https://blog.csdn.net/lyztyycode/article/details/78648798?locationNum=6&fps=1
linux驚群效應
1、驚群效應是什么?
2.驚群效應到底消耗了什么?
3.驚群效應的廬山真面目。
*1)accept()驚群:
- #include<stdio.h>??
- #include<stdlib.h>??
- #include<sys/types.h>??
- #include<sys/socket.h>??
- #include<sys/wait.h>??
- #include<string.h>??
- #include<netinet/in.h>??
- #include<unistd.h>??
- ??
- #define?PROCESS_NUM?10??
- int?main()??
- {??
- ????int?fd?=?socket(PF_INET,?SOCK_STREAM,?0);??
- ????int?connfd;??
- ????int?pid;??
- ??
- ????char?sendbuff[1024];??
- ????struct?sockaddr_in?serveraddr;??
- ????serveraddr.sin_family?=?AF_INET;??
- ????serveraddr.sin_addr.s_addr?=?htonl(INADDR_ANY);??
- ????serveraddr.sin_port?=?htons(1234);??
- ????bind(fd,?(struct?sockaddr?*)&serveraddr,?sizeof(serveraddr));??
- ????listen(fd,?1024);??
- ????int?i;??
- ????for(i?=?0;?i?<?PROCESS_NUM;?++i){??
- ????????pid?=?fork();??
- ????????if(pid?==?0){??
- ????????????while(1){??
- ????????????????connfd?=?accept(fd,?(struct?sockaddr?*)NULL,?NULL);??
- ????????????????snprintf(sendbuff,?sizeof(sendbuff),?"接收到accept事件的進程PID?=?%d\n",?getpid());??
- ??
- ????????????????send(connfd,?sendbuff,?strlen(sendbuff)+1,?0);??
- ????????????????printf("process?%d?accept?success\n",?getpid());??
- ????????????????close(connfd);??
- ????????????}??
- ????????}??
- ????}??
- ????//int?status;??
- ????wait(0);??
- ????return?0;??
- }??
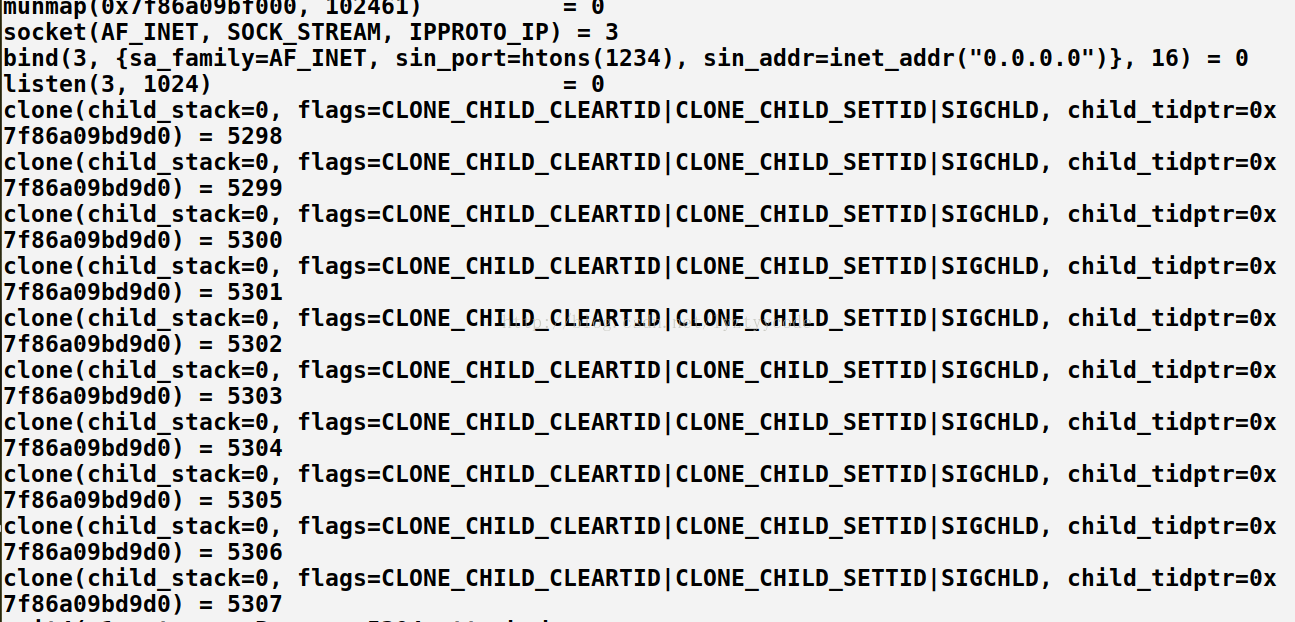
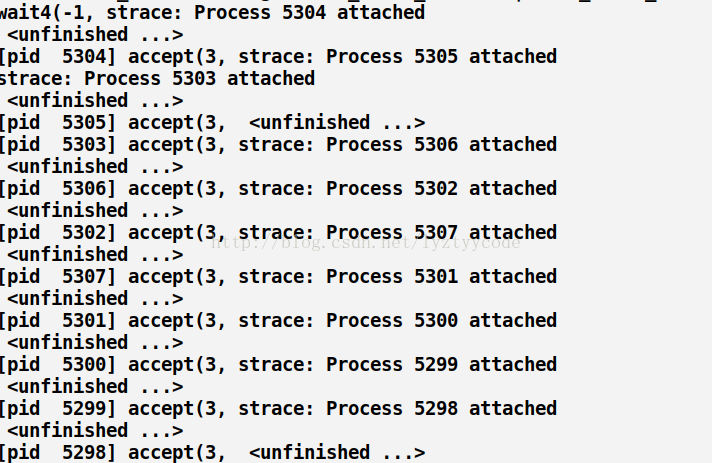

很明顯當telnet連接的時候只有一個進程accept成功,你會不會和我有同樣的疑問,就是會不會內核中喚醒了所有的進程只是沒有獲取到資源失敗了,就好像驚群被“隱藏”?
這個問題很好證明,我們修改一下代碼:
- connfd?=?accept(fd,?(struct?sockaddr?*)NULL,?NULL);??
- if(connfd?==?0){??
- ??
- ????snprintf(sendbuff,?sizeof(sendbuff),?"接收到accept事件的進程PID?=?%d\n",?getpid());??
- ??
- ????send(connfd,?sendbuff,?strlen(sendbuff)+1,?0);??
- ????printf("process?%d?accept?success\n",?getpid());??
- ????close(connfd);??
- }else{??
- ????printf("process?%d?accept?a?connection?failed:?%s\n",?getpid(),?strerror(errno));??
- ????close(connfd);??
- }??
沒錯,就是增加了一個accept失敗的返回信息,按照上面的步驟運行,這里我就不截圖了,我只告訴你運行結果與上面的運行結果無異,增加的失敗信息并沒有輸出,也就說明了這里并沒有發生驚群,所以注意阻塞和驚群的喚醒的區別。
Google了一下:其實在linux2.6版本以后,linux內核已經解決了accept()函數的“驚群”現象,大概的處理方式就是,當內核接收到一個客戶連接后,只會喚醒等待隊列上的第一個進程(線程),所以如果服務器采用accept阻塞調用方式,在最新的linux系統中已經沒有“驚群效應”了
accept函數的驚群解決了,下面來讓我們看看存在驚群現象的另一種情況:epoll驚群
*2)epoll驚群:
同樣讓我們假設一個場景:
主進程創建socket,bind,listen后,將該socket加入到epoll中,然后fork出多個子進程,每個進程都阻塞在epoll_wait上,如果有事件到來,則判斷該事件是否是該socket上的事件如果是,說明有新的連接到來了,則進行接受操作。為了簡化處理,忽略后續的讀寫以及對接受返回的新的套接字的處理,直接斷開連接。
那么,當新的連接到來時,是否每個阻塞在epoll_wait上的進程都會被喚醒呢?
很多博客中提到,測試表明雖然epoll_wait不會像接受那樣只喚醒一個進程/線程,但也不會把所有的進程/線程都喚醒。
我們還是眼見為實,一步步解決上面的疑問:
代碼實例:epoll_thunder_herd.c:
- #include<stdio.h>??
- #include<sys/types.h>??
- #include<sys/socket.h>??
- #include<unistd.h>??
- #include<sys/epoll.h>??
- #include<netdb.h>??
- #include<stdlib.h>??
- #include<fcntl.h>??
- #include<sys/wait.h>??
- #include<errno.h>??
- #define?PROCESS_NUM?10??
- #define?MAXEVENTS?64??
- //socket創建和綁定??
- int?sock_creat_bind(char?*?port){??
- ????int?sock_fd?=?socket(AF_INET,?SOCK_STREAM,?0);??
- ????struct?sockaddr_in?serveraddr;??
- ????serveraddr.sin_family?=?AF_INET;??
- ????serveraddr.sin_port?=?htons(atoi(port));??
- ????serveraddr.sin_addr.s_addr?=?htonl(INADDR_ANY);??
- ??
- ????bind(sock_fd,?(struct?sockaddr?*)&serveraddr,?sizeof(serveraddr));??
- ????return?sock_fd;??
- }??
- //利用fcntl設置文件或者函數調用的狀態標志??
- int?make_nonblocking(int?fd){??
- ????int?val?=?fcntl(fd,?F_GETFL);??
- ????val?|=?O_NONBLOCK;??
- ????if(fcntl(fd,?F_SETFL,?val)?<?0){??
- ????????perror("fcntl?set");??
- ????????return?-1;??
- ????}??
- ????return?0;??
- }??
- ??
- int?main(int?argc,?char?*argv[])??
- {??
- ????int?sock_fd,?epoll_fd;??
- ????struct?epoll_event?event;??
- ????struct?epoll_event?*events;??
- ??????????
- ????if(argc?<?2){??
- ????????printf("usage:?[port]?%s",?argv[1]);??
- ????????exit(1);??
- ????}??
- ?????if((sock_fd?=?sock_creat_bind(argv[1]))?<?0){??
- ????????perror("socket?and?bind");??
- ????????exit(1);??
- ????}??
- ????if(make_nonblocking(sock_fd)?<?0){??
- ????????perror("make?non?blocking");??
- ????????exit(1);??
- ????}??
- ????if(listen(sock_fd,?SOMAXCONN)?<?0){??
- ????????perror("listen");??
- ????????exit(1);??
- ????}??
- ????if((epoll_fd?=?epoll_create(MAXEVENTS))<?0){??
- ????????perror("epoll_create");??
- ????????exit(1);??
- ????}??
- ????event.data.fd?=?sock_fd;??
- ????event.events?=?EPOLLIN;??
- ????if(epoll_ctl(epoll_fd,?EPOLL_CTL_ADD,?sock_fd,?&event)?<?0){??
- ????????perror("epoll_ctl");??
- ????????exit(1);??
- ????}??
- ????/*buffer?where?events?are?returned*/??
- ????events?=?calloc(MAXEVENTS,?sizeof(event));??
- ????int?i;??
- ????for(i?=?0;?i?<?PROCESS_NUM;?++i){??
- ????????int?pid?=?fork();??
- ????????if(pid?==?0){??
- ????????????while(1){??
- ????????????????int?num,?j;??
- ????????????????num?=?epoll_wait(epoll_fd,?events,?MAXEVENTS,?-1);??
- ????????????????printf("process?%d?returnt?from?epoll_wait\n",?getpid());??
- ????????????????sleep(2);??
- ????????????????for(i?=?0;?i?<?num;?++i){??
- ????????????????????if((events[i].events?&?EPOLLERR)?||?(events[i].events?&?EPOLLHUP)?||?(!(events[i].events?&?EPOLLIN))){??
- ????????????????????????fprintf(stderr,?"epoll?error\n");??
- ????????????????????????close(events[i].data.fd);??
- ????????????????????????continue;??
- ????????????????????}else?if(sock_fd?==?events[i].data.fd){??
- ????????????????????????//收到關于監聽套接字的通知,意味著一盒或者多個傳入連接??
- ????????????????????????struct?sockaddr?in_addr;??
- ????????????????????????socklen_t?in_len?=?sizeof(in_addr);??
- ????????????????????????if(accept(sock_fd,?&in_addr,?&in_len)?<?0){??
- ????????????????????????????printf("process?%d?accept?failed!\n",?getpid());??
- ????????????????????????}else{??
- ????????????????????????????printf("process?%d?accept?successful!\n",?getpid());??
- ????????????????????????}??
- ????????????????????}??
- ????????????????}??
- ????????????}??
- ????????}??
- ????}??
- ????wait(0);??
- ????free(events);??
- ????close(sock_fd);??
- ????return?0;??
- }??
上面的代碼編譯gcc epoll_thunder_herd.c -o server?
一個終端運行代碼 ./server 1234? 另一個終端telnet 127.0.0.1 1234
運行結果:

這里我們看到只有一個進程返回了,似乎并沒有驚群效應,讓我們用strace -f? ./server 8888追蹤執行過程(這里只給出telnet之后的截圖,之前的截圖參考accept,不同的就是進程阻塞在epoll_wait)
截圖(部分):
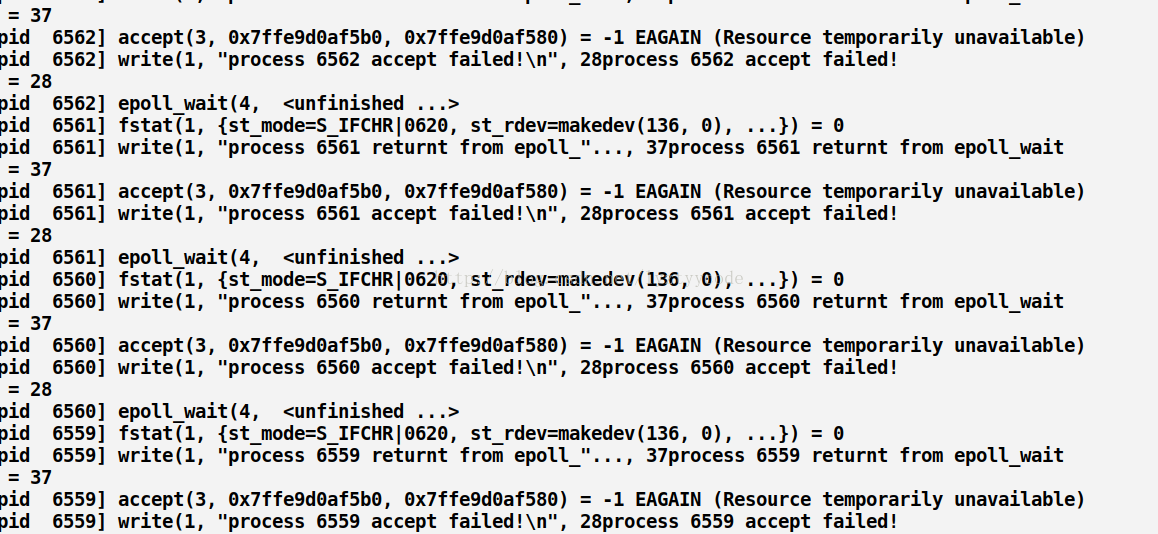
運行結果顯示了部分個進程被喚醒了,返回了“process accept failed”只是后面因為某些原因失敗了。所以這里貌似存在部分“驚群”。
怎么判斷發生了驚群呢?
我們根據strace的返回信息可以確定:
1)系統只會讓一個進程真正的接受這個連接,而剩余的進程會獲得一個EAGAIN信號。圖中有體現。
2)通過返回結果和進程執行的系統調用判斷。
這究竟是什么原因導致的呢?
看我們的代碼,看似部分進程被喚醒了,而事實上其余進程沒有被喚醒的原因是因為某個進程已經處理完這個事件,無需喚醒其他進程,你可以在epoll獲知這個事件的時候sleep(2);這樣所有的進程都會被喚起。看下面改正后的代碼結果更加清晰:
代碼修改:
- num?=?epoll_wait(epoll_fd,?events,?MAXEVENTS,?-1);??
- printf("process?%d?returnt?from?epoll_wait\n",?getpid());??
- sleep(2);??
運行結果:

如圖所示:所有的進程都被喚醒了。所以epoll_wait的驚群確實存在。
為什么內核處理了accept的驚群,卻不處理epoll_wait的驚群呢?
accept確實應該只能被一個進程調用成功,內核很清楚這一點。但epoll不一樣,他監聽的文件描述符,除了可能后續被accept調用外,還有可能是其他網絡IO事件的,而其他IO事件是否只能由一個進程處理,是不一定的,內核不能保證這一點,這是一個由用戶決定的事情,例如可能一個文件會由多個進程來讀寫。所以,對epoll的驚群,內核則不予處理。
*3)線程驚群:
- printf("初始的紅包情況:<個數:%d??金額:%d.%02d>\n",item.number,?item.total/100,?item.total%100);??
- pthread_cond_broadcast(&temp.cond);//紅包包好后喚醒所有線程搶紅包??
- pthread_mutex_unlock(&temp.mutex);//解鎖??
- sleep(1);??
4.我們怎么解決“驚群”呢?你有什么高見?
(1)、Nginx的解決:
- void?ngx_process_events_and_timers(ngx_cycle_t?*cycle)??
- {??
- ????...?...??
- ????//?是否通過對accept加鎖來解決驚群問題,需要工作線程數>1且配置文件打開accetp_mutex??
- ????if?(ngx_use_accept_mutex)?{??
- ????????//?超過配置文件中最大連接數的7/8時,該值大于0,此時滿負荷不會再處理新連接,簡單負載均衡??
- ????????if?(ngx_accept_disabled?>?0)?{??
- ????????????ngx_accept_disabled--;??
- ????????}?else?{??
- ????????????//?多個worker僅有一個可以得到這把鎖。獲取鎖不會阻塞過程,而是立刻返回,獲取成功的話??
- ????????????//?ngx_accept_mutex_held被置為1。拿到鎖意味著監聽句柄被放到本進程的epoll中了,如果??
- ????????????//?沒有拿到鎖,則監聽句柄會被從epoll中取出。??
- ????????????if?(ngx_trylock_accept_mutex(cycle)?==?NGX_ERROR)?{??
- ????????????????return;??
- ????????????}??
- ????????????if?(ngx_accept_mutex_held)?{??
- ????????????????//?此時意味著ngx_process_events()函數中,任何事件都將延后處理,會把accept事件放到??
- ????????????????//?ngx_posted_accept_events鏈表中,epollin|epollout事件都放到ngx_posted_events鏈表中??
- ????????????????flags?|=?NGX_POST_EVENTS;??
- ????????????}?else?{??
- ????????????????//?拿不到鎖,也就不會處理監聽的句柄,這個timer實際是傳給epoll_wait的超時時間,修改??
- ????????????????//?為最大ngx_accept_mutex_delay意味著epoll_wait更短的超時返回,以免新連接長時間沒有得到處理??
- ????????????????if?(timer?==?NGX_TIMER_INFINITE?||?timer?>?ngx_accept_mutex_delay)?{??
- ????????????????????timer?=?ngx_accept_mutex_delay;??
- ????????????????}??
- ????????????}??
- ????????}??
- ????}??
- ????...?...??
- ????(void)?ngx_process_events(cycle,?timer,?flags);???//?實際調用ngx_epoll_process_events函數開始處理??
- ????...?...??
- ????if?(ngx_posted_accept_events)?{?//如果ngx_posted_accept_events鏈表有數據,就開始accept建立新連接??
- ????????ngx_event_process_posted(cycle,?&ngx_posted_accept_events);??
- ????}??
- ??
- ????if?(ngx_accept_mutex_held)?{?//釋放鎖后再處理下面的EPOLLIN?EPOLLOUT請求??
- ????????ngx_shmtx_unlock(&ngx_accept_mutex);??
- ????}??
- ??
- ????if?(delta)?{??
- ????????ngx_event_expire_timers();??
- ????}??
- ??
- ????ngx_log_debug1(NGX_LOG_DEBUG_EVENT,?cycle->log,?0,?"posted?events?%p",?ngx_posted_events);??
- ????//?然后再處理正常的數據讀寫請求。因為這些請求耗時久,所以在ngx_process_events里NGX_POST_EVENTS標??
- ????//?志將事件都放入ngx_posted_events鏈表中,延遲到鎖釋放了再處理。??
- }}??
(2)、SO_REUSEPORT
Linux內核的3.9版本帶來了SO_REUSEPORT特性,該特性支持多個進程或者線程綁定到同一端口,提高服務器程序的性能,允許多個套接字bind()以及listen()同一個TCP或UDP端口,并且在內核層面實現負載均衡。
在未開啟SO_REUSEPORT的時候,由一個監聽socket將新接收的連接請求交給各個工作者處理,看圖示:


運行在Linux系統上的網絡應用程序,為了利用多核的優勢,一般使用以下典型的多進程(多線程)服務器模型:
1.單線程listener/accept,多個工作線程接受任務分發,雖然CPU工作負載不再成為問題,但是仍然存在問題:
? ? ?? (1)、單線程listener(圖一),在處理高速率海量連接的時候,一樣會成為瓶頸
? ? ? ? (2)、cpu緩存行丟失套接字結構現象嚴重。
2.所有工作線程都accept()在同一個服務器套接字上呢?一樣存在問題:
? ? ? ? (1)、多線程訪問server socket鎖競爭嚴重。
? ? ? ? (2)、高負載情況下,線程之間的處理不均衡,有時高達3:1。
? ? ? ? (3)、導致cpu緩存行跳躍(cache line bouncing)。
? ? ? ? (4)、在繁忙cpu上存在較大延遲。
上面兩種方法共同點就是很難做到cpu之間的負載均衡,隨著核數的提升,性能并沒有提升。甚至服務器的吞吐量CPS(Connection Per Second)會隨著核數的增加呈下降趨勢。
下面我們就來看看SO_REUSEPORT解決了什么問題:
? ? ? ? (1)、允許多個套接字bind()/listen()同一個tcp/udp端口。每一個線程擁有自己的服務器套接字,在服務器套接字上沒有鎖的競爭。
? ? ? ? (2)、內核層面實現負載均衡
? ? ? ? (3)、安全層面,監聽同一個端口的套接字只能位于同一個用戶下面。
? ? ? ? (4)、處理新建連接時,查找listener的時候,能夠支持在監聽相同IP和端口的多個sock之間均衡選擇。
當一個連接到來的時候,系統到底是怎么決定那個套接字來處理它?
對于不同內核,存在兩種模式,這兩種模式并不共存,一種叫做熱備份模式,另一種叫做負載均衡模式,3.9內核以后,全部改為負載均衡模式。
熱備份模式:一般而言,會將所有的reuseport同一個IP地址/端口的套接字掛在一個鏈表上,取第一個即可,工作的只有一個,其他的作為備份存在,如果該套接字掛了,它會被從鏈表刪除,然后第二個便會成為第一個。
負載均衡模式:和熱備份模式一樣,所有reuseport同一個IP地址/端口的套接字會掛在一個鏈表上,你也可以認為是一個數組,這樣會更加方便,當有連接到來時,用數據包的源IP/源端口作為一個HASH函數的輸入,將結果對reuseport套接字數量取模,得到一個索引,該索引指示的數組位置對應的套接字便是工作套接字。這樣就可以達到負載均衡的目的,從而降低某個服務的壓力。
)







)
![Python a和a[:]的區別](http://pic.xiahunao.cn/Python a和a[:]的區別)
)

 -- RTTI:運行時類型識別)






