NO1:說說zookeeper是什么?
ZooKeeper是一個分布式的,開放源碼的分布式應用程序協調服務,是Google的Chubby一個開源的實現(Chubby是不開源的),它是集群的管理者,監視著集群中各個節點的狀態根據節點提交的反饋進行下一步合理操作。最終,將簡單易用的接口和性能高效、功能穩定的系統提供給用戶 。
Zookeeper一個最常用的使用場景就是用于擔任服務生產者和服務消費者的注冊中心,服務生產者將自己提供的服務注冊到Zookeeper中心,服務的消費者在進行服務調用的時候先到Zookeeper中查找服務,獲取到服務生產者的詳細信息之后,再去調用服務生產者的內容與數據,簡單示例圖如下:
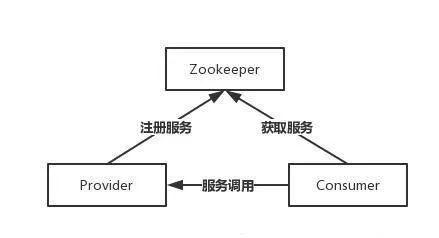
NO2:了解Zookeeper的系統架構嗎?

ZooKeeper 的架構圖中我們需要了解和掌握的主要有:
(1)ZooKeeper分為服務器端(Server) 和客戶端(Client),客戶端可以連接到整個 ZooKeeper服務的任意服務器上(除非 leaderServes 參數被顯式設置, leader 不允許接受客戶端連接)。
(2)客戶端使用并維護一個 TCP 連接,通過這個連接發送請求、接受響應、獲取觀察的事件以及發送信息。如果這個 TCP 連接中斷,客戶端將自動嘗試連接到另外的 ZooKeeper服務器。客戶端第一次連接到 ZooKeeper服務時,可以接受這個連接的 ZooKeeper服務器會為這個客戶端建立一個會話。當這個客戶端連接到另外的服務器時,這個會話會被新的服務器重新建立。
(3)上圖中每一個Server代表一個安裝Zookeeper服務的機器,即是整個提供Zookeeper服務的集群(或者是由偽集群組成);
(4)組成ZooKeeper服務的服務器必須彼此了解。它們維護一個內存中的狀態圖像,以及持久存儲中的事務日志和快照, 只要大多數服務器可用,ZooKeeper服務就可用;
(5)ZooKeeper 啟動時,將從實例中選舉一個 leader,Leader 負責處理數據更新等操作,一個更新操作成功的標志是當且僅當大多數Server在內存中成功修改數據。每個Server 在內存中存儲了一份數據。
(6)Zookeeper是可以集群復制的,集群間通過Zab協議(Zookeeper Atomic Broadcast)來保持數據的一致性;
(7)Zab協議包含兩個階段:leader election階段和Atomic Brodcast階段。
- a) 集群中將選舉出一個leader,其他的機器則稱為follower,所有的寫操作都被傳送給leader,并通過brodcast將所有的更新告訴給follower。
- b) 當leader崩潰或者leader失去大多數的follower時,需要重新選舉出一個新的leader,讓所有的服務器都恢復到一個正確的狀態。
- c) 當leader被選舉出來,且大多數服務器完成了 和leader的狀態同步后,leadder election 的過程就結束了,就將會進入到Atomic brodcast的過程。
- d) Atomic Brodcast同步leader和follower之間的信息,保證leader和follower具有形同的系統狀態。
NO3:能說說Zookeeper的工作原理?
Zookeeper的核心是原子廣播,這個機制保證了各個Server之間的同步。實現這個機制的協議叫做Zab協議。
Zab協議有兩種模式,它們 分別是恢復模式(選主)和廣播模式(同步)。
Zab協議 的全稱是 Zookeeper Atomic Broadcast** (Zookeeper原子廣播)。Zookeeper 是通過 Zab 協議來保證分布式事務的最終一致性。Zab協議要求每個 Leader 都要經歷三個階段:發現,同步,廣播。
當服務啟動或者在領導者崩潰后,Zab就進入了恢復模式,當領導者被選舉出來,且大多數Server完成了和 leader的狀態同步以后,恢復模式就結束了。狀態同步保證了leader和Server具有相同的系統狀態。
為了保證事務的順序一致性,zookeeper采用了遞增的事務id號(zxid)來標識事務。所有的提議(proposal)都在被提出的時候加 上了zxid。實現中zxid是一個64位的數字,它高32位是epoch用來標識leader關系是否改變,每次一個leader被選出來,它都會有一 個新的epoch,標識當前屬于那個leader的統治時期。第32位用于遞增計數。
epoch:可以理解為皇帝的年號,當新的皇帝leader產生后,將有一個新的epoch年號。
每個Server在工作過程中有三種狀態:
- LOOKING:當前Server不知道leader是誰,正在搜尋。
- LEADING:當前Server即為選舉出來的leader。
- FOLLOWING:leader已經選舉出來,當前Server與之同步。
NO4:Zookeeper為什么要這么設計?
ZooKeeper設計的目的是提供高性能、高可用、順序一致性的分布式協調服務、保證數據最終一致性。
高性能(簡單的數據模型)
- 采用樹形結構組織數據節點;
- 全量數據節點,都存儲在內存中;
- Follower 和 Observer 直接處理非事務請求;
高可用(構建集群)
- 半數以上機器存活,服務就能正常運行
- 自動進行 Leader 選舉
順序一致性(事務操作的順序)
- 每個事務請求,都會轉發給 Leader 處理
- 每個事務,會分配全局唯一的遞增id(zxid,64位:epoch + 自增 id)
最終一致性
- 通過提議投票方式,保證事務提交的可靠性
- 提議投票方式,只能保證 Client 收到事務提交成功后,半數以上節點能夠看到最新數據
NO5:你知道Zookeeper中有哪些角色?
系統模型:
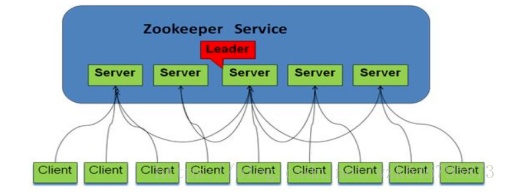
領導者(leader)
Leader服務器為客戶端提供讀服務和寫服務。負責進行投票的發起和決議,更新系統狀態。
學習者(learner)
- 跟隨者(follower) Follower服務器為客戶端提供讀服務,參與Leader選舉過程,參與寫操作“過半寫成功”策略。
- 觀察者(observer) Observer服務器為客戶端提供讀服務,不參與Leader選舉過程,不參與寫操作“過半寫成功”策略。用于在不影響寫性能的前提下提升集群的讀性能。
客戶端(client):服務請求發起方。
NO6:你熟悉Zookeeper節點ZNode和相關屬性嗎?
節點有哪些類型?
Znode兩種類型:
持久的(persistent):客戶端和服務器端斷開連接后,創建的節點不刪除(默認)。
短暫的(ephemeral):客戶端和服務器端斷開連接后,創建的節點自己刪除。
Znode有四種形式:
- 持久化目錄節點(PERSISTENT):客戶端與Zookeeper斷開連接后,該節點依舊存在持久化順序編號目錄節點(PERSISTENT_SEQUENTIAL)
- 客戶端與Zookeeper斷開連接后,該節點依舊存在,只是Zookeeper給該節點名稱進行順序編號:臨時目錄節點(EPHEMERAL)
- 客戶端與Zookeeper斷開連接后,該節點被刪除:臨時順序編號目錄節點(EPHEMERAL_SEQUENTIAL)
- 客戶端與Zookeeper斷開連接后,該節點被刪除,只是Zookeeper給該節點名稱進行順序編號
「注意」:創建ZNode時設置順序標識,ZNode名稱后會附加一個值,順序號是一個單調遞增的計數器,由父節點維護。
總結
面試建議是,一定要自信,敢于表達,面試的時候我們對知識的掌握有時候很難面面俱到,把自己的思路說出來,而不是直接告訴面試官自己不懂,這也是可以加分的。
以上就是螞蟻技術四面和HR面試題目,以下最新總結的最全,范圍包含最全MySQL、Spring、Redis、JVM等最全面試題和答案,僅用于參考
以上就是螞蟻技術四面和HR面試題目,以下最新總結的最全,范圍包含最全MySQL、Spring、Redis、JVM等最全面試題和答案,僅用于參考
[外鏈圖片轉存中…(img-W1Wmc7Ea-1624341234085)]
如何獲取面試參考資料?戳這里免費領取




...)














