正文
在實際的工作項目中, 緩存成為高并發、高性能架構的關鍵組件 ,那么Redis為什么可以作為緩存使用呢?首先可以作為緩存的兩個主要特征:
- 在分層系統中處于內存/CPU具有訪問性能良好,
- 緩存數據飽和,有良好的數據淘汰機制
由于Redis 天然就具有這兩個特征,Redis基于內存操作的,且其具有完善的數據淘汰機制,十分適合作為緩存組件。
其中,基于內存操作,容量可以為32-96GB,且操作時間平均為100ns,操作效率高。而且數據淘汰機制眾多,在Redis 4.0 后就有8種了促使Redis作為緩存可以適用很多場景。
那Redis緩存為什么需要數據淘汰機制呢?有哪8種數據淘汰機制呢?
數據淘汰機制
Redis緩存基于內存實現的,則其緩存其容量是有限的,當出現緩存被寫滿的情況,那么這時Redis該如何處理呢?
Redis對于緩存被寫滿的情況,Redis就需要緩存數據淘汰機制,通過一定淘汰規則將一些數據刷選出來刪除,讓緩存服務可再使用。那么Redis使用哪些淘汰策略進行刷選刪除數據?
在Redis 4.0 之后,Redis 緩存淘汰策略6+2種,包括分成三大類:
-
不淘汰數據
- noeviction ,不進行數據淘汰,當緩存被寫滿后,Redis不提供服務直接返回錯誤。
-
在設置過期時間的鍵值對中,
- volatile-random ,在設置過期時間的鍵值對中隨機刪除
- volatile-ttl ,在設置過期時間的鍵值對,基于過期時間的先后進行刪除,越早過期的越先被刪除。
- volatile-lru , 基于LRU(Least Recently Used) 算法篩選設置了過期時間的鍵值對, 最近最少使用的原則來篩選數據
- volatile-lfu ,使用 LFU( Least Frequently Used ) 算法選擇設置了過期時間的鍵值對, 使用頻率最少的鍵值對,來篩選數據。
-
在所有的鍵值對中,
- allkeys-random, 從所有鍵值對中隨機選擇并刪除數據
- allkeys-lru, 使用 LRU 算法在所有數據中進行篩選
- allkeys-lfu, 使用 LFU 算法在所有數據中進行篩選

Note: LRU( 最近最少使用,Least Recently Used)算法, LRU維護一個雙向鏈表 ,鏈表的頭和尾分別表示 MRU 端和 LRU 端,分別代表最近最常使用的數據和最近最不常用的數據。
LRU 算法在實際實現時,需要用鏈表管理所有的緩存數據,這會帶來額外的空間開銷。而且,當有數據被訪問時,需要在鏈表上把該數據移動到 MRU 端,如果有大量數據被訪問,就會帶來很多鏈表移動操作,會很耗時,進而會降低 Redis 緩存性能。
其中,LRU和LFU 基于Redis的對象結構redisObject的lru和refcount屬性實現的:
typedef struct redisObject {unsigned type:4;unsigned encoding:4;// 對象最后一次被訪問的時間unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or* LFU data (least significant 8 bits frequency// 引用計數 * and most significant 16 bits access time). */int refcount;void *ptr;
} robj;
Redis的LRU會使用redisObject的lru記錄最近一次被訪問的時間,隨機選取參數maxmemory-samples 配置的數量作為候選集合,在其中選擇 lru 屬性值最小的數據淘汰出去。
在實際項目中,那么該如何選擇數據淘汰機制呢?
- 優先選擇 allkeys-lru算法,將最近最常訪問的數據留在緩存中,提升應用的訪問性能。
- 有頂置數據使用 volatile-lru算法 ,頂置數據不設置緩存過期時間,其他數據設置過期時間,基于LRU 規則進行篩選 。
在理解了Redis緩存淘汰機制后,來看看Redis作為緩存其有多少種模式呢?
Redis緩存模式
Redis緩存模式基于是否接收寫請求,可以分成只讀緩存和讀寫緩存:
只讀緩存:只處理讀操作,所有的更新操作都在數據庫中,這樣數據不會有丟失的風險。
- Cache Aside模式
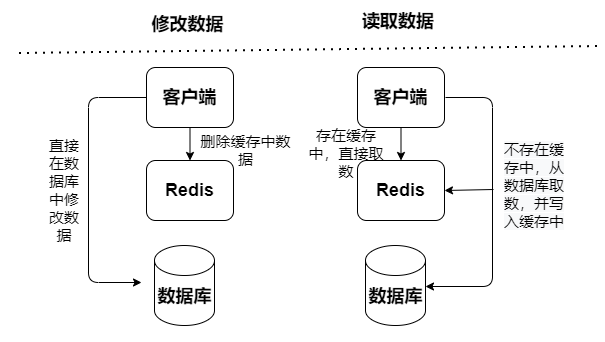
讀寫緩存,讀寫操作都在緩存中執行,出現宕機故障,會導致數據丟失。緩存回寫數據到數據庫有分成兩種同步和異步:
-
同步:訪問性能偏低,其更加側重于保證數據可靠性
- Read-Throug模式
- Write-Through模式
-
異步:有數據丟失風險,其側重于提供低延遲訪問
- Write-Behind模式

Cache Aside模式
查詢數據先從緩存讀取數據,如果緩存中不存在,則再到數據庫中讀取數據,獲取到數據之后更新到緩存Cache中,但更新數據操作,會先去更新數據庫種的數據,然后將緩存種的數據失效。
而且Cache Aside模式會存在并發風險:執行讀操作未命中緩存,然后查詢數據庫中取數據,數據已經查詢到還沒放入緩存,同時一個更新寫操作讓緩存失效,然后讀操作再把查詢到數據加載緩存,導致緩存的臟數據。
Read/Write-Throug模式
查詢數據和更新數據都直接訪問緩存服務,緩存服務同步方式地將數據更新到數據庫。出現臟數據的概率較低,但是就強依賴緩存,對緩存服務的穩定性有較大要求,但同步更新會導致其性能不好。
Write Behind模式
查詢數據和更新數據都直接訪問緩存服務,但緩存服務使用異步方式地將數據更新到數據庫(通過異步任務)?速度快,效率會非常高,但是數據的一致性比較差,還可能會有數據的丟失情況,實現邏輯也較為復雜。
在實際項目開發中根據實際的業務場景需求來進行選擇緩存模式。那了解上述后,我們的應用中為什么需要使用到redis緩存呢?
在應用使用Redis緩存可以提高系統性能和并發,主要體現在
- 高性能:基于內存查詢,KV結構,簡單邏輯運算
- 高并發: Mysql 每秒只能支持2000左右的請求,Redis輕松每秒1W以上。讓80%以上查詢走緩存,20%以下查詢走數據庫,能讓系統吞吐量有很大的提高
雖然使用Redis緩存可以大大提升系統的性能,但是使用了緩存,會出現一些問題,比如,緩存與數據庫雙向不一致、緩存雪崩等,對于出現的這些問題該怎么解決呢?
使用緩存常見的問題
使用了緩存,會出現一些問題,主要體現在:
- 緩存與數據庫雙寫不一致
- 緩存雪崩: Redis 緩存無法處理大量的應用請求,轉移到數據庫層導致數據庫層的壓力激增;
- 緩存穿透:訪問數據不存在在Redis緩存中和數據庫中,導致大量訪問穿透緩存直接轉移到數據庫導致數據庫層的壓力激增;
- 緩存擊穿:緩存無法處理高頻熱點數據,導致直接高頻訪問數據庫導致數據庫層的壓力激增;
緩存與數據庫數據不一致
只讀緩存(Cache Aside模式)
對于只讀緩存(Cache Aside模式), 讀操作都發生在緩存中,數據不一致只會發生在刪改操作上(新增操作不會,因為新增只會在數據庫處理),當發生刪改操作時,緩存將數據中標志為無效和更新數據庫 。因此在更新數據庫和刪除緩存值的過程中,無論這兩個操作的執行順序誰先誰后,只要有一個操作失敗了就會出現數據不一致的情況。
面試準備+復習資料分享:
為了應付面試也刷了很多的面試題與資料,現在就分享給有需要的讀者朋友,資料我只截取出來一部分哦,有需要的可以來找我獲取哈
獲取方式:點擊藍色字體即可免費獲取
出來一部分哦,有需要的可以來找我獲取哈
獲取方式:點擊藍色字體即可免費獲取
[外鏈圖片轉存中…(img-bzuPKX53-1624225454343)]



















