前言
今天剛好有空,跟大家聊聊如何學好算法進大廠。
前兩天一個讀者和我說,他堅持刷算法題2個月,薪資翻番去了他夢寐以求的大廠,期間面字節跳動還遇到了原題…其實據我所知目前國內的大廠和一些獨角獸,已經越來越效仿硅谷公司的做法,通過編程定題面試,來考察數據結構和算法的扎實程度。
以我的經驗來說,**對于新手來說,扎實的掌握一門語言是其一,其二就是要有基本的算法能力,這個非常重要。對于進階的用戶,更多技術棧的掌握就是必須的了。另外,還需要你學習高階算法,掌握這些技術棧匹配的算法技能。**現在很多大廠技術面試的要求是:技術要好,計算機基礎扎實,熟練掌握算法和數據結構,語言不重要,熟練度很重要。每一輪技術面試不只考算法,但一定會考算法。
為什么這幾年算法成了其中必要的一個環節?因為考察算法的核心就是,看候選人是不是足夠聰明!很多大廠的算法面試題一般對應的是 LeetCode 中級模式,一般會直接讓你說思路或上手寫代碼。
要通過面試,你肯定得花時間好好準備。但是只靠刷題去提升算法能力,進度太慢,而且還容易抓不住重點很難堅持,并且沒有完整的學習體系,也沒人指導,導致最后的結果就是一知半解,浪費了大量的時間成本。
正文
在寫這個文章之前,我花了點時間,自己臆想了一個電商系統,基本上算是麻雀雖小五臟俱全,我今天就用它開刀,一步步剖析,我會講一下我們可能會接觸的技術棧可能不全,但是夠用,最后給個學習路線。
Tip:請多欣賞一會,每個點看一下,看看什么地方是你接觸過的,什么技術棧是你不太熟悉的,我覺得還算是比較全的,有什么建議也可以留言給我。

不知道大家都看了一下沒,現在我們就要庖丁解牛了,我從上到下依次分析。
前端
你可能會會好奇,你不是講后端學習路線嘛,為啥還有前端的部分,我只能告訴你,傻瓜,膚淺。
我們可不能閉門造車,誰告訴你后端就不學點前端了?
前端現在很多也了解后端的技術棧的,你想我們去一個網站,最先接觸的,最先看到的是啥?
沒錯就是前端,在大學你要是找不到專門的前端同學,去做系統肯定也要自己頂一下前端的,那我覺得最基本的技術棧得熟悉和了解吧,丙丙現在也是偶爾會開發一下我們的管理系統主要是VUE和React。
在這里我列舉了我目前覺得比較簡單和我們后端可以了解的技術棧,都是比較基礎的。
作為一名后端了解部分前端知識還是很有必要的,在以后開發的時候,公司有前端那能幫助你前后端聯調更順暢,如果沒前端你自己也能頂一下簡單的頁面。
HTML、CSS、JS、Ajax我覺得是必須掌握的點,看著簡單其實深究或者去操作的話還是有很多東西的,其他作為擴展有興趣可以了解,反正入門簡單,只是精通很難很難。
在這一層不光有這些還有Http協議和Servlet,request、response、cookie、session這些也會伴隨你整個技術生涯,理解他們對后面的你肯定有不少好處。

Tip:我這里最后刪除了JSP相關的技術,我個人覺得沒必要學了,很多公司除了老項目之外,新項目都不會使用那些技術了。
前端在我看來比后端難,技術迭代比較快,知識好像也沒特定的體系,所以面試大廠的前端很多朋友都說難,不是技術多難,而是知識多且復雜,找不到一個完整的體系,相比之下后端明朗很多,我后面就開始講后端了。
網關層:
互聯網發展到現在,涌現了很多互聯網公司,技術更新迭代了很多個版本,從早期的單機時代,到現在超大規模的互聯網時代,幾億人參與的春運,幾千億成交規模的雙十一,無數互聯網前輩的造就了現在互聯網的輝煌。
微服務,分布式,負載均衡等我們經常提到的這些名詞都是這些技術在場景背后支撐。
單機頂不住,我們就多找點服務器,但是怎么將流量均勻的打到這些服務器上呢?
負載均衡,LVS
我們機器都是IP訪問的,那怎么通過我們申請的域名去請求到服務器呢?
DNS
大家刷的抖音,B站,快手等等視頻服務商,是怎么保證同時為全國的用戶提供快速的體驗?
CDN
我們這么多系統和服務,還有這么多中間件的調度怎么去管理調度等等?
zk
這么多的服務器,怎么對外統一訪問呢,就可能需要知道反向代理的服務器。
Nginx
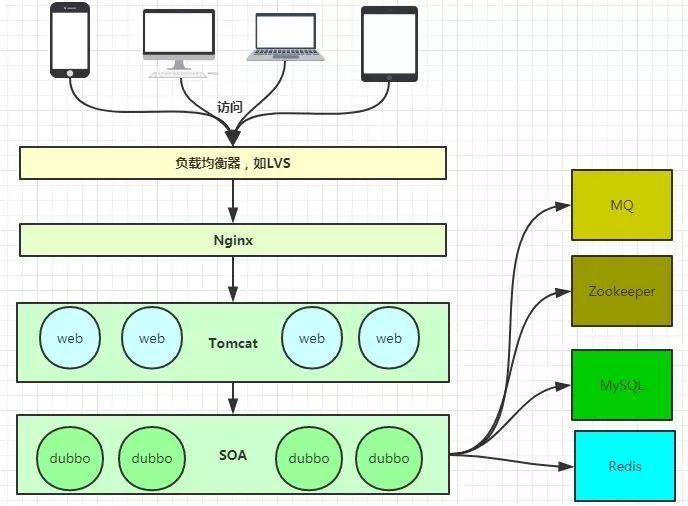
這一層做了反向負載、服務路由、服務治理、流量管理、安全隔離、服務容錯等等都做了,大家公司的內外網隔離也是這一層做的。
我之前還接觸過一些比較有意思的項目,所有對外的接口都是加密的,幾十個服務會經過網關解密,找到真的路由再去請求。

這一層的知識點其實也不少,你往后面學會發現分布式事務,分布式鎖,還有很多中間件都離不開zk這一層,我們繼續往下看。
服務層:
這一層有點東西了,算是整個框架的核心,如果你跟我帥丙一樣以后都是從事后端開發的話,我們基本上整個技術生涯,大部分時間都在跟這一層的技術棧打交道了,各種琳瑯滿目的中間件,計算機基礎知識,Linux操作,算法數據結構,架構框架,研發工具等等。
我想在看這個文章的各位,計算機基礎肯定都是學過的吧,如果大學的時候沒好好學,我覺得還是有必要再看看的。
為什么我們網頁能保證安全可靠的傳輸,你可能會了解到HTTP,TCP協議,什么三次握手,四次揮手。
還有進程、線程、協程,什么內存屏障,指令亂序,分支預測,CPU親和性等等,在之后的編程生涯,如果你能掌握這些東西,會讓你在遇到很多問題的時候瞬間get到點,而不是像個無頭蒼蠅一樣亂撞(然而丙丙還做得不夠)。
了解這些計算機知識后,你就需要接觸編程語言了,大學的C語言基礎會讓你學什么語言入門都會快點,我選擇了面向對象的JAVA,但是也不知道為啥現在還沒對象。
JAVA的基礎也一樣重要,面向對象(包括類、對象、方法、繼承、封裝、抽象、 多態、消息解析等),常見API,數據結構,集合框架,設計模式(包括創建型、結構型、行為型),多線程和并發,I/O流,Stream,網絡編程你都需要了解。
代碼會寫了,你就要開始學習一些能幫助你把系統變得更加規范的框架,SSM可以會讓你的開發更加便捷,結構層次更加分明。
寫代碼的時候你會發現你大學用的Eclipse在公司看不到了,你跟大家一樣去用了IDEA,第一天這是什么玩意,一周后,真香,但是這玩意收費有點貴,那免費的VSCode真的就是不錯的選擇了。
代碼寫的時候你會接觸代碼的倉庫管理工具maven、Gradle,提交代碼的時候會去寫項目版本管理工具Git。
代碼提交之后,發布之后你會發現很多東西需要自己去服務器親自排查,那Linux的知識點就可以在里面靈活運用了,查看進程,查看文件,各種Vim操作等等。
系統的優化很多地方沒優化的空間了,你可能會嘗試從算法,或者優化數據結構去優化,你看到了HashMap的源碼,想去了解紅黑樹,然后在算法網上看到了二叉樹搜索樹和各種常見的算法問題,刷多了,你也能總結出精華所在,什么貪心,分治,動態規劃等。
這么多個服務,你發現HTTP請求已經開始有點不滿足你的需求了,你想開發更便捷,像訪問本地服務一樣訪問遠程服務,所以我們去了解了Dubbo,Spring cloud。
了解Dubbo的過程中,你發現了RPC的精華所在,所以你去接觸到了高性能的NIO框架,Netty。
代碼寫好了,服務也能通信了,但是你發現你的代碼鏈路好長,都耦合在一起了,所以你接觸了消息隊列,這種異步的處理方式,真香。
他還可以幫你在突發流量的時候用隊列做緩沖,但是你發現分布式的情況,事務就不好管理了,你就了解到了分布式事務,什么兩段式,三段式,TCC,XA,阿里云的全局事務服務GTS等等。
分布式事務的時候你會想去了解RocketMQ,因為他自帶了分布式事務的解決方案,大數據的場景你又看到了Kafka。

我上面提到過zk,像Dubbo、Kafka等中間件都是用它做注冊中心的,所以很多技術棧最后都組成了一個知識體系,你先了解了體系中的每一員,你才能把它們聯系起來。
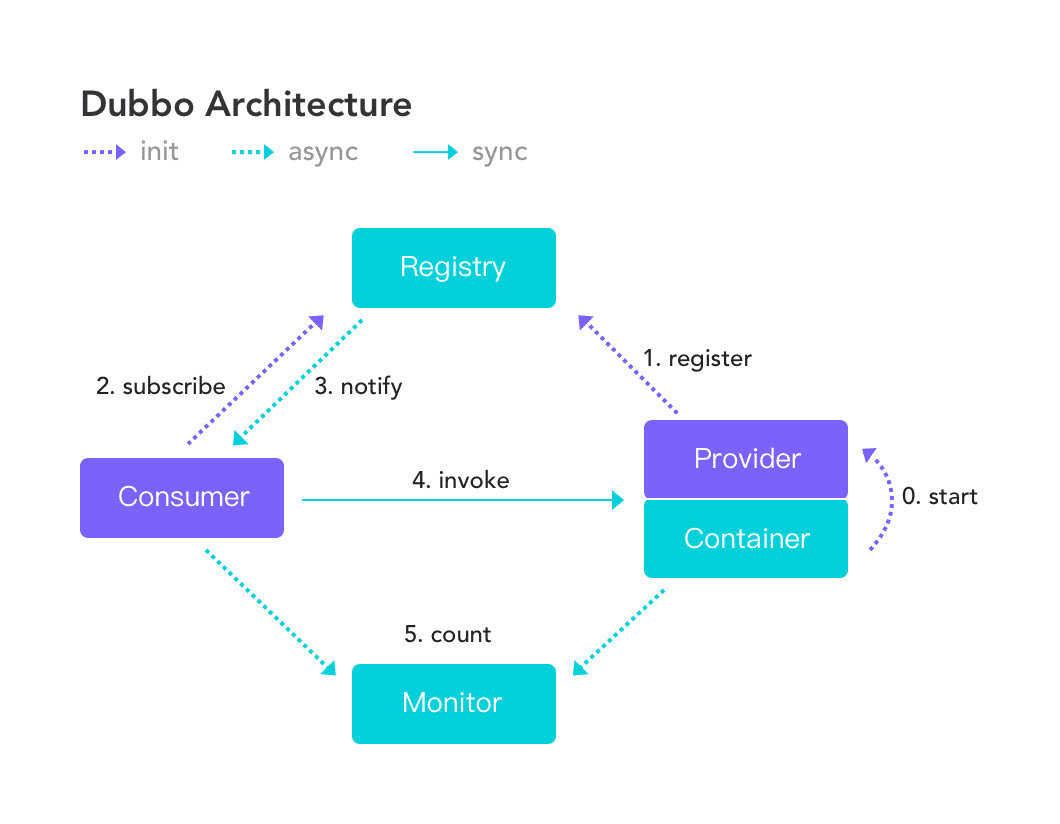
服務的交互都從進程內通信變成了遠程通信,所以性能必然會受到一些影響。
此外由于很多不確定性的因素,例如網絡擁塞、Server 端服務器宕機、挖掘機鏟斷機房光纖等等,需要許多額外的功能和措施才能保證微服務流暢穩定的工作。
Spring Cloud?中就有?Hystrix 熔斷器、Ribbon客戶端負載均衡器、Eureka注冊中心等等都是用來解決這些問題的微服務組件。
你感覺學習得差不多了,你發現各大論壇博客出現了一些前沿技術,比如容器化,你可能就會去了解容器化的知識,像**Docker,Kubernetes(K8s)**等。
微服務之所以能夠快速發展,很重要的一個原因就是:容器化技術的發展和容器管理系統的成熟。
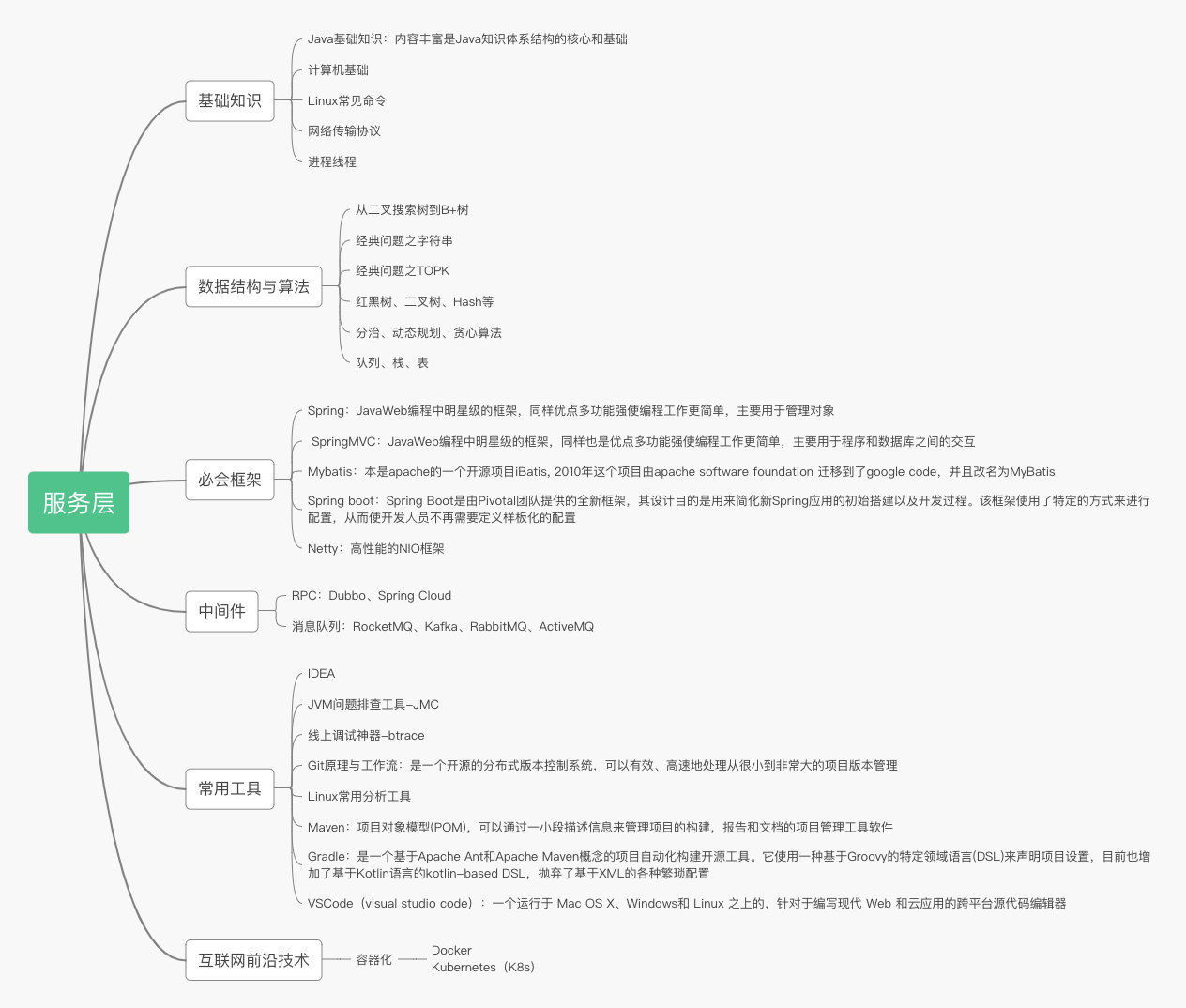
這一層的東西呢其實遠遠不止這些的,我不過多贅述,寫多了像個勸退師一樣,但是大家也不用慌,大部分的技術都是慢慢接觸了,工作中慢慢去了解,去深入的。
好啦我們繼續沿著圖往下看,那再往下是啥呢?
數據層:
數據庫可能是整個系統中最值錢的部分了,在我碼文字的前一天,剛好發生了微盟程序員刪庫跑路的操作,刪庫跑路其實是我們在網上最常用的笑話,沒想到還是照進了現實。

這里也提一點點吧,36小時的故障,其實在互聯網公司應該是個笑話了吧,權限控制沒做好類似rm -rf 、fdisk、drop等等這樣的高危命令是可以實時攔截掉的,備份,全量備份,增量備份,延遲備份,異地容災全部都考慮一下應該也不至于這樣,一家上市公司還是有點點不應該。

數據庫基本的事務隔離級別,索引,SQL,主被同步,讀寫分離等都可能是你學的時候要了解到的。
上面我們提到了安全,不要把雞蛋放一個籃子的道理大家應該都知道,那分庫的意義就很明顯了,然后你會發現時間久了表的數據大了,就會想到去接觸分表,什么TDDL、Sharding-JDBC、DRDS這些插件都會接觸到。
你發現流量大的時候,或者熱點數據打到數據庫還是有點頂不住,壓力太大了,那非關系型數據庫就進場了,Redis當然是首選,但是MongoDB、memcache也有各自的應用場景。
Redis使用后,真香,真快,但是你會開始擔心最開始提到的安全問題,這玩意快是因為在內存中操作,那斷點了數據丟了怎么辦?你就開始閱讀官方文檔,了解RDB,AOF這些持久化機制,線上用的時候還會遇到緩存雪崩擊穿、穿透等等問題。
單機不滿足你就用了,他的集群模式,用了集群可能也擔心集群的健康狀態,所以就得去了解哨兵,他的主從同步,時間久了Key多了,就得了解內存淘汰機制……
他的大容量存儲有問題,你可能需要去了解Pika….
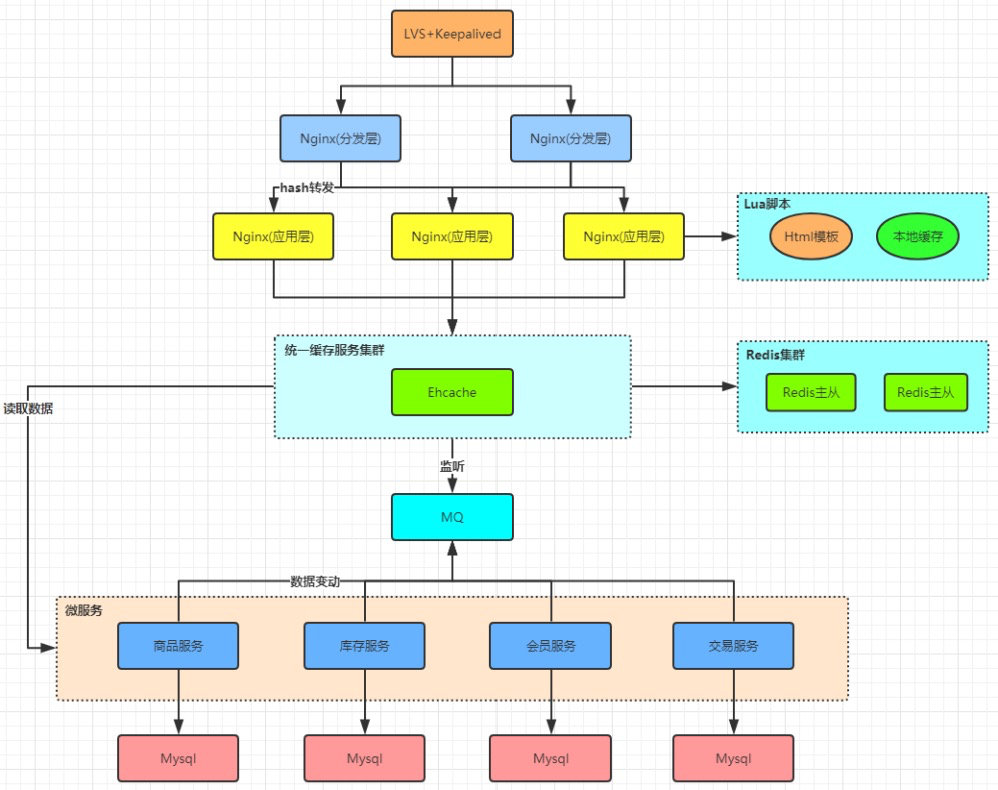

其實遠遠沒完,每個的點我都點到為止,但是其實要深究每個點都要學很久,我們接著往下看。
實時/離線/大數據
等你把幾種關系型非關系型數據庫的知識點,整理清楚后,你會發現數據還是大啊,而且數據的場景越來越多多樣化了,那大數據的各種中間件你就得了解了。
你會發現很多場景,不需要實時的數據,比如你查你的支付寶去年的,上個月的賬單,這些都是不會變化的數據,沒必要實時,那你可能會接觸像ODPS這樣的中間件去做數據的離線分析。
然后你可能會接觸Hadoop系列相關的東西,比如于Hadoop(HDFS)的一個數據倉庫工具Hive,是建立在 Hadoop 文件系統之上的分布式面向列的數據庫HBase?。
寫多的場景,適合做一些簡單查詢,用他們又有點大材小用,那Cassandra就再合適不過了。
離線的數據分析沒辦法滿足一些實時的常見,類似風控,那Flink你也得略知一二,他的窗口思想還是很有意思。
數據接觸完了,計算引擎Spark你是不是也不能放過……

搜索引擎:
傳統關系型數據庫和NoSQL非關系型數據都沒辦法解決一些問題,比如我們在百度,淘寶搜索東西的時候,往往都是幾個關鍵字在一起一起搜索東西的,在數據庫除非把幾次的結果做交集,不然很難去實現。
那全文檢索引擎就誕生了,解決了搜索的問題,你得思考怎么把數據庫的東西實時同步到ES中去,那你可能會思考到logstash去定時跑腳本同步,又或者去接觸偽裝成一臺MySQL從服務的Canal,他會去訂閱MySQL主服務的binlog,然后自己解析了去操作Es中的數據。
這些都搞定了,那可視化的后臺查詢又怎么解決呢?Kibana,他他是一個可視化的平臺,甚至對Es集群的健康管理都做了可視化,很多公司的日志查詢系統都是用它做的。

最后
每年轉戰互聯網行業的人很多,說白了也是沖著高薪去的,不管你是即將步入這個行業還是想轉行,學習是必不可少的。作為一個Java開發,學習成了日常生活的一部分,不學習你就會被這個行業淘汰,這也是這個行業殘酷的現實。
如果你對Java感興趣,想要轉行改變自己,那就要趁著機遇行動起來。或許,這份限量版的Java零基礎寶典能夠對你有所幫助。
領取這份Java零基礎寶典,只需要點擊這里即可免費下載
業殘酷的現實。
如果你對Java感興趣,想要轉行改變自己,那就要趁著機遇行動起來。或許,這份限量版的Java零基礎寶典能夠對你有所幫助。
領取這份Java零基礎寶典,只需要點擊這里即可免費下載
[外鏈圖片轉存中…(img-j9XE0MtH-1623907575160)]




















