Hidden Markov Model, HMM 隱馬爾可夫模型,是一種描述隱性變量(狀態)和顯性變量(觀測狀態)之間關系的模型。該模型遵循兩個假設,隱性狀態i只取決于前一個隱性狀態i-1,而與其他先前的隱形狀態無關。觀測狀態也只取決于當前的隱形狀態。因此我們常常將隱馬爾科夫模型表現為一種如下圖所示鏈式的模型。
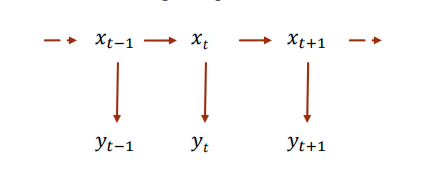
其中,xtx_txt?代表某一時刻的隱形狀態鏈,其N個狀態取值集合為{s1,s2,s3,...,N}\{s_1,s_2,s_3,...,_N\}{s1?,s2?,s3?,...,N?}。yty_tyt?表示為對應的該時刻的顯性狀態(觀測狀態),其M個狀態取值集合為{o1,o2,o3,...,ok,...,oM}\{o_1,o_2,o_3,...,o_k,...,o_M\}{o1?,o2?,o3?,...,ok?,...,oM?}。隱馬爾科夫模型θ\thetaθ可以由三個矩陣來進行描述θ=(A,B,Π)\theta = (A,B,\Pi)θ=(A,B,Π)。
1. 大小為 N*N (N代表N種隱性的狀態)的過渡矩陣 A:
A={aij}={P(xt+1=sj∣xt=si)}={P(sj∣si)}A = \{a_{ij}\} = \{P(x_{t+1}=s_j|x_t=s_i)\} = \{P(s_j|s_i)\}A={aij?}={P(xt+1?=sj?∣xt?=si?)}={P(sj?∣si?)}
過渡矩陣A中的每一個元素表示由上一個隱性狀態sis_isi?變為下一個隱性狀態的條件概率。
2. 大小為 1*N 的初始概率向量 Π\PiΠ :
Π=πi=P(x1=si)=P(si)\Pi ={\pi_i} = {P(x_1 = s_i)} = {P(s_i)}Π=πi?=P(x1?=si?)=P(si?)
初始概率向量Π\PiΠ中的每一個元素,表示初始隱性狀態為sis_isi?的概率,該向量的長度N與隱性狀態的可能取值個數相同。
3. 大小為 M*N 的觀測矩陣 B :
B={bki}={P(yt=ok∣xt=si)}={P(ok∣si)}B = \{b_{ki}\} = \{P(y_t=o_k|x_t=s_i)\} = \{P(o_k|s_i)\} B={bki?}={P(yt?=ok?∣xt?=si?)}={P(ok?∣si?)}
觀測矩陣B中的每個元素,是用來描述N個隱形狀態對應M個觀測狀態的概率。即在隱形狀態為sis_isi? 的條件下,觀測狀態為oko_kok?的概率。
上述三個矩陣構成了一個完整的隱馬爾可夫模型。
擲骰子問題可以幫助我們更好地理解顯性狀態鏈和隱性狀態鏈。例如我們有三個面數不一樣的骰子可供選擇投擲,三個骰子一個面數為4,一個面數為6,一個面數為8。每次選擇的骰子是隨機的且滿足繼續選到同一個骰子的概率是選到其他骰子概率的兩倍。此時,隱性狀態鏈xtx_txt?就是我們每次選擇的骰子,取值集合就是骰子1,骰子2,骰子3。顯性狀態鏈就是我們擲出的一系列數值,取值集合為{1,2,3,4,5,6,7,8}\{1,2,3,4,5,6,7,8\}{1,2,3,4,5,6,7,8}。
根據上述的信息,我們不難整理出這個骰子問題HMM模型的三個核心矩陣 :
過渡矩陣A
| previous state \ current state | D4 | D6 | D8 |
|---|---|---|---|
| D4 | 23\frac{2}{3}32? | 16\frac{1}{6}61? | 16\frac{1}{6}61? |
| D6 | 16\frac{1}{6}61? | 23\frac{2}{3}32? | 16\frac{1}{6}61? |
| D8 | 16\frac{1}{6}61? | 16\frac{1}{6}61? | 23\frac{2}{3}32? |
初始概率向量Π\PiΠ
由于一開始是隨機選取骰子,因此初始抽到三個骰子的概率是相同的13\frac{1}{3}31?。
| D4 | D6 | D8 |
|---|---|---|
| 13\frac{1}{3}31? | 13\frac{1}{3}31? | 13\frac{1}{3}31? |
觀測矩陣B :
觀測矩陣存放了每種隱性狀態下各觀測狀態的條件概率
| observed state \ hidden state | D4 | D6 | D8 |
|---|---|---|---|
| 1 | 14\frac{1}{4}41? | 16\frac{1}{6}61? | 18\frac{1}{8}81? |
| 2 | 14\frac{1}{4}41? | 16\frac{1}{6}61? | 18\frac{1}{8}81? |
| 3 | 14\frac{1}{4}41? | 16\frac{1}{6}61? | 18\frac{1}{8}81? |
| 4 | 14\frac{1}{4}41? | 16\frac{1}{6}61? | 18\frac{1}{8}81? |
| 5 | 0 | 16\frac{1}{6}61? | 18\frac{1}{8}81? |
| 6 | 0 | 16\frac{1}{6}61? | 18\frac{1}{8}81? |
| 7 | 0 | 0 | 18\frac{1}{8}81? |
| 8 | 0 | 0 | 18\frac{1}{8}81? |
使用HMM模型會衍生出三類基礎問題 :
第一類問題. 在HMM模型θ\thetaθ確定的情況下,針對一組顯性狀態鏈y1:Ty_{1:T}y1:T?,計算出該模型生成這組顯性狀態鏈的概率。
還是沿用上述的骰子為例,這類問題實際就是在確定了骰子的種類,D4D6D8(觀測矩陣B),隨機選擇骰子的方式(過渡矩陣A和初始概率向量Π\PiΠ)的情況下,用于計算使用這三個骰子擲出一組數的可能性的問題。計算顯性狀態鏈的生成概率也是對模型是否和實際情況吻合的檢驗。如果多次實驗得出的顯性狀態鏈由該模型生成的概率很低,可以認為構成模型的三個矩陣要素可能與實際情況不符,即在該例子中使用的骰子有被掉包的可能或實際隨機選取骰子的方式與模型不一致。下面給出計算該問題的其中一個算法 forward algorithm 前向算法,與之對應的還有backward algorithm 后向算法,由于兩者的思路很相似,本文中不再對backward algorithm作過多闡述。
forward algorithm 前向算法
計算一組顯性狀態鏈 y1,y2,y3,...,yTy_1,y_2,y_3,...,y_Ty1?,y2?,y3?,...,yT? (下文中統一稱y1:Ty_{1:T}y1:T?)生成的概率,即計算 𝔏 = P(y1:T)P(y_{1:T})P(y1:T?)。我們先定義 αi(t)=P(y1:t,xt=si)\alpha_i(t) = P(y_{1:t}, x_t = s_i)αi?(t)=P(y1:t?,xt?=si?), 其中sis_isi?是該顯性狀態鏈最后一個值對應的隱性狀態,ttt是這個顯性狀態鏈的總長度。 αi(t)\alpha_i(t)αi?(t)即是擲出該顯性狀態鏈,且最后一個隱形狀態為sis_isi?的概率,則最終要求的生成概率 𝔏 = P(y1:T)=P(y1:T,xt=s1)+P(y1:T,xt=s2)+...+P(y1:T,xt=sN)=∑i=1Nαi(T)P(y_{1:T}) = P(y_{1:T},x_t = s_1) + P(y_{1:T},x_t = s_2) +... + P(y_{1:T},x_t = s_N) \\ = \sum_{i=1}^{N}\alpha_i{(T)}P(y1:T?)=P(y1:T?,xt?=s1?)+P(y1:T?,xt?=s2?)+...+P(y1:T?,xt?=sN?)=i=1∑N?αi?(T)
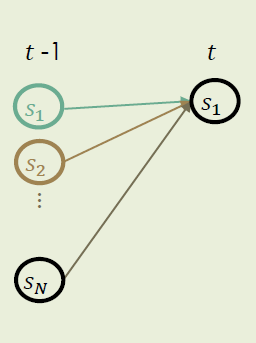
這樣我們就把問題轉化為了計算αi(T)=P(y1:T,xt=si)\alpha_i{(T)} = P(y_{1:T},x_t=s_i)αi?(T)=P(y1:T?,xt?=si?)。使用前向算法forward algorithm如下圖所示,通過去掉最后一個狀態的狀態鏈的生成概率αi(t?1)\alpha_i(t-1)αi?(t?1)推導至αi(t)\alpha_i{(t)}αi?(t),可以歸納為一個遞推模型。
首先我們計算生成y1:ty_{1:t}y1:t?這個顯性狀態鏈且最后一個隱形狀態為s1s_1s1?的概率α1(t)\alpha_1(t)α1?(t),通過這個概率我們就不難推導出同樣生成該顯性狀態鏈,且最后一個隱性狀態為s2,s3,...,sNs_2,s_3,...,s_Ns2?,s3?,...,sN?的概率αi(t)\alpha_i(t)αi?(t)。
α1(t)=P(y1:t,xt=si)=P(y1:t?1,xt?1=s1)?P(s1∣s1)?P(yt∣s1)+P(y1:t?1,xt?1=s2)?P(s1∣s2)?P(yt∣s1)+...+P(y1:t?1,xt?1=xN)?P(s1∣sN)?P(yt∣s1)\alpha_1{(t)} = P(y_{1:t},x_t = s_i) = P(y_{1:t-1},x_{t-1}=s_1) * P(s_1|s_1) * P(y_t|s_1) \\ + P(y_{1:t-1},x_{t-1}=s_2) * P(s_1|s_2) * P(y_t|s_1) \\+ \\...\\+ P(y_{1:t-1},x_{t-1}=x_N) * P(s_1|s_N) * P(y_t|s_1)α1?(t)=P(y1:t?,xt?=si?)=P(y1:t?1?,xt?1?=s1?)?P(s1?∣s1?)?P(yt?∣s1?)+P(y1:t?1?,xt?1?=s2?)?P(s1?∣s2?)?P(yt?∣s1?)+...+P(y1:t?1?,xt?1?=xN?)?P(s1?∣sN?)?P(yt?∣s1?)
對于每個前置狀態xt?1x_{t-1}xt?1?,計算α1(t)\alpha_1(t)α1?(t)為三個概率的乘積 : 前一時刻t?1t-1t?1隱形狀態為sis_isi?且狀態鏈為y1:t?1y_{1:t-1}y1:t?1?的概率,由前一時刻的隱形狀態sis_isi?過渡到當前時刻s1s_1s1?的過渡概率,以及在隱性狀態為s1s_1s1?的情況下,顯性狀態呈現yty_tyt?的概率。
整理可得 :
α1(t)=α1(t?1)?a11?byt,1+α2(t?1)?a21?byt,1+...+αN(t?1)?aN1?byt,1=byt,1∑k=1Nαk(t?1)?ak1\alpha_1(t) = \alpha_1(t-1) * a_{11} * b_{yt,1} \\+\\ \alpha_2(t-1)*a_{21} * b_{yt,1} \\+\\ ... \\+\\ \alpha_N(t-1) * a_{N1} * b_{yt,1} \\= b_{yt,1}\sum_{k=1}^N\alpha_k(t-1) * a_{k1}α1?(t)=α1?(t?1)?a11??byt,1?+α2?(t?1)?a21??byt,1?+...+αN?(t?1)?aN1??byt,1?=byt,1?k=1∑N?αk?(t?1)?ak1?
tips : aija_{ij}aij?是過渡矩陣A中第i行第j列元素,aij=P(xt?1=sj∣xt=si)a_{ij} = P(x_{t-1}=s_j|x_t=s_i)aij?=P(xt?1?=sj?∣xt?=si?)即由前一個隱形狀態sis_isi?過渡到現狀態sjs_jsj?的概率。
同理可得α2(t)=byt,2∑k=1Nαk(t?1)?ak2\alpha_2(t) = b_{yt,2}\sum_{k=1}^N\alpha_k(t-1) * a_{k2}α2?(t)=byt,2?k=1∑N?αk?(t?1)?ak2?
不難推出αi(t)=byt,i∑k=1Nαk(t?1)?akifor(t>=2)\alpha_i(t) = b_{yt,i}\sum_{k=1}^N\alpha_k(t-1) * a_{ki} \space \space for (t>=2)αi?(t)=byt,i?k=1∑N?αk?(t?1)?aki???for(t>=2)
我們就得到了一個計算αi(t)\alpha_i(t)αi?(t)的遞推模型,初始值αi(1)=πi?by1,i\alpha_i(1) = \pi_i*b_{y_{1},i}αi?(1)=πi??by1?,i? tips : πi\pi_iπi?是初始隱性狀態為i的概率(見初始概率向量Π\PiΠ)。
且𝔏 = P(y1:T)=P(y1:T,xt=s1)+P(y1:T,xt=s2)+...+P(y1:T,xt=sN)=∑i=1Nαi(T)P(y_{1:T}) = P(y_{1:T},x_t = s_1) + P(y_{1:T},x_t = s_2) +... + P(y_{1:T},x_t = s_N) \\ = \sum_{i=1}^{N}\alpha_i{(T)}P(y1:T?)=P(y1:T?,xt?=s1?)+P(y1:T?,xt?=s2?)+...+P(y1:T?,xt?=sN?)=i=1∑N?αi?(T)易得P(y1:T)=∑i=1N(byT,1∑k=1Nαk(T?1)?ak1)for(T>=2)P(y_{1:T} ) = \sum_{i=1}^N(b_{y_{T,1}}\sum_{k=1}^N\alpha_k(T-1) * a_{k1}) \space\space for (\space T>=2)P(y1:T?)=i=1∑N?(byT,1??k=1∑N?αk?(T?1)?ak1?)??for(?T>=2)
第二類問題. 在HMM模型θ\thetaθ確定的情況下,給出一組顯性狀態鏈y1:Ty_{1:T}y1:T?,找出與其對應的可能性最大 的隱性狀態序列x1:Tx_{1:T}x1:T?。
這個問題廣泛應用于自然語言處理NLP中。例如在我們獲取了一組手寫符號時,找出其最大概率對應的字符。解決這個問題我們就要用到viterbi algorithm 維特比算法。維特比算法仍然利用遞推關系,由ttt時刻的狀態推出t+1t+1t+1時刻的狀態。定義δi(t)\delta_i(t)δi?(t)為ttt時刻且顯性狀態為sis_isi?的最優路徑的概率。
初始情況非常簡單,在t=1t=1t=1時刻,δi(t)=πi?by1,i\delta_i(t) = \pi_i * b_{y_1,i}δi?(t)=πi??by1?,i?,每個隱性狀態對應的概率均是初始狀態概率與對應的顯性狀態觀測概率的乘積。緊接著有遞推關系 :
δi(t+1)=[max?jδj(t)aji]?byt+1,i\delta_i(t+1) = [\max_j\delta_j(t)a_{ji}] * b_{y_{t+1},i}δi?(t+1)=[jmax?δj?(t)aji?]?byt+1?,i?在這個遞推關系中,下一時刻t+1t+1t+1每個隱性狀態iii的最大概率δi(t+1)\delta_i(t+1)δi?(t+1)總是對應上一時刻ttt中最優路徑概率δj(t)\delta_j(t)δj?(t)與過渡概率ajia_{ji}aji?乘積最大的隱性狀態jjj。因此,最優的隱性狀態路徑序列$\Psi_i(t) = [\argmax_j\delta_i(t)a_{ji}]。下面引用索邦大學課件上的例題作為使用維特比算法的例子 :
給定一個HMM模型θ\thetaθ,其中
A=∣0.30.50.200.30.7001∣A = \left| \begin{matrix} 0.3 & 0.5 & 0.2\\ 0 & 0.3 & 0.7\\ 0 & 0 & 1 \end{matrix} \right| A=∣∣∣∣∣∣?0.300?0.50.30?0.20.71?∣∣∣∣∣∣?
Π=∣0.60.40∣\Pi = \left| \begin{matrix} 0.6\\ 0.4 \\ 0 \end{matrix} \right| Π=∣∣∣∣∣∣?0.60.40?∣∣∣∣∣∣?
B=∣10.5000.51∣B = \left| \begin{matrix} 1 & 0.5 & 0\\ 0 & 0.5 & 1 \end{matrix} \right| B=∣∣∣∣?10?0.50.5?01?∣∣∣∣?
計算顯性序列為 y = [1,1,2,2] 時,對應可能性最大的隱性序列。
結果如下 :
最終的最大概率隱性狀態鏈為[1 2 3 3],對應的概率為0.105。

第三類問題. Baum-Welch算法,給定一個序列y1:Ty_{1:T}y1:T?,估算出能最大化該序列生成概率的HMM模型的參數。
這類問題是非常常見的,HMM建模的問題。通過一組給定的顯性狀態鏈,推測出可能性最大的HMM模型。 首先我們需要用到前向算法中提到的αi(t)\alpha_i(t)αi?(t)以及后向算法中的βi(t)\beta_i(t)βi?(t)。前向算法的推導過程可以參考之前的部分,類似的后向算法如果有興趣可以自行再查找資料,這里不過多贅述只列出使用的公式。
根據之前前向算法部分,我們定義了αi(t)=P(y1:t,xt=si)\alpha_i(t) = P(y_{1:t}, x_t = s_i)αi?(t)=P(y1:t?,xt?=si?)這個可以遞推出的概率,αi(t)\alpha_i(t)αi?(t)代表了觀測狀態為y1:ty_{1:t}y1:t?且第ttt個隱性狀態sis_isi?的概率。同樣在后向算法中我們定義了βi(t)=P(yt+1,...,yT,xt=si)\beta_i(t) =P(y_{t+1},...,y_T, x_t=s_i)βi?(t)=P(yt+1?,...,yT?,xt?=si?)代表了觀測狀態為yt+1:Ty_{t+1:T}yt+1:T?且第ttt個隱性狀態為sis_isi?的概率。
顯然我們有αi(t)βi(t)=P(y1:T,xt=si)\alpha_i(t)\beta_i(t)=P(y_{1:T},x_t=s_i)αi?(t)βi?(t)=P(y1:T?,xt?=si?) 且 𝔏 = P(y1:T)P(y_{1:T})P(y1:T?)。
根據貝葉斯公式P(A∣B)=P(A,B)P(B)P(A|B) = \frac{P(A,B)}{P(B)}P(A∣B)=P(B)P(A,B)?, [2] 我們不難得出在給定觀測序列y1:Ty_{1:T}y1:T?以及HMM模型θ\thetaθ的情況下,在ttt時刻狀態是sis_isi?的概率 :
γi(t)=P(xt=si∣y1:T)=P(xt=si,y1:T)P(y1:T)=αi(t)βi(t)∑j=1Nαj(t)βj(t)\gamma_i(t) = P(x_t=s_i|y_{1:T}) = \frac{P(x_t=s_i,y_{1:T})}{P(y_{1:T})}=\frac{\alpha_i(t)\beta_i(t)}{\sum_{j=1}^{N}\alpha_j(t)\beta_j(t)}γi?(t)=P(xt?=si?∣y1:T?)=P(y1:T?)P(xt?=si?,y1:T?)?=∑j=1N?αj?(t)βj?(t)αi?(t)βi?(t)?
在ttt時刻狀態是sis_isi?,在t+1t+1t+1時刻狀態時sjs_jsj?的概率 :
ξij=P(xt=si,xt+1=sj∣y1:T)=P(sj∣si)αi(t)βj(t+1)P(yt+1∣sj)P(y1:T)=aijβj(t+1)byt+1,jP(y1:T)\xi_{ij} =P(x_t=s_i,x_{t+1} =s_j|y_{1:T}) = \frac{P(s_j|s_i)\alpha_i(t)\beta_j(t+1)P(y_{t+1}|s_j)}{P(y_{1:T})} = \frac{a_{ij}\beta_j(t+1)b_{y_{t+1},j}}{P(y_{1:T})}ξij?=P(xt?=si?,xt+1?=sj?∣y1:T?)=P(y1:T?)P(sj?∣si?)αi?(t)βj?(t+1)P(yt+1?∣sj?)?=P(y1:T?)aij?βj?(t+1)byt+1?,j??
通過這些基礎的概率,我們更新θ\thetaθ中的參數。
初始狀態是sis_isi?的概率向量:
Πi?=γi(1)\Pi^*_i = \gamma_i(1)Πi??=γi?(1)
更新過渡矩陣:
aij?=P(sj∣si)=∑t=1T?1ξij(t)∑t=1T?1γi(t)a^*_{ij} = P(s_j|s_i) = \frac{\sum_{t=1}^{T-1}\xi_{ij}(t)}{\sum_{t=1}^{T-1}\gamma_{i}(t)}aij??=P(sj?∣si?)=∑t=1T?1?γi?(t)∑t=1T?1?ξij?(t)?
更新觀測矩陣:
bok,i?=∑t=1Tαi(t)P(yt∣si)1yt=ok∑t=1Tαi(t)βi(t)b^*_{o_k,i} = \frac{\sum_{t=1}^T\alpha_i(t)P(y_t|s_i)1_{y_t=o_k}}{\sum_{t=1}^T\alpha_i(t)\beta_i(t)}bok?,i??=∑t=1T?αi?(t)βi?(t)∑t=1T?αi?(t)P(yt?∣si?)1yt?=ok???
其中
1yt=ok=1whenyt=ok1_{y_t=o_k} = 1 \space\space when \space \space y_t=o_k1yt?=ok??=1??when??yt?=ok?
1yt=ok=0whenelse1_{y_t=o_k} = 0 \space\space when \space \space else1yt?=ok??=0??when??else
不斷重復上述更新操作直至收斂,就得到了新的HMM模型。
\newline
\newline
\newline
\newline
\newline
References :
[1] Viterbi AJ (April 1967). “Error bounds for convolutional codes and an asymptotically optimum decoding algorithm”. IEEE Transactions on Information Theory. 13
[2] Baum-Welch algorithm






,交易流水記錄的查詢)


,100億數據,1萬字段屬性的秒級檢索)

)







