最近在研究億級數據的時候,無意中看到了一個關于寫58同城的文章
https://blog.csdn.net/admin1973/article/details/55251499?from=timeline
其實上面講的version+ext的方式以及壓縮json的思路,對于我來講都可以看得懂,想得通,其實最感興趣的還是他們那個E-Search架構,然后開始進行實驗和研究其算法。

上圖是從那篇文章里扒出來的圖,是由他們58幾個牛人寫的,并維護的。
按照我的理解一步一步的進行邏輯剖析,有誤的話希望大嬸們及時評論改正。?
分析思路開始:
| tid | uid | time | cateid | ext |
| 1 | 1 | 123 | 招聘 | {"job":"driver","salary":8000,"location":"bj"} |
| 2 | 1 | 345 | 房產 | {"rent":1000,"location":"dl","acreage":120} |
| 3 | 1 | 567 | 二手 | {"type":"iphone","money",200} |
這個是文章里提到的數據表結構,ext存這比較多可擴展的屬性。然后E-Search就是要對這些屬性進行快速的查詢搜索。
里面提到了Searcher1?Searcher2,就是一個個用于建立索引用的表。
比如房產:
?

房產現在里面有三個字段,每一個字段對應一張表或多張表,因為字段數據到一定數量的時候,可能單臺服務器的存儲空間不夠了,所以需要分庫分表。分表可以按照Hash算法,然后切割成單臺服務器可以容下的數量范圍,在超過一定冗余范圍,就要增加一臺冗余服務器,繼續分庫分表。上面的例子,按照每張表存儲100萬數據的方式存儲。
里面提到merger服務,合并層,并且強調了,增加機器就可以擴容,同時也說明了服務啟動時可以加載索引數據到內存,請求訪問時從內存中load數據,訪問速度很快。
那這個merger要做些什么呢?應該怎么做呢?
好了,現在分析業務需求,咱們模擬一個場景和一個查詢需求,分析一下整體是怎么工作的。
在看了58同城網站時候,發現了幾個特點。
一、有分頁,但是沒有一共多少條的分析和統計

二、檢索條件是可以隨意的設定,有很多的條件可以進行添加

然后我們沿著我們的表設計開始進行模擬一個搜索過程。
那么,我們假設幾個查詢條件
價格:1700~2500
地址:大連 (dl)
面積:190平米以內
按照價格從低到高進行排序
分頁每頁10條
按照以上的查詢條件,我們分別在這六張表上進行搜索。
租金:Table1 2000條,Table2 500條,一共2500條
地址:Table3?999993條,Table4 8條,一共 1000001條
面積:Table5 5000條
下一步,當然就要把這些條件查詢的結果進行合并,就是所謂的merger要做的事。
首先,要知道排序要用價格從低到高進行排序,我們知道查詢結果就是按照索引進行排序好的排序文件,大小就是12345這樣從低到高進行索引的。那就從Table1開始循環,因為是and關系,只要數據既符合地址的條件,又符合面積的條件,就算合格一條,只要累積滿足了10條,就可以返回了。這個時候,其他的條件加載在內存里,但怎么比較比較快呢?
這時候,就涉及到Hash算法了,比如Java有個HashMap,我們可以把其他數據全部加載到HashMap里,然后Table1每循環一次要用containsKey方法,與其他的表進行確認一下是否存在,由于Hash算法速度很快,就可以很快的湊出來前10條。
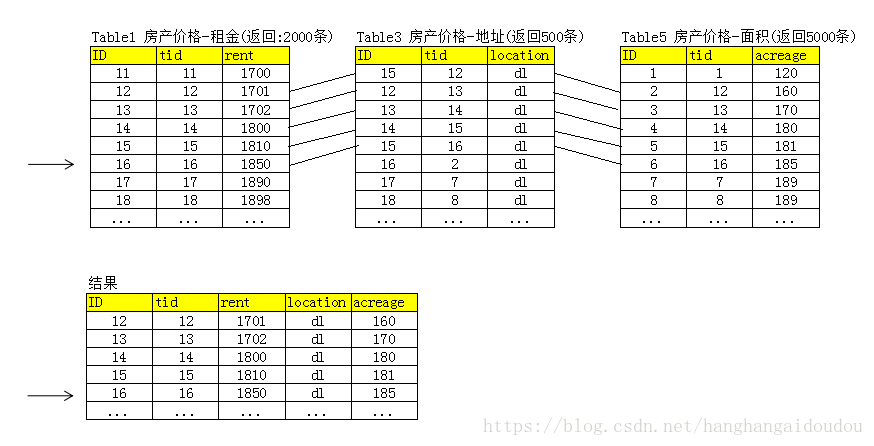
這個時候,第一頁的結果就完成了。
那么,就要問了,第二頁,第三頁,第四頁怎么辦?
在我們循環Table1的時候,會有一個循環的游標位置,index,比如湊了10條,游標游到了25才湊齊返回,那我們就把這個25一同返回,作為下一頁的起點。
由于系統不需要統計一共查詢多少結果,所以我們依次往下迭代就可以了。
前臺得到了25這個游標,那么,下一頁直接從Table1結果25在往后開始循環尋找條件符合的數據,湊成10條,并且返回index ,依次往后進行。
?
其他問題總結:
一、索引表冗余問題
就像那個文章所說的,系統不要求一致性,所以每次有新的數據插入,在插入Ext表之后,分別給到searcher的索引表里,進行更新索引,當某個字段索引表空間不夠了,增加冗余服務器,進行切分數據以保證重建索引速度及存放空間能力。
二、merger服務冗余問題
由于merger服務與索引表在同一服務器上,當表控件需要增加的時候,merger服務也隨著增加,同時要保證這臺服務器的內存能夠可以實現單表最大數據存儲計算能力。
三、EXT數據的冗余問題
直接就按照UID的增加,如果單臺服務器不夠,直接增加
四、100億數據導入問題
有個100億的數據問題,要求從Oracle數據庫導入到MySql下。要求原系統不能停,還要求最后的數據是一致的。這個思路就是,把MySql進行分庫分表規劃好后,進行導數據,并且業務系統在不停的情況下產生的新的操作,同時更新Oracle和MySql,最后就可以實現兩個庫的一致性。?

)
















)
