國產數據庫-內核特性-StarRocks低基數全局字典
StarRocks2.0引入了低基數全局字典,可以通過全局字典將字符串的相關操作轉換成整型相關操作,大大提升查詢性能。
1、低基數字典
對于利用整型替代字符串進行處理,通常使用字典編碼進行優化。StarRocks也是利用這樣的技術。以過濾為例:一個city列,里面有:BJ,SH,GZ,SZ四個字符串,需要從里面過濾city=’BJ’的值,普通操作就需要city整個字段與‘BJ’比較進行匹配;使用字典編碼,將上面的4個字符串依次編碼為:1,2,3,4。那么過濾時僅需city=1進行比較。將字符串比較轉換成整數比較。大多數情況下,整數之間的比較性能會高于字符串的性能。
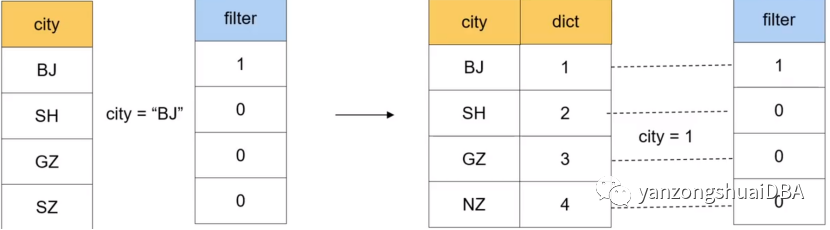
2、局部字典
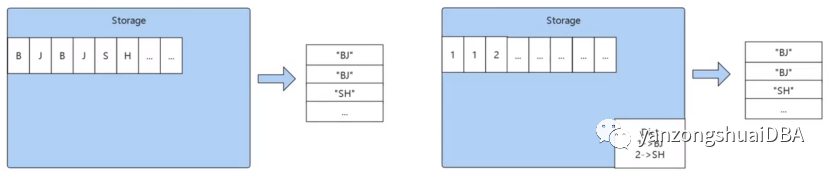
在存儲層進行字典編碼。存儲時并不存儲原有字符串數據,而是將字符串編碼后的值。但是額外會有個元數據,即編碼值與原有字符串之間的映射關系,即字典。寫入和讀取時能夠節省很多IO開銷。
3、全局字典
分布式執行引擎中,一個查詢可能會涉及多個機器多個任務之間數據交換。因此執行過程中需要保證字典全局性。字典數據始終貫穿 SQL 執行的整個生命周期,如果不是全局字典,那么加速只能在局部進行。例如如果兩個執行節點的字典編碼不一致,那么在網絡傳輸過程中需要同時把字典傳給對端機器,或者是需要提前把字典碼轉為字符串再通過網絡發送。如果能保證一個字典的全局性,在網絡傳輸中就可以直接使用字典碼而不再需要傳輸字典。
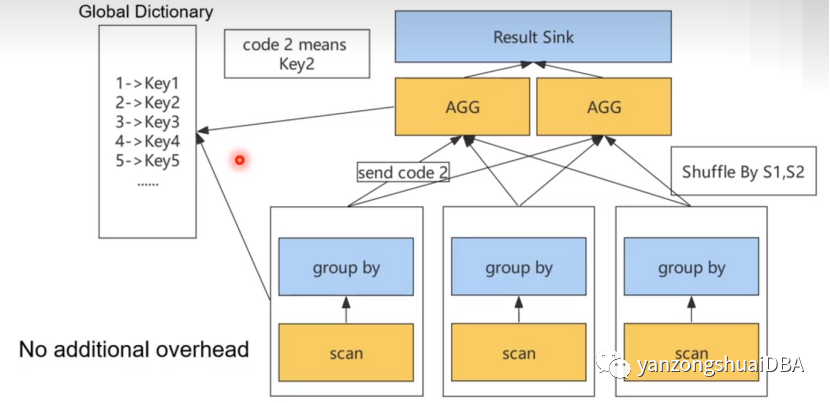
StarRocks中有全局字典,各個節點之間共享同一個字典,那么就不需要發送后再進行解碼并轉換字典碼了。
4、如何構建全局字典
1)建表時定義:

這樣,用戶不友好,并且不易維護。除非用戶數據事先就定義好,數據值比較少,就那么幾個。
2)導入時構建
導入數據時,通過中心節點維護全局字典。每次遇到新的的字符都要通過中心節點創建一個新的字典碼。但是這么做的主要問題是中心節點很容易會成為瓶頸。另外中心節點因為需要同時處理維護并發控制。
因為維護和構建字典對于很多系統來說都是一個比較困難的事情,因此很多系統,只是在局部使用了局部字典來進行加速,并不支持字典的全局加速
3)查詢時構建
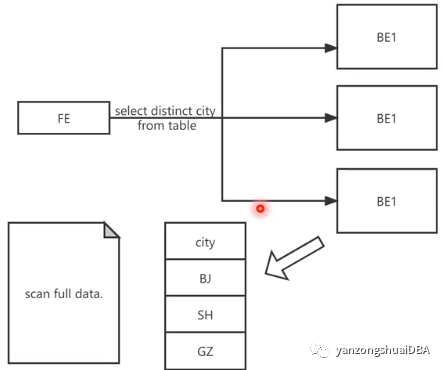
發起一個查詢,就能拿到全量數據,然后對其進行編碼。代價比較高。
4)StarRocks的構建方式
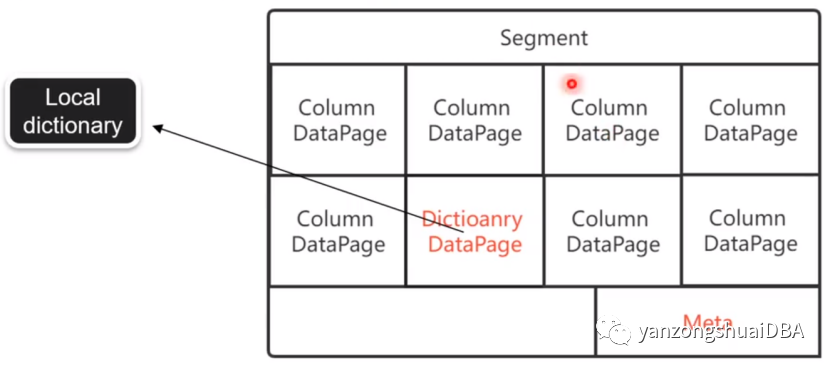
StarRocks 的基本存儲單元為 Segment,每個 Segment 的存儲結構上圖所示。
StarRocks 的存儲結構天然為低基數字符串做了字典編碼。對于 Segment 上的低基數字符串列會有以下特點:Footer 上會存儲有這個 Column 特有的字典信息,包括字典碼跟原始字符串之間的映射關系;Data page 上存儲的不是原始字符串,而是整數類型的字典碼(整型)。當處理低基數 String column 的時候,直接使用編碼后的字典碼,而不是直接處理原始的 String 值。當需要原始的 String 值時,使用字典碼就可以很方便地在這個列的字典信息里面拿到原始 String 值。這么做帶來的明顯好處是:減少了磁盤IO。可以提前做一些過濾操作,提升處理速度。
根據統計信息篩選出低基數的列,并對低基數列進行字典編碼。并不是對所有列進行編碼。
5、全局字典的使用
如果使用了全局字典優化,我們就不需要 SCAN NODE 節點就進行 Decoded,而是可以將原先的局部字典碼(int),直接映射到全局字典中的字典碼(int),并在之后的計算處理過程中,均使用全局字典碼進行處理。當遇到某些特殊的算子,或者是需要具體的依賴字符串內部信息的時候,再按著全局字典的信息,Decoded 出原始的 String 值,這樣可以充分利用到全局字典的加速。
比如select count(*) from lineitem group by l_shipmode;不需要原始字符串值,那么整個執行過程僅使用字典碼即可,而下面的語句select count(*), l_shipmode from lineitem group by l_shipmode;輸出時還需要原始字符串,那么就需要在最后將字典碼轉換成字符串輸出。
優化效果,號稱能夠提升3倍。
6、參考
https://www.bilibili.com/video/BV1ra411N7g8/?spm_id_from=333.337.search-card.all.click&vd_source=10ce859f3f7b1da2094a1283c19fe9b9




)








Servlet容器的自動配置原理)




)
