對于 BOSS 直聘這種網站,當程序請求網頁后,服務器響應內容包含了整個頁面的 HTML 源代碼,這樣就可以使用爬蟲來爬取數據。但有些網站做了一些“反爬蟲”處理,其網頁內容不是靜態的,而是使用 JavaScript 動態加載的,此時的爬蟲程序也需要做相應的改進。
使用 shell 調試工具分析目標站點
本項目爬取的目標站點是 https://unsplash.com/,該網站包含了大量高清、優美的圖片。本項目的目標是爬蟲程序能自動識別并下載該網站上的所有圖片。
在開發該項目之前,依然先使用 Firefox 瀏覽該網站,然后查看該網站的源代碼,將會看到頁面的
元素幾乎是空的,并沒有包含任何圖片。現在使用 Scrapy 的 shell 調試工具來看看該頁面的內容。在控制臺輸入如下命令,啟動 shell 調試:
scrapy shell https://unsplash.com/
執行上面命令,可以看到 Scrapy 成功下載了服務器響應數據。接下來,通過如下命令來嘗試獲取所有圖片的 src 屬性(圖片都是 img 元素,src 屬性指定了圖片的 URL):
response.xpath('//img/@src').extract()
執行上面命令,將會看到返回一系列圖片的URL,但它們都不是高清圖片的 URL。
還是通過"Ctrl+Shift+I"快捷鍵打開 Firefox 的調試控制臺,再次向 https://unsplash.com/ 網站發送請求,接下來可以在 Firefox 的調試控制臺中看到如圖 1 所示的請求。
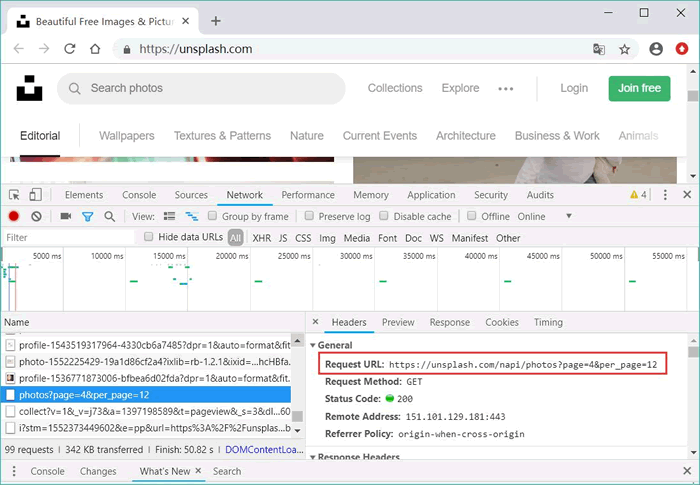
圖 1 動態獲取圖片的請求
可見,該網頁動態請求圖片的 URL 如下:
https://unsplash.com/napi/photos?page=4&per_page=12
上面 URL 中的 page 代表第幾頁,per_page 代表每頁加載的圖片數。使用 Scrapy 的 shell 調試工具來調試該網址,輸入如下命令:
scrapy shell https://unsplash.com/napi/photos?page=1&per_page=10
上面命令代表請求第 1 頁,每頁顯示 10 張圖片的響應數據。執行上面命令,服務器響應內容是一段 JSON 數據,接下來在 shell 調試工具中輸入如下命令:
>>> import json
>>> len(json.loads(response.text))
10
從上面的調試結果可以看到,服務器響應內容是一個 JSON 數組(轉換之后對應于 Python 的 list 列表),且該數組中包含 10 個元素。
使用 Firefox 直接請求 https://unsplash.com/napi/photos?page=1&per_page=12 地址(如果希望使用更專業的工具,則可選擇 Postman),可以看到服務器響應內容如圖 2 所示。
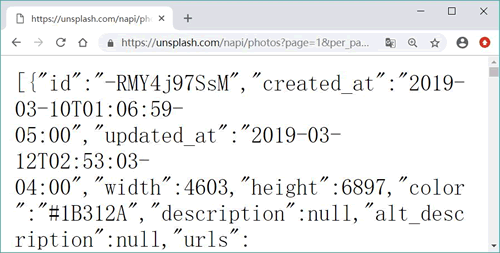
圖 2 服務器響應的JSON 數據
在圖 2 所示為所有圖片的 JSON 數據,每張圖片數據都包含 id、created_at(創建時間)、updated_at(更新時間)、width(圖片寬度)、height(圖片高度)等基本信息和一個 links 屬性,該屬性值是一個對象(轉換之后對應于 Python 的 dict),它包含了 self、html、download、download_location 屬性,其中 self 代表瀏覽網頁時的圖片的 URL;而 download 才是要下載的高清圖片的 URL。
網絡爬蟲畢竟是針對別人的網站“爬取” 數據的,而目標網站的結構隨時可能發生改變,讀者應該學習這種分析方法,而不是“生搬硬套”照抄本節的分析結果。
嘗試在 shell 調試工具中查看第一張圖片的下載 URL,應該在 shell 調試工具中輸入如下命令:
>>> json.loads(response.text)[0]['links']['download']
'https://unsplash.com/photos/-RMY4j97SsM/download'
與圖 2 中 JSON 數據對比不難看出,shell 調試工具輸出的第一張圖片的下載 URL 與圖 2 所顯示的第一張圖片的下載 URL 完全相同。
由此得到一個結論,該網頁加載時會自動向 https://unsplash.com/napi/photos?age=N&per_page=N 發送請求,然后根據服務器響應的 JSON 數據來動態加載圖片。
由于該網頁是“瀑布流”設計(所謂“瀑布流”設計,就是網頁沒有傳統的分頁按鈕,而是讓用戶通過滾動條來實現分頁,當用戶向下拖動滾動條時,程序會動態載入新的分頁),
當我們在 Firefox 中拖動滾動條時,可以在 Firefox 的調試控制臺中看到再次向 https://unsplash.com/napi/photos?page=N&per_page=N 發送了請求,
只是 page 參數發生了改變。可見,為了不斷地加載新的圖片,程序只要不斷地向該 URL 發送請求,并改變 page 參數即可。
經過以上分析,下面我們開始正式使用 Scrapy 來實現爬取高清圖片。
使用Scrapy 爬取高清圖片
按照慣例,使用如下命令來創建一個 Scrapy 項目:
scrapy startproject UnsplashimageSpider
然后在命令行窗口中進入 UnsplashlmageSpider 所在的目錄下(不要進入 UnsplashImageSpider\UnsplashImageSpider目錄下),執行如下命令來生成 Spider 類:
scrapy genspider unsplash_image 'unsplash.com
上面兩個命令執行完成之后,一個簡單的 Scrapy 項目就創建好了。
接下來需要修改 UnsplashImageSpider\items.py、UnsplashImageSpider\pipelines.py、UnsplashImageSpider\spiders\unsplash_image.py、UnsplashImageSpider\settings.py 文件,將它們全部改為使用 UTF-8 字符集來保存。
現在按照如下步驟來開發該爬蟲項目:
定義 Item 類。由于本項目的目標是爬取高清圖片,因此其所使用的 Item 類比較簡單,只要保存圖片 id 和圖片下載地址即可。
下面是該項目的 Item 類的代碼:
import scrapy
class ImageItem(scrapy.Item):
# 保存圖片id
image_id = scrapy.Field()
# 保存圖片下載地址
download = scrapy.Field()
上面程序為 Item 類定義了兩個變量,分別用于保存圖片 id 和圖片下載地址。
開發 Spider。開發 Spider 就是指定 Scrapy 發送請求的 URL,并實現 parse(self, response) 方法來解析服務器響應數據。
下面是該項目的 Spider 程序:
import scrapy, json
from UnsplashImageSpider.items import ImageItem
class UnsplashImageSpider(scrapy.Spider):
# 定義Spider的名稱
name = 'unsplash_image'
allowed_domains = ['unsplash.com']
# 定義起始頁面
start_urls = ['https://unsplash.com/napi/photos?page=1&per_page=12']
def __init__ (self):
self.page_index = 1
def parse(self, response):
# 解析服務器響應的JSON字符串
photo_list = json.loads(response.text) # ①
# 遍歷每張圖片
for photo in photo_list:
item = ImageItem()
item['image_id'] = photo['id']
item['download'] = photo['links']['download']
yield item
self.page_index += 1
# 獲取下一頁的鏈接
next_link = 'https://unsplash.com/napi/photos?page='\
+ str(self.page_index) + '&per_page=12'
# 繼續獲取下一頁的圖片
yield scrapy.Request(next_link, callback=self.parse)
上面程序中第 9 行代碼指定的 URL 是本項目爬取的第一個頁面,由于該頁面的響應是一個 JSON 數據,因此程序無須使用 XPath 或 CSS 選擇器來“提取”數據,而是直接使用 json 模塊的 loads() 函數來加載該響應數據即可。
在獲取 JSON 響應數據之后,程序同樣將 JSON 數據封裝成 Item 對象后返回給 Scrapy 引擎。
Spider 到底應該使用 XPath 或 CSS 選擇器來提取響應數據,還是使用 JSON,完全取決于目標網站的響應內容,怎么方便怎么來!總之,提取到數據之后,將數據封裝成 Item 對象后返回給 Scrapy 引擎就對了。
上面程序中倒數第 2 行代碼定義了加載下一頁數據的 URL,接下來使用 scrapy.Request 向該 URL 發送請求,并指定使用 self.parse 方法來處理服務器響應內容,這樣程序就可以不斷地請求下一頁的圖片數據。
開發 Pipeline。Pipeline 負責保存 Spider 返回的 Item 對象(封裝了爬取到的數據)。本項目爬取的目標是圖片,因此程序得到圖片的 URL 之后,既可將這些 URL 地址導入專門的下載工具中批量下載,也可在 Python 程序中直接下載。
本項目的 Pipeline 將使用 urllib.request 包直接下載。下面是該項目的 Pipeline 程序:
from urllib.request import *
class UnsplashimagespiderPipeline(object):
def process_item(self, item, spider):
# 每個item代表一個要下載的圖片
print('----------' + item['image_id'])
real_url = item['download'] + "?force=true"
try:
pass
# 打開URL對應的資源
with urlopen(real_url) as result:
# 讀取圖片數據
data = result.read()
# 打開圖片文件
with open("images/" + item['image_id'] + '.jpg', 'wb+') as f:
# 寫入讀取的數據
f.write(data)
except:
print('下載圖片出現錯誤' % item['image_id'])
上面程序中第 7 行代碼用于拼接下載圖片的完整地址。可能有讀者會問,為何要在圖片下載地址的后面追加“?force=true”?這并不是本項目所能決定的,讀者可以把鼠標指針移動到 https://unsplash.com 網站中各圖片右下角的下載按鈕上,即可看到各圖片的下載地址都會在 download 后追加“?force=true”,此處只是模擬這種行為而已。
程序中第 11 行代碼使用 urlopen() 函數獲取目標 URL 的數據,接下來即可讀取圖片數據,并將圖片數據寫入下載的目標文件中。
經過上面 3 步,基于 Scrapy 開發的高清圖片爬取程序基本完成。接下來依然需要對 settings.py 文件進行修改,即增加一些自定義請求頭(用于模擬瀏覽器),設置啟用指定的 Pipeline。下面是本項目修改后的 settings.py 文件:
BOT_NAME = 'UnsplashImageSpider'
SPIDER_MODULES = ['UnsplashImageSpider.spiders']
NEWSPIDER_MODULE = 'UnsplashImageSpider.spiders'
ROBOTSTXT_OBEY = True
# 配置默認的請求頭
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
# 配置使用Pipeline
ITEM_PIPELINES = {
'UnsplashImageSpider.pipelines.UnsplashimagespiderPipeline': 300,
}
至此,這個可以爬取高清圖片的爬蟲項目開發完成,讀者可以在 UnsplashlmageSpider 目錄下執行如下命令來啟動爬蟲。
scrapy crawl unsplash_image
#或者
scrapy runspider unsplash_image
區別:
命令
說明
是否需要項目
示例
runspider
未創建項目的情況下,運行一個編寫在Python文件中的spider
no
$ scrapy runspider myspider.py
crawl
使用spider進行爬取
yes
$ scrapy crawl myspider
運行該爬蟲程序之后,可以看到在項目的 images 目錄下不斷地增加新的高清圖片(對圖片的爬取速度在很大程度上取決于網絡下載速度),這些高清圖片正是 https://unsplash.com 網站中所展示的圖片。



形參實參筆試題)

%2.0f打印輸出寬度)




extern聲明可省略變量類型)





運算符優先級使用括號提高閱讀性)


