文章目錄
- @[TOC](文章目錄)
- 一、操作語句
- 1.增
- 2.刪
- 3.改
- 4.查
- 5.備份
- 二、字符集與校驗規則
文章目錄
- @[TOC](文章目錄)
- 一、操作語句
- 1.增
- 2.刪
- 3.改
- 4.查
- 5.備份
- 二、字符集與校驗規則
一、操作語句
1.增
語句格式:create database [if no exists]數據庫名[create_specification [,create_specification] …];
中括號內是可選項,if no exists是指如果數據庫不存在就創建,存在就不創建,相當于自動查重. create_specification 可以指定數據庫的編碼格式和校驗規則.


2.刪
drop database 數據庫名;
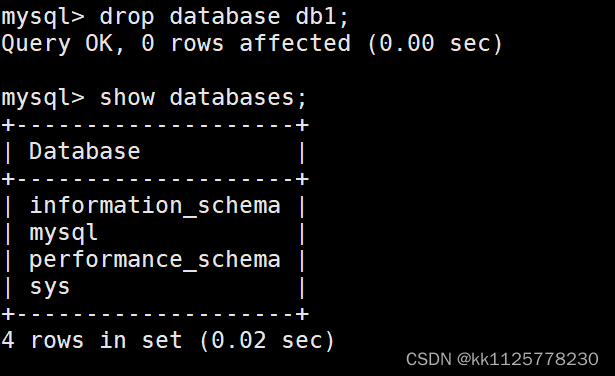
3.改
alter database 數據庫名 指定項;可以更改數據庫指定的字符集

4.查
show databases;可查看所有數據庫
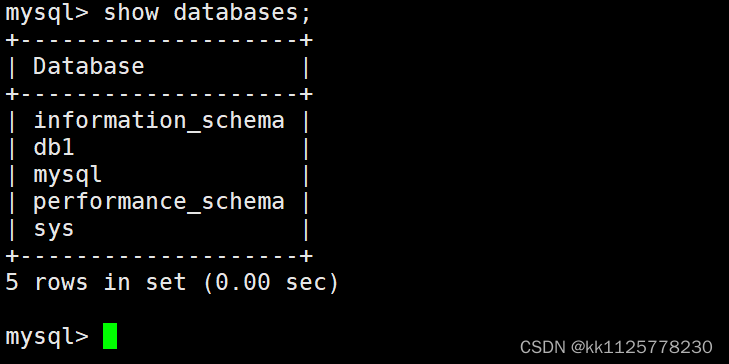
use 數據庫名;選定要使用的數據庫

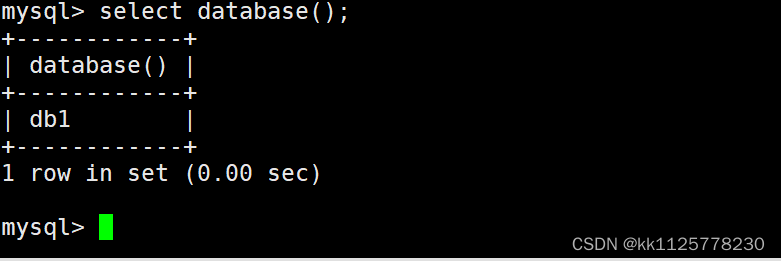
select database();查看當前在那個數據庫中.
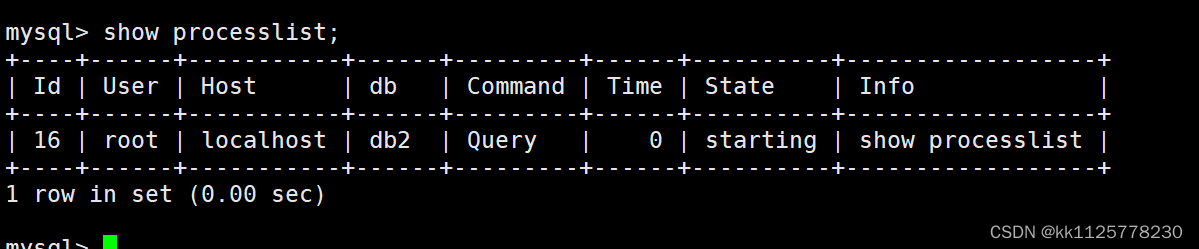
show processlist;可以查看當前誰在使用mysql;
5.備份
創建一個數據庫,然后退出mysql,用命令mysqldump -P3306 -uroot -B 數據庫名 > 備份文件路徑.將數據備份至指定的路徑下的文件中.數據庫后面跟多個數據庫名,可以同時備份多個數據庫.如果備份的是表,則在數據庫后面跟上表名即可,不過恢復的時候首先要自己創建一個數據庫.-B的選項其實就是備份數據中有創建數據庫的命令.
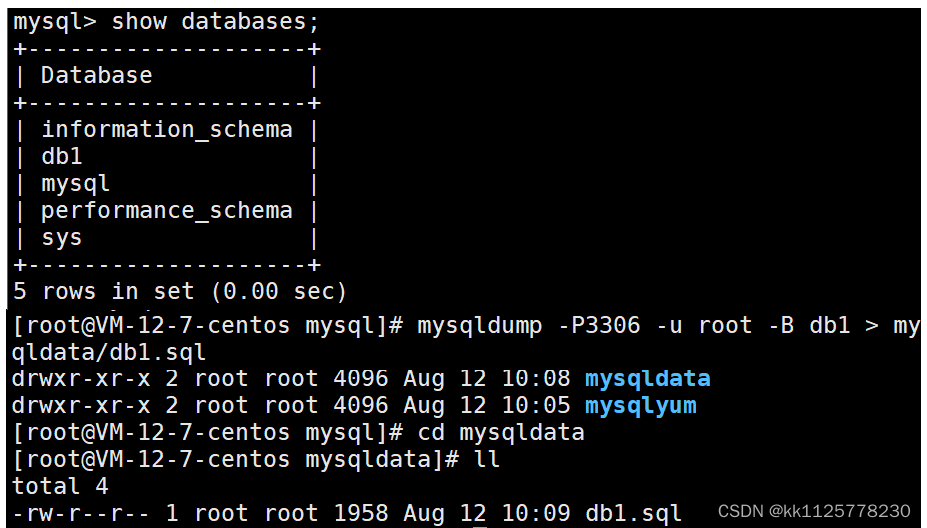
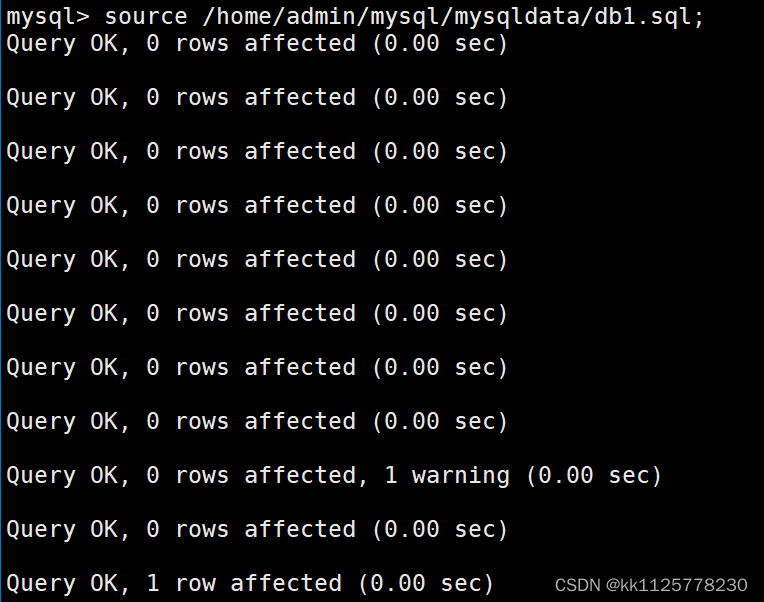
恢復時,進入mysql程序,用語句:source 備份文件路徑;即可將數據恢復.數據庫備份的數據其實是創建數據庫時的命令,恢復數據就是將數據庫的命令在當前程序中再執行一次.
二、字符集與校驗規則
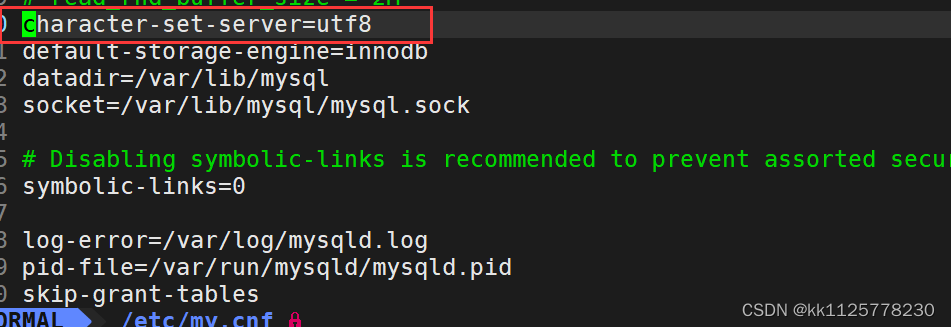
創建數據庫時有指定字符集和校驗規則的選項;字符集就是數據存儲時的編碼格式,校驗規則就是提取數據時校驗編碼格式的方法;在/etc/my.cnf配置文件中有character-set-server=utf8的配置信息,就是在配置數據庫模式使用的字符集.
使用show charset;可以查看支持的字符集

使用show collation;可以查看支持的校驗規則.
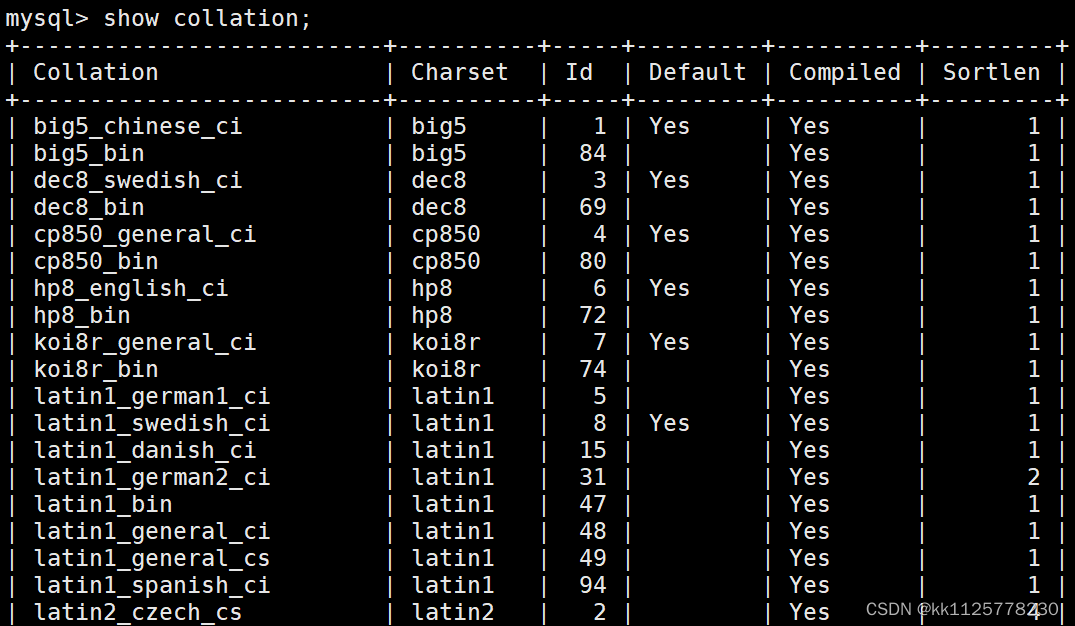
相同的字符集,不同的校驗規則,提取的數據也會不同.例如字符集utf8,校驗規則utf8_general_ci;索引提取數據時不區分大寫,utf8_bin;則區分大小寫;
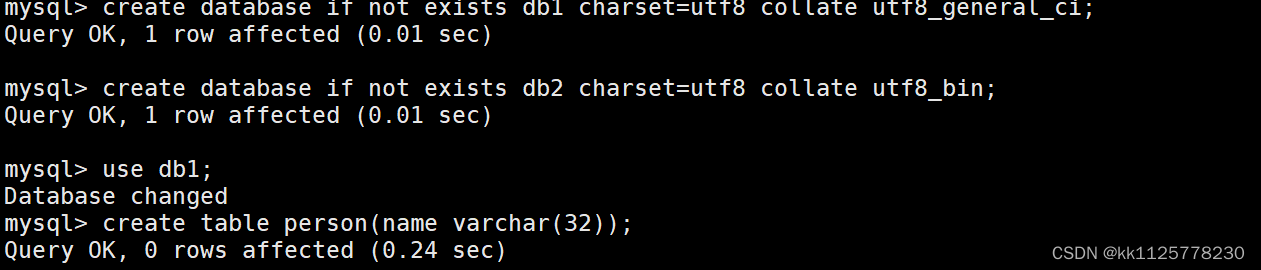
首先用相同字符集,不同的校驗規則創建兩個數據庫,分別在兩個數據庫中創建兩個person表
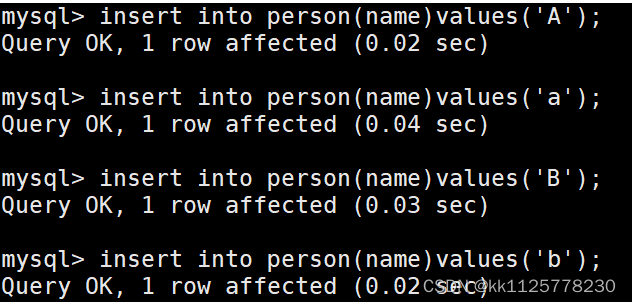
分別在兩個表中插入相同的數據’a’,‘A’,‘B’,‘b’
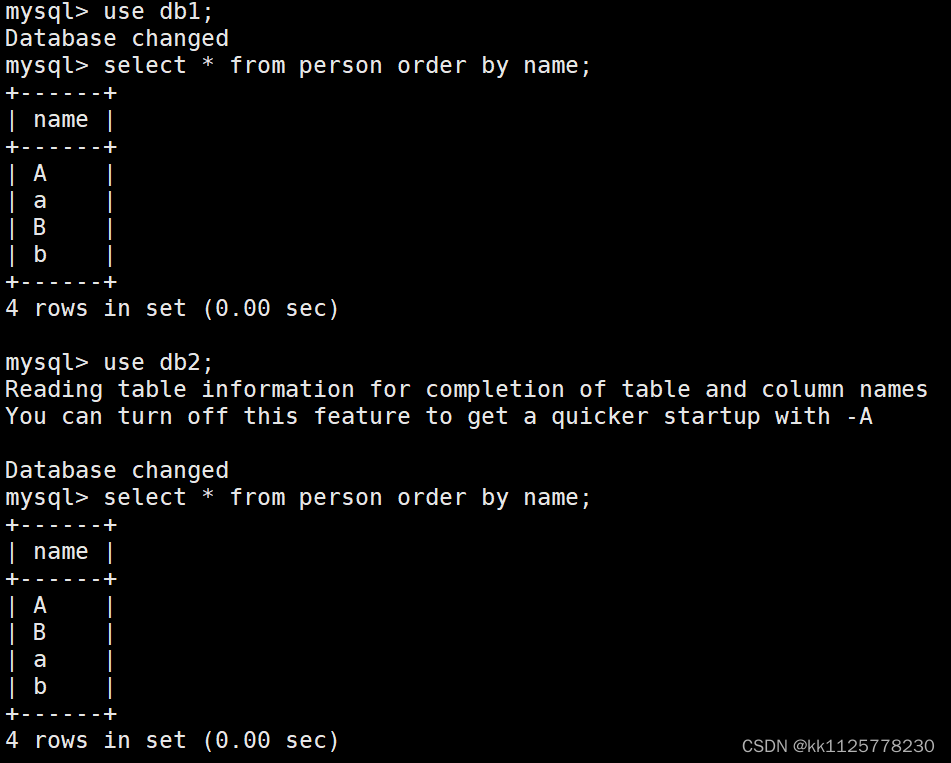
將兩個表都排序,所得到的結果是不一樣的,db1不區分大小寫,所以A和a都排在前面,db2區分大小寫,按照ascll碼值比較小寫全部排在大寫的后面.
按照名字小寫查詢db1不管大小寫都返回,db2只返回小寫;



)








Servlet容器的自動配置原理)




)

)
)