目錄
1、簡介
2、?為什么需要特征工程
3、特征抽取
3.1、簡介
3.2、特征提取主要內容
3.3、字典特征提取
3.4、"one-hot"編碼
3.5、文本特征提取
3.5.1、英文文本
3.5.2、結巴分詞
3.5.3、中文文本
3.5.4、Tf-idf
?所屬專欄:人工智能
文中提到的代碼如有需要可以私信我發給你噢😊
1、簡介
特征工程是使用專業背景知識和技巧處理數據,使得特征能在機器學習算法上發揮更好的作用的過程。
意義:會直接影響機器學習的效果
特征工程是機器學習中至關重要的一步,它涉及將原始數據轉換為適合機器學習模型的特征(也稱為變量或屬性)。好的特征工程可以顯著提高模型性能,因為它能夠揭示數據中的有用信息,降低噪音影響,甚至幫助模型更好地泛化到新數據。
特征工程包含內容
- 特征抽取
- 特征預處理
- 特征降維
以下是特征工程的一些常見方法和技巧:
- 特征選擇(Feature Selection):從原始特征集中選擇最相關、最有用的特征,以降低模型的復雜性和過擬合風險。
- 特征提取(Feature Extraction):通過數學變換,將原始特征轉換為更具信息量的特征,例如主成分分析(PCA)、獨立成分分析(ICA)等。
- 特征轉換(Feature Transformation):對原始特征進行變換,以使其更適合模型,如對數、指數、歸一化、標準化等。
- 多項式特征擴展(Polynomial Feature Expansion):將原始特征的多項式組合添加到特征集中,以捕獲特征之間的非線性關系。
- 時間序列特征處理:針對時間序列數據,可以提取滯后特征(lag features)、移動平均、指數加權移動平均等。
- 文本特征處理:對文本數據進行詞袋模型(Bag-of-Words)、TF-IDF(Term Frequency-Inverse Document Frequency)處理,或者使用詞嵌入(Word Embeddings)等技術。
- 類別特征編碼:將類別型特征轉換為數值型特征,例如獨熱編碼(One-Hot Encoding)、標簽編碼(Label Encoding)等。
- 缺失值處理:處理缺失值的方法包括刪除含有缺失值的樣本、填充缺失值、使用模型預測缺失值等。
- 特征交互與組合:通過對特征進行交互、組合,創建新的特征來捕獲更高級的信息。
- 數據降維:使用降維技術(如PCA)減少數據維度,以減少計算復雜性和噪音的影響。
- 領域知識引導:利用領域專業知識來設計和選擇特征,以更好地捕獲問題的本質。
在進行特征工程時,需要注意以下幾點:
- 理解數據:深入了解數據的含義、結構和背景,以便做出更明智的特征工程決策。
- 避免過擬合:特征工程可能導致過擬合問題,因此需要謹慎選擇和處理特征。
- 實驗和迭代:嘗試不同的特征工程方法,并使用交叉驗證等技術來評估模型性能,以確定哪些方法有效。
- 自動化:一些自動化特征選擇和提取工具可以幫助你快速嘗試不同的特征工程技術。
總之,特征工程是機器學習中一個關鍵且有創造性的階段,它能夠顯著影響模型的性能和泛化能力。
2、?為什么需要特征工程
機器學習領域的大神Andrew Ng(吳恩達)老師說“Coming up with features is difficult, time-consuming, requires expert knowledge. “Applied machine learning” is basically feature engineering. ”
業界廣泛流傳:數據和特征決定了機器學習的上限,而模型和算法只是逼近這個上限而已。
以下是特征工程的重要性和原因:
- 提取有用信息:原始數據可能包含大量的冗余或無關信息,特征工程能夠通過選擇、提取或轉換特征,從中抽取出對問題有用的信息,提高模型的預測能力。
- 降低維度:某些問題可能涉及大量的特征,而高維度數據會導致計算成本的增加和過擬合的風險。特征工程可以通過降維技術(如主成分分析)減少數據維度,從而提高模型效率和泛化性能。
- 改善模型泛化:好的特征工程有助于降低模型在新數據上的錯誤率,提高模型的泛化能力,使其能夠更好地適應未見過的數據。
- 處理缺失值和異常值:特征工程可以幫助處理數據中的缺失值和異常值,選擇合適的填充策略或移除異常值,從而減少對模型的不良影響。
- 解決非線性關系:原始數據可能包含復雜的非線性關系,特征工程可以通過多項式特征擴展、特征交互和轉換等方法,使模型能夠更好地捕獲這些關系。
- 提高模型解釋性:通過特征工程,可以將數據轉換為更易解釋的形式,使模型的預測結果更具可解釋性,有助于理解模型的決策依據。
- 適應不同模型:不同的機器學習模型對特征的需求不同,通過特征工程,可以根據模型的特點和假設來調整特征,提高模型性能。
- 利用領域知識:特征工程可以融入領域專業知識,根據問題背景和領域特點,選擇和設計適用的特征,更好地捕獲數據的本質。
總之,特征工程是機器學習流程中的關鍵步驟,它可以幫助我們將原始數據轉化為更有意義、更適合模型的特征,從而提高模型的性能、泛化能力和解釋性。特征工程的好壞直接影響著模型的效果,因此在實際應用中,合適的特征工程往往能夠為機器學習任務帶來顯著的提升。
3、特征抽取
3.1、簡介
特征抽取(Feature Extraction)是指從原始數據中自動或半自動地提取出具有代表性和信息豐富度的特征,以用于機器學習和數據分析任務。在特征抽取過程中,原始數據的維度可能會被降低,從而減少計算成本并提高模型的性能和泛化能力。
特征抽取的目標是將原始數據轉換為更具有判別性和表達力的特征表示,以便更好地捕獲數據中的模式、關系和變異。這有助于提高模型的訓練效果,并且可以使模型更好地適應新的未見過的數據。
特征抽取的方法可以包括以下幾種:
- 主成分分析(PCA):PCA是一種降維技術,通過線性變換將原始特征投影到一個新的坐標系中,使得投影后的特征具有最大的方差。這樣可以將數據的維度減少,同時保留最重要的信息。
- 獨立成分分析(ICA):ICA是一種用于提取獨立信號的技術,適用于信號分離和降噪等場景,可以用于音頻處理、圖像處理等領域。
- 特征選擇器(Feature Selectors):通過選擇最相關或最重要的特征來降低維度,例如選擇方差較大的特征、基于統計方法的特征選擇等。
- 詞袋模型(Bag-of-Words):在自然語言處理中,將文本數據轉換為一個表示每個單詞頻次的向量,從而構建文本的特征表示。
- 傅里葉變換(Fourier Transform):用于將信號從時間域轉換到頻率域,常用于信號處理和圖像處理領域。
- 小波變換(Wavelet Transform):類似于傅里葉變換,但可以同時提供時間和頻率信息,適用于分析非平穩信號。
- 自編碼器(Autoencoders):是一種神經網絡結構,通過訓練模型來學習數據的低維表示,常用于無監督學習任務。
特征抽取的選擇取決于問題的性質、數據的類型以及任務的要求。它在處理高維數據、降低計算成本、提高模型泛化能力等方面具有重要作用,是特征工程的一個關鍵組成部分。
3.2、特征提取主要內容
1、將任意數據(如文本或圖像)轉換為可用于機器學習的數字特征
特征值化是為了計算機更好的去理解數據
- 字典特征提取(特征離散化)
- 文本特征提取
- 圖像特征提取(深度學習將介紹)
2、特征提取API:sklearn.feature_extraction
3.3、字典特征提取
作用:對字典數據進行特征值化
sklearn.feature_extraction.DictVectorizer(sparse=True,…)
DictVectorizer.fit_transform(X) X:字典或者包含字典的迭代器返回值:返回sparse矩陣
DictVectorizer.inverse_transform(X) X:array數組或者sparse矩陣 返回值:轉換之前數據格式
DictVectorizer.get_feature_names() 返回類別名稱
from sklearn.feature_extraction import DictVectorizer # 實例化'''
sklearn.feature_extraction.DictVectorizer(sparse=True,…)DictVectorizer.fit_transform(X) X:字典或者包含字典的迭代器返回值:返回sparse矩陣DictVectorizer.inverse_transform(X) X:array數組或者sparse矩陣 返回值:轉換之前數據格式DictVectorizer.get_feature_names() 返回類別名稱
'''
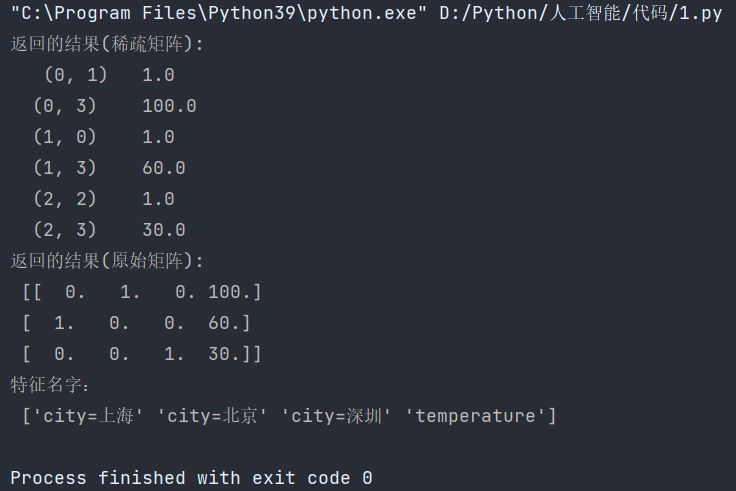
def dict_demo():"""對字典類型的數據進行特征抽取:return: None"""data = [{'city': '北京', 'temperature': 100},{'city': '上海', 'temperature': 60},{'city': '深圳', 'temperature': 30}]# 1、實例化一個轉換器類transfer1 = DictVectorizer(sparse=False)transfer2 = DictVectorizer()# 2、調用fit_transformdata2 = transfer2.fit_transform(data)data1 = transfer1.fit_transform(data)print("返回的結果(稀疏矩陣):\n", data2)print("返回的結果(原始矩陣):\n", data1)# 打印特征名字print("特征名字:\n", transfer1.get_feature_names_out())if __name__ == '__main__':dict_demo()結果:
3.4、"one-hot"編碼
"One-Hot"編碼是一種常用的分類變量(也稱為類別變量、離散變量)到數值變量的轉換方法,用于將類別型數據表示為二進制向量的形式。這種編碼方法在機器學習中廣泛應用于處理類別型特征,以便將其用于各種算法和模型中。
在"One-Hot"編碼中,每個類別被轉換為一個唯一的二進制向量,其中只有一個元素為1,其余元素為0。這個元素的位置表示類別的索引或標簽。這樣做的目的是消除類別之間的順序關系,以及用離散的0和1表示類別信息,使算法能夠更好地處理類別型特征。
以下是一個簡單的示例來解釋"One-Hot"編碼:
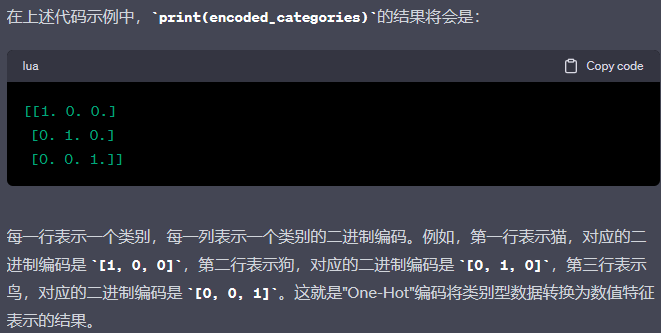
假設我們有一個表示動物種類的類別特征,包括貓、狗和鳥。"One-Hot"編碼將這三個類別轉化為如下形式的向量:
- 貓:[1, 0, 0]
- 狗:[0, 1, 0]
- 鳥:[0, 0, 1]
這樣,每個類別都被表示為一個唯一的二進制向量,其中對應的位置為1,其余位置為0。
在Python中,可以使用各種工具和庫來進行"One-Hot"編碼,其中最常用的是Scikit-Learn(sklearn)庫的OneHotEncoder類。
以下是一個簡單的代碼示例:
from sklearn.preprocessing import OneHotEncoder# 創建OneHotEncoder對象
encoder = OneHotEncoder()# 假設有一個包含動物種類的數組
animal_categories = [['貓'], ['狗'], ['鳥']]# 進行One-Hot編碼
encoded_categories = encoder.fit_transform(animal_categories).toarray()# 打印編碼結果
print(encoded_categories)結果:
3.5、文本特征提取
作用:對文本數據進行特征值化
sklearn.feature_extraction.text.CountVectorizer(stop_words=[]) 返回詞頻矩陣
CountVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代對象 返回值:返回sparse矩陣
CountVectorizer.inverse_transform(X) X:array數組或者sparse矩陣 返回值:轉換之前數據格
CountVectorizer.get_feature_names() 返回值:單詞列表
sklearn.feature_extraction.text.TfidfVectorizer
3.5.1、英文文本
下面對以下文本進行分析:["life is short,i like python","life is too long,i dislike python"]
流程分析:
實例化類CountVectorizer
調用fit_transform方法輸入數據并轉換 (注意返回格式,利用toarray()進行sparse矩陣轉換array數組)
from sklearn.feature_extraction.text import CountVectorizer # 文本特征提取'''
sklearn.feature_extraction.text.CountVectorizer(stop_words=[]) 返回詞頻矩陣CountVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代對象 返回值:返回sparse矩陣CountVectorizer.inverse_transform(X) X:array數組或者sparse矩陣 返回值:轉換之前數據格CountVectorizer.get_feature_names() 返回值:單詞列表sklearn.feature_extraction.text.TfidfVectorizer
'''
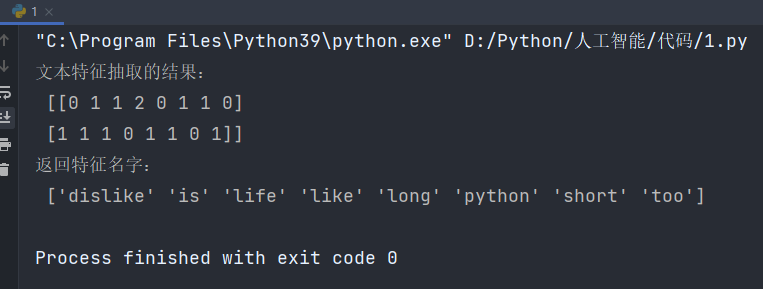
def text_count_demo():"""對文本進行特征抽取,countvetorizer:return: None"""data = ["life is short,i like like python","life is too long,i dislike python"]# 1、實例化一個轉換器類transfer = CountVectorizer()# 2、調用fit_transformdata = transfer.fit_transform(data)print("文本特征抽取的結果:\n", data.toarray())print("返回特征名字:\n", transfer.get_feature_names_out())if __name__ == '__main__':text_count_demo()輸出結果:
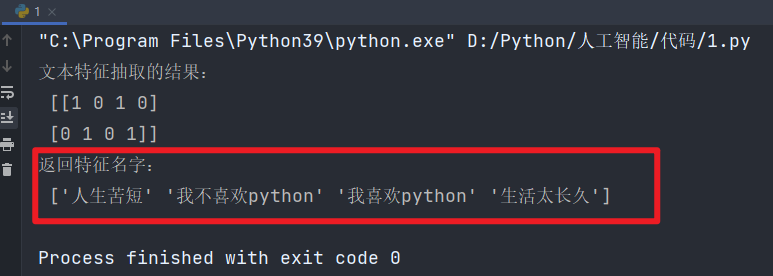
🔺如果替換成中文,則會出問題:"人生苦短,我喜歡Python" "生活太長久,我不喜歡Python"
為什么會得到這樣的結果呢,仔細分析之后會發現英文默認是以空格分開的。
其實就達到了一個分詞的效果,所以我們要對中文進行分詞處理。
這里需要用到“結巴分詞”
3.5.2、結巴分詞
結巴分詞(jieba)是一個流行的中文文本分詞工具,被廣泛應用于自然語言處理(NLP)任務中,如文本分析、信息檢索、情感分析、機器翻譯等。結巴分詞是基于Python開發的開源項目,它提供了一種可靠高效的中文分詞解決方案。
以下是結巴分詞的一些特點和功能:
- 中文分詞:結巴分詞可以將中文文本切分成一個一個有意義的詞語(詞匯),從而為后續的文本處理和分析提供基礎。
- 支持多種分詞模式:結巴分詞提供了不同的分詞模式,包括精確模式、全模式、搜索引擎模式等,以適應不同的分詞需求。
- 支持用戶自定義詞典:用戶可以根據需要添加自定義的詞典,用于識別領域特定的術語、詞匯,從而提高分詞的準確性。
- 高性能:結巴分詞在分詞速度上表現出色,可以處理大規模的文本數據。
- 支持繁體字分詞:除了簡體中文,結巴分詞還支持繁體中文文本的分詞。
- 詞性標注:結巴分詞可以對分詞結果進行詞性標注,幫助識別每個詞語的詞性,如名詞、動詞等。
- 適應多種任務:結巴分詞不僅可以用于分詞,還可以用于關鍵詞提取、文本去重、文本相似度計算等任務。
3.5.3、中文文本
案例分析:
對以下三句話進行特征值化:
今天很殘酷,明天更殘酷,后天很美好,
但絕對大部分是死在明天晚上,所以每個人不要放棄今天。
我們看到的從很遠星系來的光是在幾百萬年之前發出的,
這樣當我們看到宇宙時,我們是在看它的過去。
如果只用一種方式了解某樣事物,你就不會真正了解它。
了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系。
分析:
準備句子,利用jieba.cut進行分詞
實例化CountVectorizer
將分詞結果變成字符串當作fit_transform的輸入值
from sklearn.feature_extraction.text import CountVectorizer # 文本特征提取
import jieba # 結巴分詞'''
使用結巴分詞,對中文特征進行提取
'''
def text_chinese_count_demo2():"""對中文進行特征抽取:return: None"""data = ["一種還是一種今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天。","我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去。","如果只用一種方式了解某樣事物,你就不會真正了解它。了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系。"]# 將原始數據轉換成分好詞的形式text_list = []for sent in data:text_list.append(" ".join(list(jieba.cut(sent)))) # 這里使用結巴分詞print(text_list)# 1、實例化一個轉換器類# transfer = CountVectorizer(sparse=False)transfer = CountVectorizer()# 2、調用fit_transformdata = transfer.fit_transform(text_list)print("文本特征抽取的結果:\n", data.toarray())print("返回特征名字:\n", transfer.get_feature_names_out())if __name__ == '__main__':text_chinese_count_demo2()結果:

但如果把這樣的詞語特征用于分類,會出現什么問題?
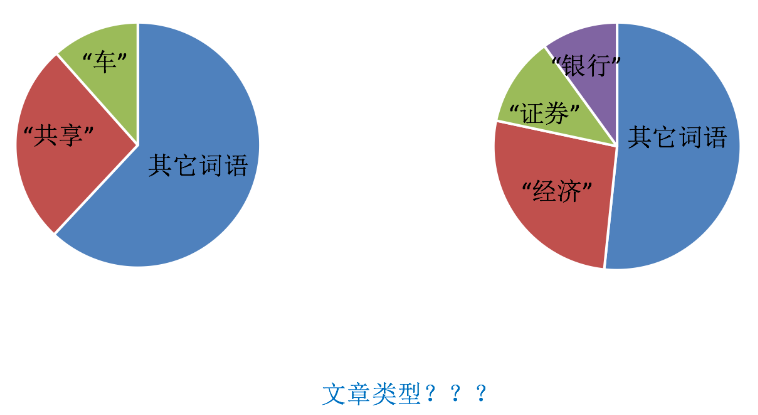
該如何處理某個詞或短語在多篇文章中出現的次數高這種情況?
這種情況下,我們需要用到"Tf-idf文本特征提取"。
3.5.4、Tf-idf

TF-IDF(Term Frequency-Inverse Document Frequency)是一種常用的文本特征提取方法,用于將文本數據轉換為數值特征表示,以便用于機器學習和信息檢索任務。
TF-IDF反映了一個詞在文本中的重要性,同時考慮了詞頻和文檔頻率的影響。
TF-IDF文本特征提取的原理如下:
- 詞頻(Term Frequency,TF):表示一個詞在一篇文檔中出現的頻率。計算方法為:一個詞在文檔中出現的次數除以文檔的總詞數。
- 逆文檔頻率(Inverse Document Frequency,IDF):表示一個詞在所有文檔中的普遍程度。計算方法為:總文件數目除以包含該詞語之文件的數目,再將得到的商取以10為底的對數。IDF的目的是降低常見詞對文檔區分能力的影響。
- TF-IDF:將詞頻和逆文檔頻率相乘,得到一個詞在文檔中的重要性得分。高頻出現但在其他文檔中不常見的詞,得分會相對較高。
公式:

TF-IDF的優點在于它可以凸顯文本中的關鍵詞,過濾掉一些無意義的常見詞,并為文本賦予數值特征,使得文本數據適用于各種機器學習算法。
案例:
from sklearn.feature_extraction.text import TfidfVectorizer # TF-IDF特征提取
import jieba # 結巴分詞'''
提取TF-IDF特征
'''
def text_chinese_tfidf_demo():"""對中文進行特征抽取:return: None"""data = ["一種還是一種今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天。","我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去。","如果只用一種方式了解某樣事物,你就不會真正了解它。了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系。"]# 將原始數據轉換成分好詞的形式text_list = []for sent in data:text_list.append(" ".join(list(jieba.cut(sent)))) # 這里使用結巴分詞print(text_list)transfer = TfidfVectorizer(stop_words=['一種', '不會', '不要'])# 2、調用fit_transformdata = transfer.fit_transform(text_list)print("文本特征抽取的結果:\n", data.toarray())print("返回特征名字:\n", transfer.get_feature_names_out())if __name__ == '__main__':text_chinese_tfidf_demo()TF-IDF特征提取如下:
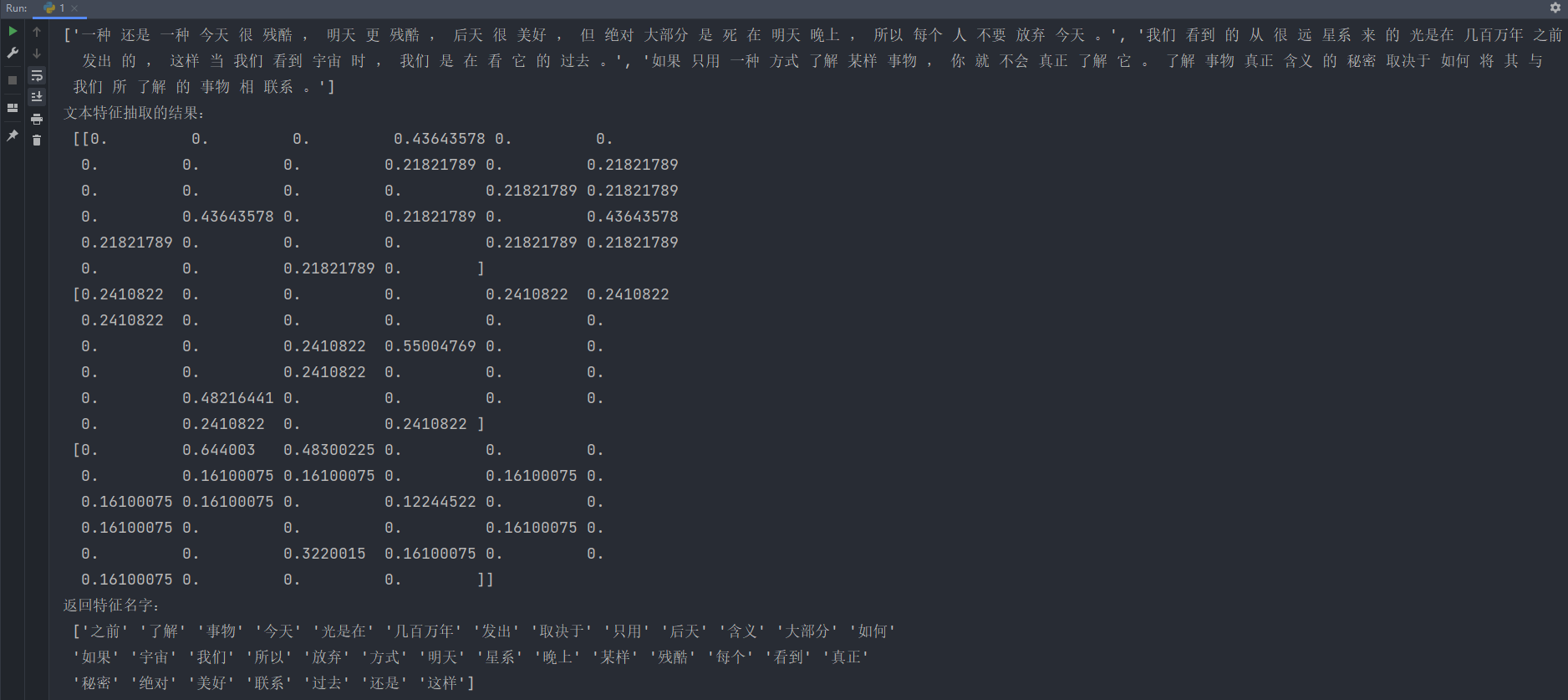
這段輸出表示TF-IDF文本特征抽取的結果,是一個特征矩陣,其中每一行代表一個文本樣本,每一列表示一個單詞的TF-IDF得分。
TF-IDF(詞頻-逆文檔頻率)是一種用于衡量一個詞在文本中的重要性的指標,結合了詞頻(TF)和逆文檔頻率(IDF)。TF-IDF越高,說明該詞在當前文本中越重要且越不常見于其他文本。
以下是對輸出矩陣的解釋:
- 第一行:表示第一篇文本樣本的TF-IDF特征向量。特征向量中的每個元素表示對應單詞的TF-IDF得分。例如,"今天"的TF-IDF得分是0.43643578,"很"的得分是0.21821789。
- 第二行:表示第二篇文本樣本的TF-IDF特征向量。例如,"我們"的TF-IDF得分是0.2410822,"光"的得分是0.55004769。
- 第三行:表示第三篇文本樣本的TF-IDF特征向量。例如,"了解"的TF-IDF得分是0.644003,"事物"的得分是0.3220015。
在這個特征矩陣中,每一行表示一個文本樣本,每一列對應一個單詞(詞匯表中的詞)。
每個元素表示對應單詞在對應文本中的TF-IDF得分。
這個矩陣將文本數據轉換為數值特征表示,可以作為機器學習算法的輸入。
通常情況下,為了方便理解,這些得分會在實際應用中進行歸一化或者規范化處理。
Tf-idf的重要性:分類機器學習算法進行文章分類中前期數據處理方式












![[足式機器人]Part5 機械設計 Ch00/01 緒論+機器結構組成與連接 ——【課程筆記】](http://pic.xiahunao.cn/[足式機器人]Part5 機械設計 Ch00/01 緒論+機器結構組成與連接 ——【課程筆記】)

)



 UI控件之Button (按鈕)與 ImageButton (圖像按鈕))
