01 分布式限流:Nginx+ZooKeeper
1.1 分布式限流之Nginx
-
請解釋一下什么是 Nginx?
-
請列舉 x Nginx 的一些特性。
-
請列舉 x Nginx 和 和 Apache 之間的不同點
-
請解釋 x Nginx 如何處理 P HTTP 請求。
-
在 x Nginx 中,如何使用未定義的服務器名稱來阻止處理請求?
-
使用 “ 反向代理服務器 ”
-
請列舉 x Nginx 服務器的最佳用途。
-
請解釋 x Nginx 服務器上的 r Master 和 和 r Worker 進程分別是什么?
-
請解釋你如何通過不同于 0 80 的端口開啟 Nginx?
-
請解釋是否有可能將 x Nginx 的錯誤替換為 2 502 錯誤?
-
在 x Nginx 中,解釋如何在 L URL 中保留雙斜線? ?
-
請解釋 e ngx_http_upstream_module 的作用是什么?
-
請解釋什么是 K C10K 問題?
-
請陳述 s stub_status 和 和 r sub_filter 指令的作用是什么?
-
解釋 x Nginx 是否支持將請求壓縮到上游?
-
解釋如何在 x Nginx 中獲得當前的時間?
-
用 x Nginx 服務器解釋s -s 的目的是什么?
-
解釋如何在 x Nginx 服務器上添加模塊?
分布式限流之Nginx的答案解析如下:
for:Nginx+常見應用技術指南[Nginx++Tips]+第二版
![Nginx+常見應用技術指南[Nginx++Tips]+第二版](https://img-blog.csdnimg.cn/img_convert/467e0626245368b43d50d2b8b014cba0.png)
1.2 分布式限流之ZooKeeper
-
ZooKeeper 是什么?
-
ZooKeeper 提供了什么?
-
Zookeeper 文件系統
-
四種類型的 znode
-
Zookeeper 通知機制
-
Zookeeper 做了什么?
-
zk 的命名服務(文件系統)
-
zk 的配置管理(文件系統、通知機制)
-
Zookeeper 集群管理(文件系統、通知機制)
-
Zookeeper 分布式鎖(文件系統、通知機制)
-
獲取分布式鎖的流程
-
Zookeeper 隊列管理(文件系統、通知機制)
-
Zookeeper 數據復制
-
Zookeeper 工作原理
-
zookeeper 是如何保證事務的順序一致性的?
-
Zookeeper 下 Server 工作狀態
-
zookeeper 是如何選取主 leader 的?
-
分布式通知和協調
-
機器中為什么會有 leader?
-
zk 節點宕機如何處理?
-
Zookeeper 同步流程
-
zookeeper 負載均衡和 nginx 負載均衡區別
-
zookeeper watch 機制
分布式限流之ZooKeeper的答案解析如下

for:ZK開發手冊
02 分布式通訊:ActiveMQ+Kafka+RabbitMQ
2.1 分布式通訊之ActiveMQ
-
什么是 ActiveMQ?
-
ActiveMQ 服務器宕機怎么辦?
-
丟消息怎么辦?
-
持久化消息非常慢
-
消息的不均勻消費。
-
死信隊列。
-
ActiveMQ 中的消息重發時間間隔和重發次數嗎?
分布式通訊之ActiveMQ的答案解析如下:

for:手寫RocketMQ筆記
2.2 分布式通訊之kafka
-
Kafka 的設計時什么樣的呢?
-
數據傳輸的事物定義有哪三種?
-
Kafka 判斷一個節點是否還活著有那兩個條件?
-
producer 是否直接將數據發送到 broker 的 leader(主節點)?
-
Kafa consumer 是否可以消費指定分區消息?
-
Kafka 消息是采用 Pull 模式,還是 Push 模式?
-
Kafka 存儲在硬盤上的消息格式是什么?
-
Kafka 高效文件存儲設計特點:
-
Kafka 與傳統消息系統之間有三個關鍵區別
-
Kafka 創建 Topic 時如何將分區放置到不同的 Broker 中
-
Kafka 新建的分區會在哪個目錄下創建
-
partition 的數據如何保存到硬盤
-
kafka 的 ack 機制
-
Kafka 的消費者如何消費數據
-
消費者負載均衡策略
-
數據有序
-
kafaka 生產數據時數據的分組策略
分布式通訊之kafka的答案解析如下:
for:Kafka源碼解析與實戰
2.3 分布式通訊之RabbitMQ
-
RabbitMQ 中的 broker 是指什么?cluster 又是指什么?
-
什么是元數據?元數據分為哪些類型?包括哪些內容?與 cluster 相關的元數據有哪些?元數據是如何保存的?元數據在 cluster 中是如何分布的?
-
RAM node 和 disk node 的區別?
-
RabbitMQ 上的一個 queue 中存放的 message 是否有數量限制?
-
RabbitMQ 概念里的 channel、exchange 和 queue 這些東東是邏輯概念,還是對應著進程實體?這些東東分別起什么作用?
-
vhost 是什么?起什么作用?
-
在單 node 系統和多 node 構成的 cluster 系統中聲明 queue、exchange ,以及進行 binding 會有什么不同?
-
客戶端連接到 cluster 中的任意 node 上是否都能正常工作?
-
cluster 中 node 的失效會對 consumer 產生什么影響?若是在 cluster 中創建了mirrored queue ,這時 node 失效會對 consumer 產生什么影響?
-
能夠在地理上分開的不同數據中心使用 RabbitMQ cluster 么?
-
為什么 heavy RPC 的使用場景下不建議采用 disk node ?
-
向不存在的 exchange 發 publish 消息會發生什么?向不存在的 queue 執行consume 動作會發生什么?
-
routing_key 和 binding_key 的最大長度是多少?
-
RabbitMQ 允許發送的 message 最大可達多大?
-
什么情況下 producer 不主動創建 queue 是安全的?
-
“dead letter”queue 的用途?
-
為什么說保證 message 被可靠持久化的條件是 queue 和 exchange 具有durable 屬性,同時 message 具有 persistent 屬性才行?
-
什么情況下會出現 blackholed 問題?
-
如何防止出現 blackholed 問題?
-
Consumer Cancellation Notification 機制用于什么場景?
-
Basic.Reject 的用法是什么?
-
為什么不應該對所有的 message 都使用持久化機制?
-
RabbitMQ 中的 cluster、mirrored queue,以及 warrens 機制分別用于解決什么問題?存在哪些問題?
分布式通訊之RabbitMQ的答案解析如下:
for:RabbitMQ實戰指南
03 分布式緩存:memcached+MongoDB+Redis
3.1 分布式緩存之memcached
-
memcached 是怎么工作的?
-
memcached 最大的優勢是什么?
-
memcached 和服務器的 local cache (比如 PHP 的 的 APC 、mmap 文件等)相比,有什么優缺點?
-
memcached 和 和 MySQL 的 的 query cache 相比,有什么優缺點?
-
memcached 的 的 cache 機制是怎樣的?
-
memcached 如何實現冗余機制?
-
我需要把 memcached 中的 item 批量導出導入,怎么辦?
-
memcached 如何處理容錯的?
-
如何將 memcached 中 中 item 批量導入導出?
-
memcached 是如何做身份驗證的?
-
memcached 的多線程是什么?如何使用它們?
-
memcached 能接受的 key 的最大長度是多少?
-
memcached 對 對 item 的過期時間有什么限制?
-
memcached 最大能存儲多大的單個 item ?
-
為什么單個 item 的大小被限制在 1M byte 之內?
分布式緩存之memcached的答案解析如下:
3.2 分布式緩存之MongoDB
-
你說的 NoSQL 數據庫是什么意思?NoSQL 與 RDBMS 直接有什么區別?為什么要使用和不使用NoSQL 數據庫?說一說 NoSQL 數據庫的幾個優點?
-
NoSQL 數據庫有哪些類型?
-
MySQL 與 MongoDB 之間最基本的差別是什么?
-
你怎么比較 MongoDB、CouchDB 及 CouchBase?
-
MongoDB 成為最好 NoSQL 數據庫的原因是什么?
-
32 位系統上有什么細微差別?
-
journal 回放在條目(entry)不完整時(比如恰巧有一個中途故障了)會遇到問題嗎?
-
分析器在 MongoDB 中的作用是什么?
-
名字空間(namespace)是什么?
-
如果用戶移除對象的屬性,該屬性是否從存儲層中刪除?
-
能否使用日志特征進行安全備份?
-
允許空值 null 嗎?
-
更新操作立刻 fsync 到磁盤?
-
如何執行事務/加鎖?
-
為什么我的數據文件如此龐大?
-
啟用備份故障恢復需要多久?
-
什么是 master 或 primary?
-
什么是 secondary 或 slave?
-
我必須調用 getLastError 來確保寫操作生效了么?
-
我應該啟動一個集群分片(sharded)還是一個非集群分片的 MongoDB 環境?
-
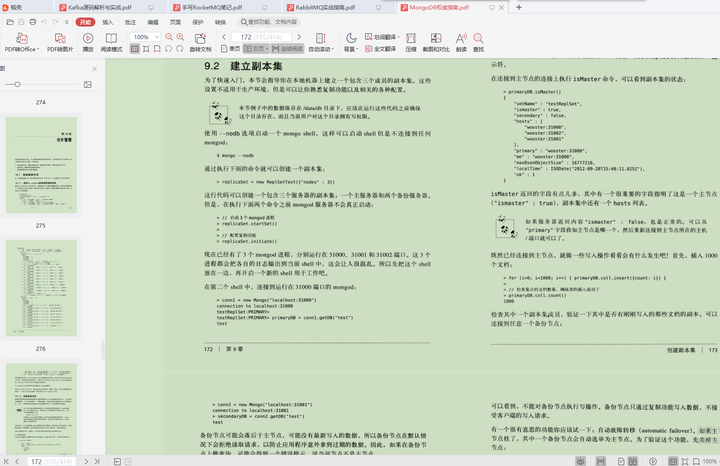
分片(sharding)和復制(replication)是怎樣工作的?
-
數據在什么時候才會擴展到多個分片(shard)里?
-
當我試圖更新一個正在被遷移的塊(chunk)上的文檔時會發生什么?
-
如果在一個分片(shard)停止或者很慢的時候,我發起一個查詢會怎樣?
-
我可以把 moveChunk 目錄里的舊文件刪除嗎?
-
我怎么查看 Mongo 正在使用的鏈接?
-
如果塊移動操作(moveChunk)失敗了,我需要手動清除部分轉移的文檔嗎?
-
如果我在使用復制技術(replication),可以一部分使用日志(journaling)而其他部分則不使用嗎?
-
當更新一個正在被遷移的塊(Chunk)上的文檔時會發生什么?
-
MongoDB 在 A:{B,C}上建立索引,查詢 A:{B,C}和 A:{C,B}都會使用索引嗎?
-
如果一個分片(Shard)停止或很慢的時候,發起一個查詢會怎樣?
-
MongoDB 支持存儲過程嗎?如果支持的話,怎么用?
-
如何理解 MongoDB 中的 GridFS 機制,MongoDB 為何使用 GridFS 來存儲文件?
分布式緩存之MongoDB的答案解析如下:
for:MongoDB權威指南
3.3 分布式緩存之Redis
-
redis 簡介
-
為什么要用 redis /為什么要用緩存(高性能、高并發)
-
為什么要用 redis 而不用 map/guava 做緩存?
-
redis 和 memcached 的區別
-
redis 常見數據結構以及使用場景分析(String、Hash、List、Set、Sorted Set)
-
redis 設置過期時間
-
redis 內存淘汰機制(MySQL里有2000w數據,Redis中只存20w的數據,如何保證Redis中的數據都是熱點數據?)
-
redis 持久化機制(怎么保證 redis 掛掉之后再重啟數據可以進行恢復)
-
redis 事務
-
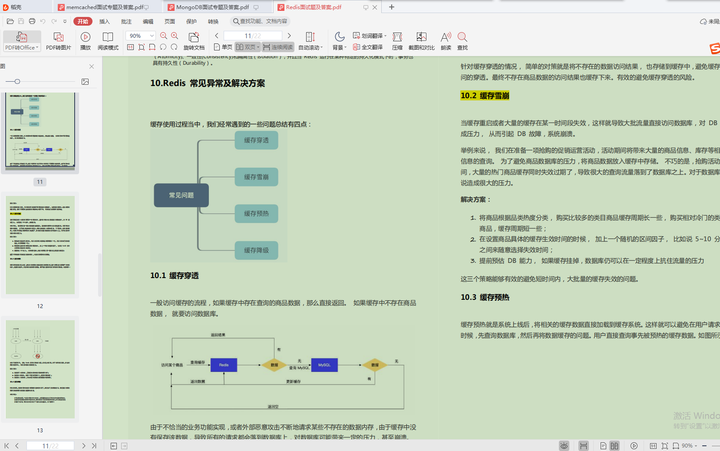
Redis 常見異常及解決方案(緩存穿透、緩存雪崩、緩存預熱、緩存降級)
-
分布式環境下常見的應用場景(分布式鎖、分布式自增 ID)
-
Redis 集群模式(主從模式、哨兵模式、Cluster 集群模式)
-
如何解決 Redis 的并發競爭 Key 問題
-
如何保證緩存與數據庫雙寫時的數據一致性?
分布式緩存之Redis的答案解析如下:
for:Redis設計與實現
最后分享一波我的面試寶典——一線互聯網大廠Java核心面試題庫
以下是我個人的一些做法,希望可以給各位提供一些幫助:
點擊《一線互聯網大廠Java核心面試題庫》即可免費領取,整理了很長一段時間,拿來復習面試刷題非常合適,其中包括了Java基礎、異常、集合、并發編程、JVM、Spring全家桶、MyBatis、Redis、數據庫、中間件MQ、Dubbo、Linux、Tomcat、ZooKeeper、Netty等等,且還會持續的更新…可star一下!
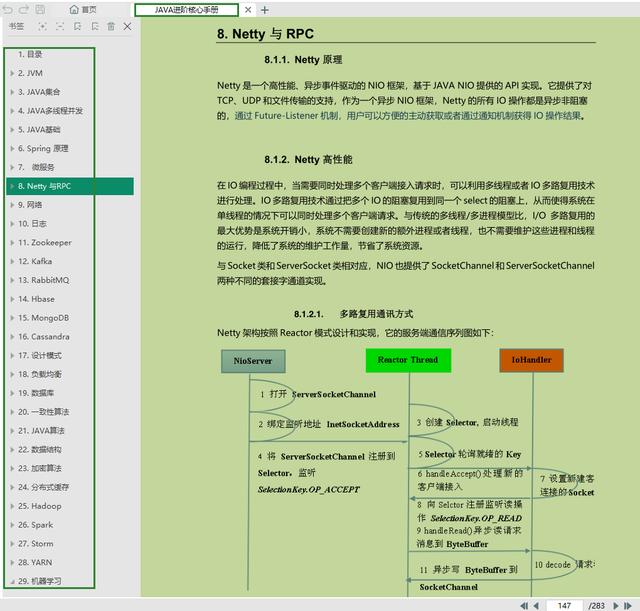
283頁的Java進階核心pdf文檔
Java部分:Java基礎,集合,并發,多線程,JVM,設計模式
數據結構算法:Java算法,數據結構
開源框架部分:Spring,MyBatis,MVC,netty,tomcat
分布式部分:架構設計,Redis緩存,Zookeeper,kafka,RabbitMQ,負載均衡等
微服務部分:SpringBoot,SpringCloud,Dubbo,Docker
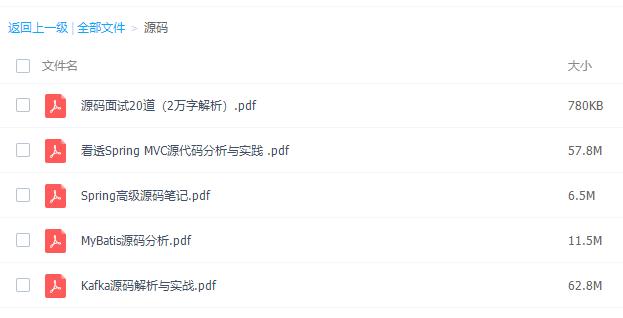
還有源碼相關的閱讀學習
Netty等等,且還會持續的更新…可star一下!
[外鏈圖片轉存中…(img-t81HV1G7-1624225674231)]
283頁的Java進階核心pdf文檔
Java部分:Java基礎,集合,并發,多線程,JVM,設計模式
數據結構算法:Java算法,數據結構
開源框架部分:Spring,MyBatis,MVC,netty,tomcat
分布式部分:架構設計,Redis緩存,Zookeeper,kafka,RabbitMQ,負載均衡等
微服務部分:SpringBoot,SpringCloud,Dubbo,Docker
[外鏈圖片轉存中…(img-HilptgkW-1624225674232)]
還有源碼相關的閱讀學習
[外鏈圖片轉存中…(img-5MNg0iSt-1624225674232)]










...)








