Redis的核心處理邏輯一直都是單線程?有一些分支模塊是多線程(某些異步流程從4.0開始用的多線程,例如UNLINK、FLUSHALL ASYNC、FLUSHDB ASYNC等非阻塞的刪除操作。網絡I/O解包從6.0開始用的是多線程;)
為什么是單線程
多線程多好啊可以利用多核優勢
官方給的解釋
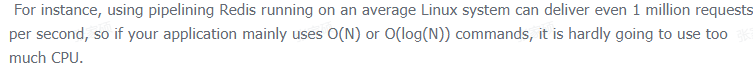
意思就是Redis的定位,是內存k-v存儲, 是做短平快的熱點數據處理,一般來說執行會很快,執行本身不是瓶頸,而瓶頸通常在網絡I/O,處理邏輯多線程并不會有太大收益。
同時,Redis本身 秉持簡潔高效的理念,代碼的簡單性、可維護性 是Redis以來一直以來的追求,引入多線程帶來的復雜性遠比想象的要大,而且多線程本身也會引入額外成本,細說
1.多線程的引入的復雜度很大
1.首先,多線程引入之后,Redis原來的順序執行特性就不復存在,為了支持事務的原子性、隔離性,Redis就不得不引入一些很復雜的實現; .
2.Redis的數據結構極其高效,在單線程模式下做了很多特性的優化,如果引入多線程,那么所有
底層數據結構都要改造為線程安全,這會是極其復雜的工作;
3.而且,多線程模式也使得程序調試更加復雜和麻煩,會帶來額外的開發成本及運營成本,也更容易犯錯(回想一下MYSQL并發....)
2.多線程帶來額外的成本
1.上下文切換成本,多線程調度需要切換線程上下文,這個操作先存儲當前線程的本地數據、程序指針等,然后載入另一個線程數據,這種內核操作的成本不可忽視。
2.同步機制的開銷,-些公共資源,在單線程模式下直接訪問就行了,多線程需要通過加鎖等方式去進行同步,這也是不可忽視的CPU開銷;
3.一個線程本身也占據內存大小,對Redis這種內存數據庫而言,內存非常珍貴,多線程本身帶來的內存使用的成本也需要謹慎決策。
?
單線程為什么這么快
第一,Redis的大部分操作在內存上完成,內存操作本身就特別快;
第二,Redis追求極致,選擇了很多高效的數據結構,并做了非常多的優化,比如ziplist, hash,跳表,有時候一種對象底層有幾種實現以應對不同場景。
第三,Redis 采用了多路復用機制,使其在網絡I0操作中能并發處理大量的客戶端請求,實現高吞吐量。
第一第二點挺好理解的?第三點怎么說
什么叫I/0多路復用,簡單理解來說,就是有I/0操作觸發的時候,就會產生通知,收到通知,再去處理通知對應的事件,針對I/0多路復用,Redis做了一層包裝,叫Reactor模型。
本質就是監聽各種事件,當事件發生時,將事件分發給不同的處理器。
這樣就不會阻塞在某一個操作上,充分發揮性能,可以說I/O多路復用讓Redis單線程也有了較大的并發度,注意這里是并發,而不是并行,在這種模式下,Redis單 核的性能可以說是被充分的利用了。
?
但是呢
現在業務量實在是太大了
前面也有說過,Redis選擇 單線程的核心原因是Redis是都是內存操作,CPU處理都非常快,瓶頸更容易出現在I/O而不是CPU,所以選擇了單線程模型。
隨著時代的發展,很多業務的請求量都達到了一個曾經難以想象的高度,I/O操作確實成為了瓶頸,而之前Redis處理流程中讀取請求、發送回包都屬于I/O操作,所以Redis引入了多線程,這里的多線程也不是說將整個處理邏輯都多線程化,如果這么做,需要對所有數據結構進行線程安全重構,這是巨大的成本,并且,也不見得能有多大提升,甚至可能因為損耗而降低,畢竟瓶頸大多時候都不在處理,瓶頸實際一般都在 于網絡I/O。
因為上述情況,Redis選擇了引入多線程來處理網絡I/O,仍然使用單線程框架來執行Redis命令,這樣既保持了Redis核心的單線程處理架構,完全兼容以前的實現,又引入了多線程解決提升網絡I/O的性能。
?
關于多線程不需要了解太多
首先?多線程是6.0之后引入的?為了解決日益變多的數據量?默認是關閉了?可以在.conf里面修改 多線程負責的是處理網絡I/O?具體來說
讀取并解析指令以及回包。
單線程模式下是一個線程完成讀取、解析、執行、將回包放入客戶端緩沖區;
但在多線程模式下,會將不同的client放 入clients_ pending_ read任務隊列中, 后續會通Round-Robin輪詢負載均衡策略把這些client分給其他IO線程和主線程進行讀取和解析;在回包的時候,也是利用Round-Robin輪詢負 載均衡策略把等待回包隊列中的任務連續均勻地分配給IO線程各自的
本地FIFO任務隊列和主線程自己,主線程輪詢等待所有IO線程完成回包任務
?
)








Servlet容器的自動配置原理)




)

)
)

