大數據概述
數據的表現形式:
- 線下數據信息化:數據庫、文字記錄、照片……
- 互聯網-移動互聯網:網頁數據、用戶行為記錄、數字圖像……
- 傳感器:設備監控、智能家居、攝像頭……
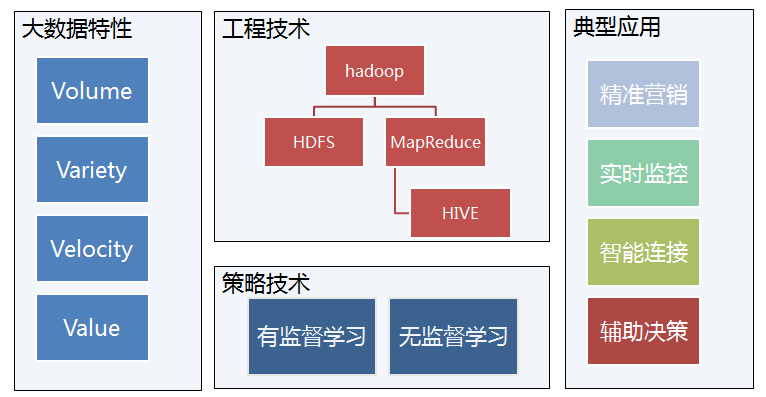
大數據的4V特征:
- 大量化(Volume):存儲量大、增量大;
- 多樣化(Variety):來源多、格式多;
- 快速化(Velocity):高速數據I/O;
- 價值密度低(Value)
大數據基礎技術
一、工程技術
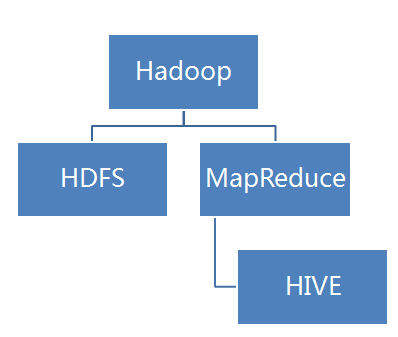
Hadoop介紹
Hadoop是一個能夠對大量數據進行分布式處理的軟件框架。
Hadoop的框架最核心的設計就是:HDFS和MapReduce。HDFS 實現存儲,而 MapReduce實現分析處理。
| 關系型數據庫 | Hadoop | |
|---|---|---|
| 數據量 | GB | PB |
| 使用場景 | 點查詢或更新 | 整個數據集,一次寫多次讀,沒有更新 |
| 結構化程度 | 結構化 | 半結構化及非結構化 |
| 擴展性 | 線性 | 非線性 |
Hadoop和網格計算的區別:
網格計算:CPU密集型,各個處理單元接收小批量數據,然后貢獻CPU,最后提交計算結果;
Hadoop:數據本地化,傳輸數據量較大,對網絡帶寬要求較高。
HDFS(Hadoop Distributed File System)基本命令:
%hadoop fs -ls .
%hadoop fs -mkdir books
%hadoop fs -copyFromLocal input/docs/test.txt hdfs://loca1host/user/tom/test.txt
HDFS特點
1.流式訪問:
跑在HDFS上的應用與一般的應用不同,它們主要是以流式讀為主,做批量處理;比之關注數據訪問的低延遲問題,更關鍵的在于數據訪問的高吞吐量。
2.write-one-read-many
一個文件經過創建、寫,關閉之后就不需要改變。這一假設簡化了數據一致性問題,使高吞吐量的數據訪問成為可能。
3.本地計算
移動計算的代價比之移動數據的代價低。一個應用請求的計算,離它操作的數據越近就越高效。將計算移動到數據附近,比之將數據移動到應用所在顯然更好,HDFS提供給應用這樣的接口。
4.容錯及備份
Hadoop有健壯的數據校驗+容災備份。通過配置解決
HIVE
定義:一個構建在Hadoop上的數據倉庫框架。
目的: 可以通過類SQL語句快速實現簡單的MapReduce統計,使熟悉SQL的用戶無縫使用Hadoop。
特點:語法基本和MySQL相同,但是功能沒有MySQL豐富,滿足最基本的SQL語法要求。
HIVE的實現邏輯
select year,count(temperature)
from src
where year>1990
group by year
having count(temperature)>1000;
這個sql的語義是:
1)(map)從src表中選出所有的記錄,選出year>1990的記錄;
2)(partition and shuffle)按照year進行分組(year相同的記錄放到一組);
3)(reduce)對每個分組計算count(temperature),選出count(temperature)>1000的記錄;
4)最后對于計算結果選出year和count(temperature)的值作為返回結果
小結:
二、策略技術
機器學習中經典算法和對應問題
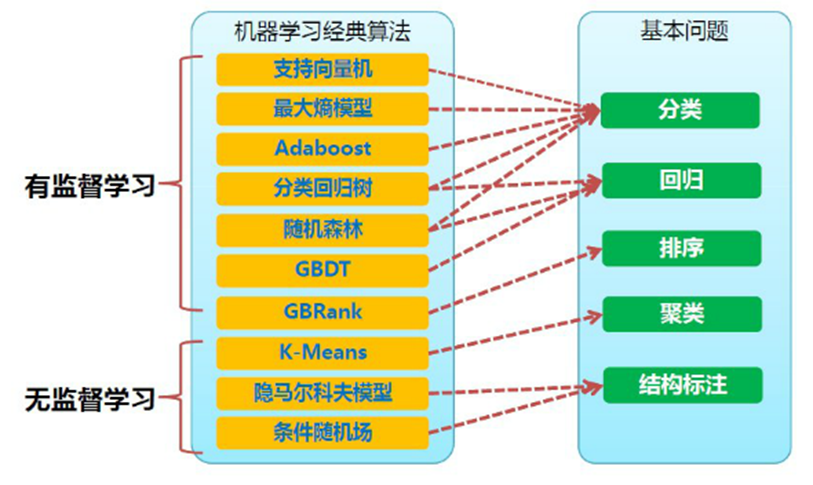
有監督學習:對具有概念標記(分類)的訓練樣本進行學習,以盡可能對訓練樣本集外的數據進行標記(分類)預測。這里,所有的標記(分類)是已知的。無監督學習:對沒有概念標記(分類)的訓練樣本進行學習,以發現訓練樣本集中的結構性知識。這里,所有的標記(分類)是未知的。因此,訓練樣本的岐義性高。聚類就是典型的無監督學習
定量輸出稱為回歸,或者說是連續變量預測;定性輸出稱為分類,或者說是離散變量預測。
典型應用
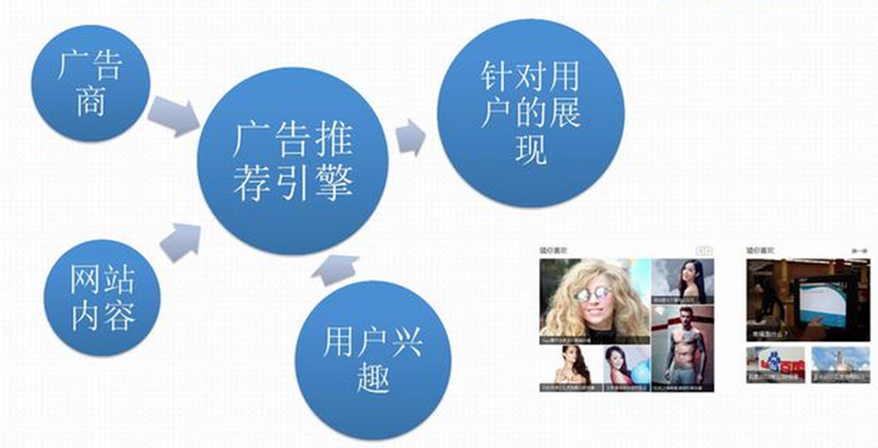
- 精準營銷:廣告變現
- 精準營銷:推薦引擎
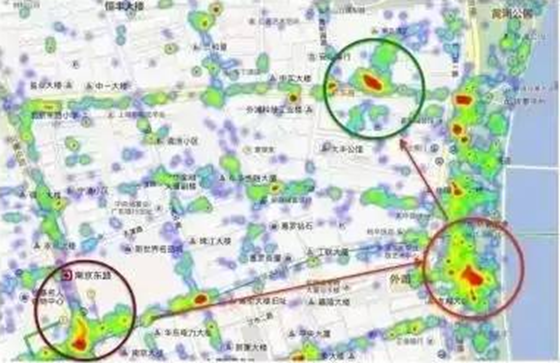
- 實時監控:上海外灘踩踏事件
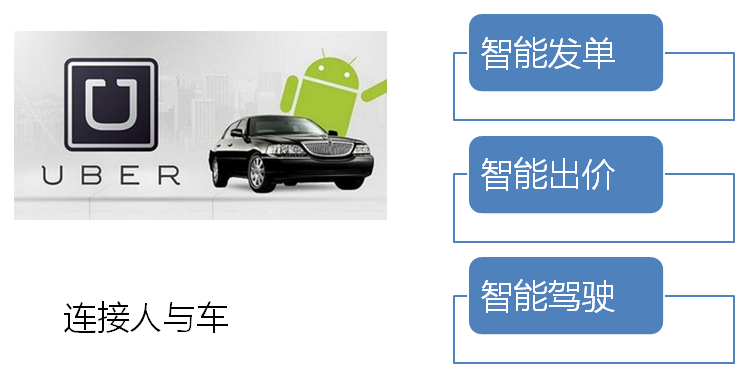
- 智能鏈接:互聯網+O2O
- 智能鏈接:互聯網+O2O:Uber
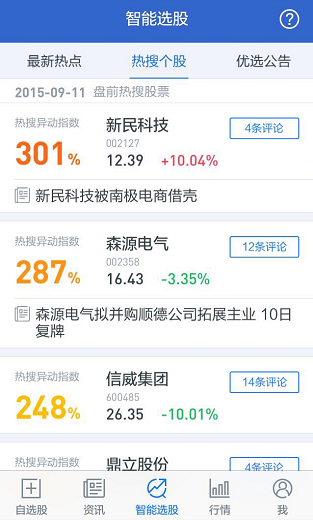
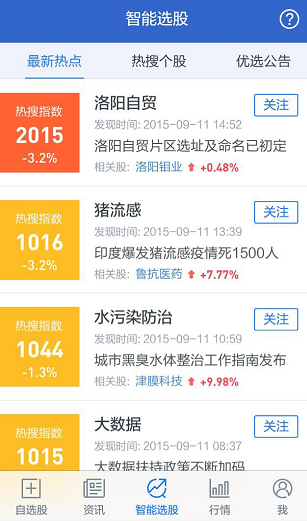
- 輔助決策:智能選股
- 輔助決策:智能選址

總結
本文參考自牛客網。



















