframe實際是完全相連的,任意改變其中一個dataframe的屬性都會對兩者進行同時改變。
例如在下面的例子中,我們使用copy方法,備份dataframe2在dataframe3中并改變dataframe3的行索引,我們會發現dataframe2沒有因此和dataframe3同步變化。
dataframe3 = dataframe2.copy()
dataframe3.index = ['a','b','c']
print(dataframe2)
print(dataframe3)
運行結果:
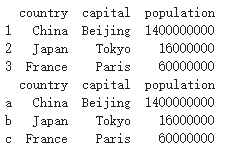
使用賦值語句進行備份,兩個dataframe會進行同步變化。
例如這里我們使用賦值語句后,改變dataframe3的行索引,dataframe2的行索引也同步改變了。
dataframe3 = dataframe2
dataframe3.index = ['a','b','c']
print(dataframe2)
運行結果 :

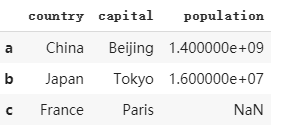
h.使用loc對指定位置的數值進行操作
dataframe3.loc['c','population'] = np.nan #可以對指定位置的數值進行操作
dataframe3
運行結果 :
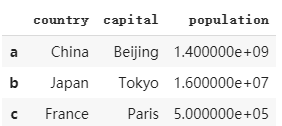
i. 對dataframe中未定義的值進行操作
df4.fillna(500000) # 給所有未定義的數值賦值
運行結果 :
df5 = dataframe3.copy()
df5.dropna(how='any') # 刪除有nan未定義數值的一行
運行結果 :
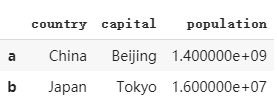
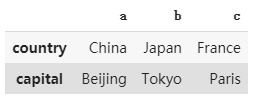
df5 = dataframe3.copy().T # 如果我們transpose翻轉這個dataframe 就會將population這一行整個刪去
df5.dropna(how='any')
運行結果 :
3. dataframe的文件操作
dataframe可以對csv文件,xlsx文件,txt等文件進行讀寫操作。
dataframe3.to_csv('country_count.csv') # 將dataframe寫入csv文件
# 可以在括號中使用絕對路徑調整文件生成的位置 默認位置為當前文件夾下生成
df_country = pd.read_csv('country_count.csv',index_col=None) # 讀取csv文件
dataframe3.to_excel('country_count.xlsx',sheet_name='sheet1')# 將dataframe寫入excel表格
dataframe_fromexcel = pd.read_excel('country_count.xlsx',sheet_name='sheet1',index_col=None)# 讀取excel表格
4. dataframe的可視化
%matplotlib inline
df = pd.DataFrame(np.random.randn(50,4),index=pd.date_range('today',periods=50),columns=['A','B','C','D'])
df.cumsum()
df.plot()
運行結果 :


![[十二省聯考2019]皮配](http://pic.xiahunao.cn/[十二省聯考2019]皮配)










,交易流水記錄的查詢)


,100億數據,1萬字段屬性的秒級檢索)

)

