 本作品采用知識共享署名-非商業性使用-相同方式共享 4.0 國際許可協議進行許可。
本作品采用知識共享署名-非商業性使用-相同方式共享 4.0 國際許可協議進行許可。
本作品 (李兆龍 博文, 由 李兆龍 創作),由 李兆龍 確認,轉載請注明版權。
文章目錄
- 引言
- 問題定義
- 新技術
- 數據模型
- schemaless
- Tsfile設計
- 雙MemTable
- 高級可擴展查詢
- 其他
- IotDB劣勢
- influxDB 1.x 劣勢
- 結束語
引言
在時序數據庫這樣一個小眾的圈子里面每年有意思的東西并不多,每一篇頂會paper都值得細細品讀。其次靠自己想很多問題很難解決,還是需要向業界優秀的團隊虛心學習,才能清除和增加自己產品的核心競爭力。
問題定義
如下圖是《Apache IoTDB: A Time Series Database for IoT Applications》中提出的一個典型場景:
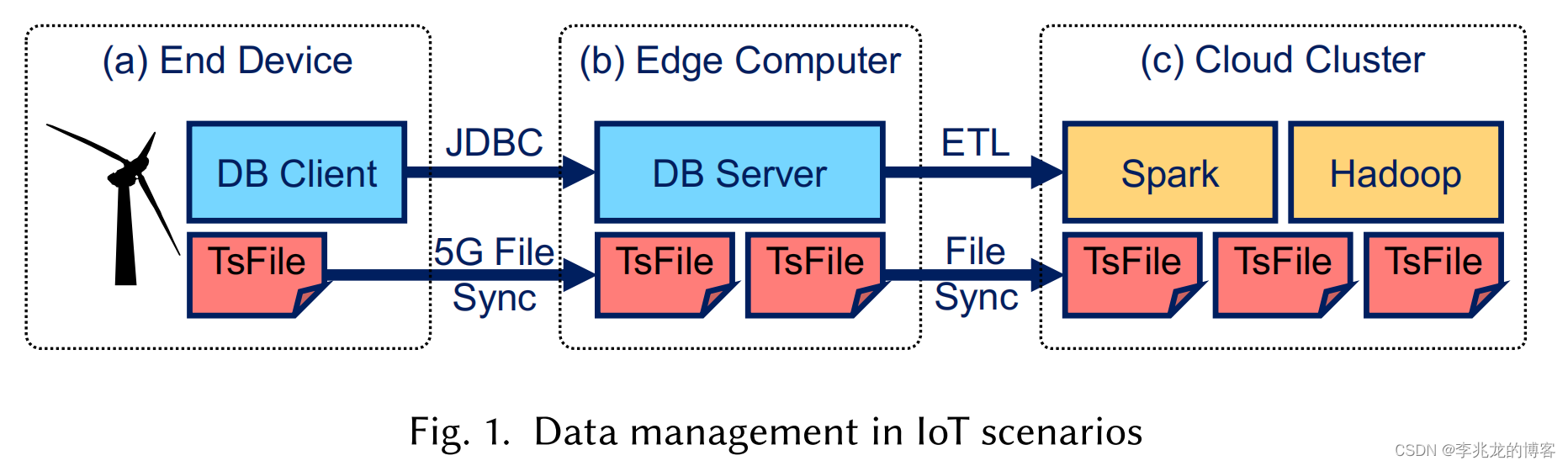
- 邊緣設備(時序數據的產生點)
- 邊緣服務器中需要一個用于寫入,存儲和查詢的數據庫
- 云端的計算集群,用于OLAP分析
文章開篇指出了IotDB聚焦的問題,即:
- 不斷變化的模式,即對于SchemaLess的支持(傳感器經常被替換,移除,新增)
- 周期性的數據采集
- 強相關的series(利用2,3可以增加壓縮的可能性)
- 多樣化延遲數據的寫入
- 高并發的數據寫入
其次在優雅的解決這些問題能保證查詢上做到:
- 一天之內10萬數據點的selection在100ms
- 三年之內1000萬數據點的aggregation在100ms
新技術
數據模型
InfluxDB中measurement+tags+fields的數據模型基本已經成為現實標準,但是IotDB認為這樣的模型對于設備和傳感器進行管理難以優化物理存儲,遂使用樹形管理所有的時間序列。
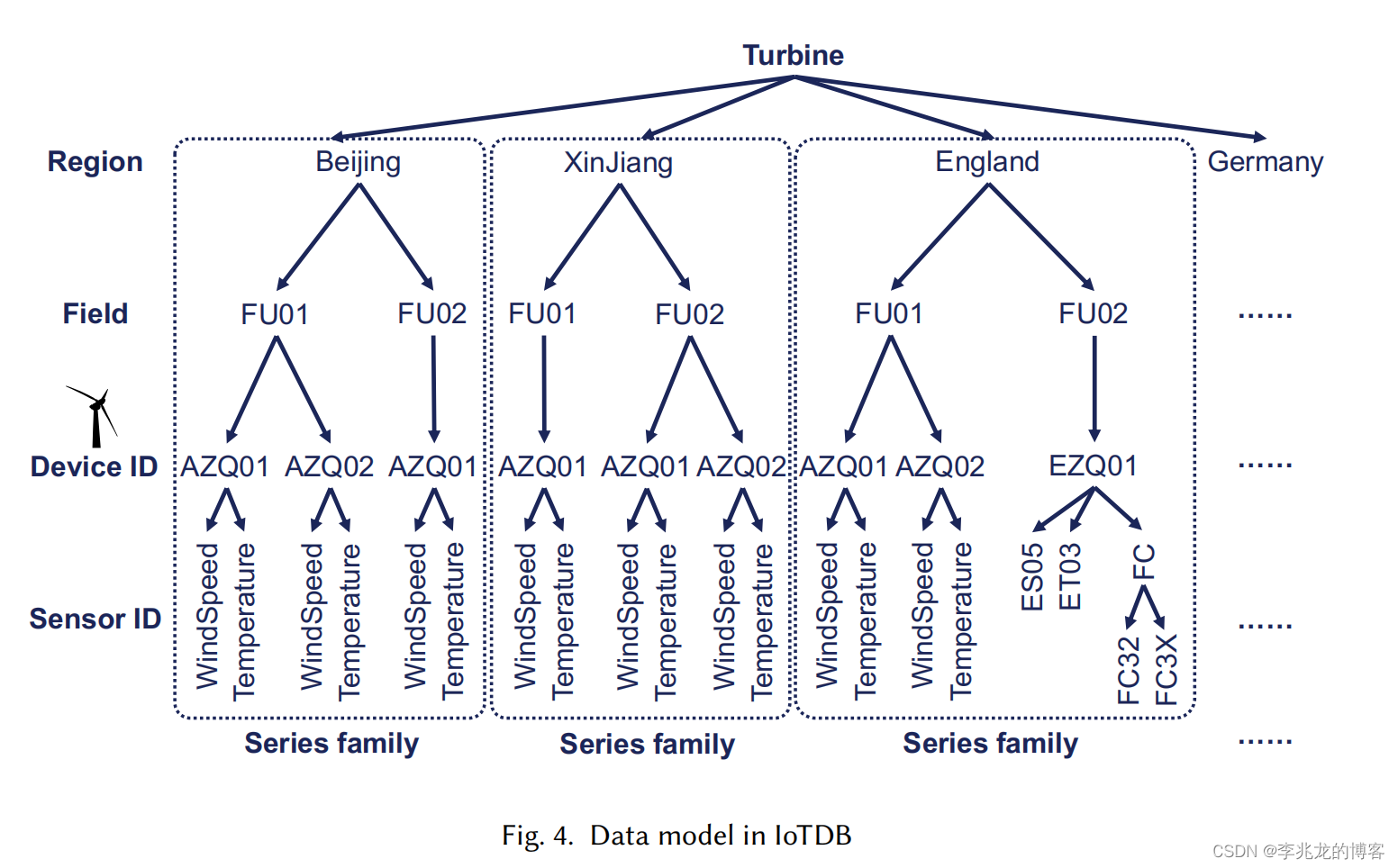
iotDB使用Sensor+Device管理所有的時間序列
物理模式如下:
- Time Series:每一條根節點到葉子結點是一個時間序列
- Series Family:一個設備的時間序列存儲在一個tsfile中,一個tsfile中可以存儲多個設備的時間序列,每一個 Series Family有一個獨立的存儲引擎,所有的tsfile存儲在一個目錄中
這樣的優勢我理解是可以控制哪些設備處于一個Series Family中,進而利用周期性和強相關的數據執行更有效的數據壓縮。
schemaless
[12]中描述了iotdb的方案,后續有時間看下,influxdb的方案就很簡單,不知道有什么區別。
Tsfile設計

- page:基本存儲單位,一個page屬于一個時間序列,其中存儲兩列,即時間和filed
- chunk:由metadata+多個page組成,所有page都屬于一個時間序列
- chunk group:由metadata+多個chunk組成,所有的chunk屬于一個或多個時間序列。多個chunk放在一起的原因文章中提到是一個設備所屬的多個傳感器一般被同時訪問,
- index:很巧妙的組織形式,可以很快的索引某個時間序列的所有chunk信息,并且攜帶時間序列的統計信息,比如count,begin,end等,用于查詢優化
本質上和TSM存儲格式差不多,但是因為TSM是KV模型,依賴于TSI獲取完整的seriesID,在這之中還需要在series file中獲取時機的serieskey,這就很慢了。這也是現代時序數據庫均使用Parquet,tsfile這樣存儲模型的原因,不僅導入導出方便,擺脫了倒排索引的依賴。
雙MemTable
本質要解決的問題就是亂序數據會使得tsfile的時間區間存在重復,但是這只適用于亂序數據較少的情況,此時會有益于查詢和寫放大;否則會退化為普通版本,還增加了維護的開銷。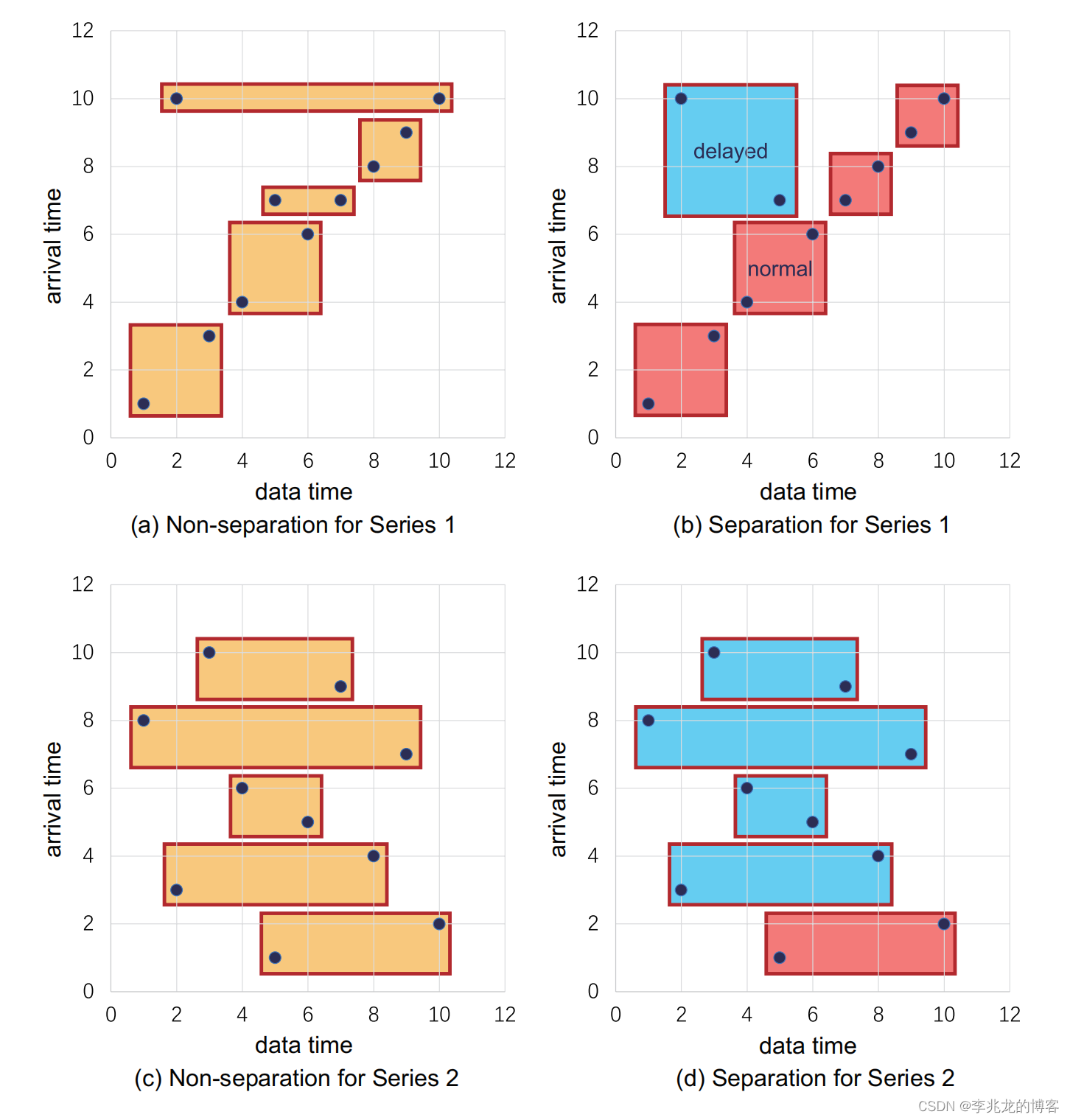 在iotdb遇到的場景下,長延時只有0.0375%;但是在我們當前的場景中,亂序數據是常態;其次influxdb內數據的寫入其實是在TSM,每個memtable中包含的是kv數據,就算亂序到達也只不過是查詢時需要在level0中的多掃幾個塊罷了;
在iotdb遇到的場景下,長延時只有0.0375%;但是在我們當前的場景中,亂序數據是常態;其次influxdb內數據的寫入其實是在TSM,每個memtable中包含的是kv數據,就算亂序到達也只不過是查詢時需要在level0中的多掃幾個塊罷了;
[10]中提到了可以通過數據的到達情況自動判斷是否分裂,這對于iodDB來說確實是一種很好的思路。
高級可擴展查詢
這幾乎是領域龍頭做的最好的一個方向了,因為這里非常偏學術,無論是DolphinDB還是IotDB對于各類特殊場景的算子支持都強于公有云廠商。
- 模式匹配算子PATTERN[2]
- 異常檢測函數[3]
- 數據估算函數,用于填補空缺值[4][5]
- 用戶自定義函數(UDF),用于特定領域個性化計算的需求;在查詢引擎中算子的處理都是迭代器化的,這個其實我們也可以加,但是現階段來看需求并不強烈,沒必要透漏給用戶這個接口。
其他
- 高效的數據傳輸,可以在邊緣設備,邊緣服務器和云端之間導入,不需要昂貴的ETL。這其實不是IotDB獨有的優勢,本質上只要存儲層是獨立可解釋的文件就有這個優勢,單很可惜inlfuxDB1.x不是,這也是InfluxData推動InfluxDBiox的關鍵動機之一。
- 高效的壓縮能力,這其實是核心要解決的問題中周期性以及強相關數據的具體優化方式,在[6]中闡述了各種數據類型壓縮的方式,iotdb也研究出了一些巧妙的壓縮方式[7][8][9],也證明了一般時序數據庫中默認(比如influxdb)的Timestamp: Delta → Scaling → (RLE/Simple8b); Float:XOR;Integer:ZigZag → (Simple8b/RLE/Uncompress);Boolean:Bit-packing;并不是最優的解決方案。但是這并不是IotDB獨有的方案,理論上只需要一個實習生任意一個系統都可以具備這樣的優勢。其次存儲目前從經驗來看并不是運營中最大的問題,工程不是學術,在壓縮率已經達到要求的情況下沒有必要過度優化。
IotDB劣勢
- 分布式系統設計歷史氣息濃厚,這帶來的直接差異我能想到的有:元數據管理節點存在單點,集群規模TB級別,不適用于公有云,只適合于私有云,這也導致了價錢不會太便宜
- 聚焦于Iot場景,可以說把無損壓縮做到了極致,但是現在SSD并不貴,以我們的運營經驗來看存儲不是瓶頸。優勢帶來的劣勢時時間線較多的場景無法處理,因為tsfile中的樹形索引基本失效,每一個series都是一個根節點。
- java編寫,我猜測和influxdb1.x一樣存在full gc的問題,基本無法解決;
- TSQL能力弱于influxql和SQL
influxDB 1.x 劣勢
- 不支持SQL
- 基數無法無限擴展(國內目前TDengine以外其他大廠的時序數據庫仔細看都存在時間線限制)
- 存算不分離(開源沒有集群版),導致隔離很難做[13],基本上是無解的(也有辦法,不過實施比較復雜),所以只能在運營角度規避這個問題
- go實現,且實現的不嚴謹,導致內存問題很嚴重;顯然Rust/cpp才是最好的引擎語言
- 應該允許在沒有本地存儲的情況下運行,但是內部實現大量使用mmap(建議大家都看看[14])
- 索引數據分離,導致導入導出極為困難
- Highly indexed,導致寫操作較為繁瑣且昂貴,可能需要更新兩個索引和一個數據
- 查詢多時間線時極為昂貴,tsi中需要消耗大量的時間,因為需要對所有的查詢條件的結果集做并集,并在seriesfile中查詢series key,[15]也提到拆分索引是沒有用的,查詢的時間線客觀存在,拆分索引還會造成內存問題,因為維護索引信息也需要不少內存
- 時間線較多時索引信息大于數據,但是時序的場景導致很多索引自始至終是無法被使用的
結束語
跟著老大InfluxDB IOX走基本上沒有錯,其他的路都是徒勞。

參考:
- Announcing InfluxDB IOx - The Future Core of InfluxDB Built with Rust and Arrow
- Kv-match: A subsequence matching approach supporting normalization and time warping icde2019
- Time series data cleaning: From anomaly detection to anomaly repairing vldb2017
- Sequential data cleaning: A statistical approach sigmod2016
- SCREEN: stream data cleaning under speed constraints sigmod2015
- Time series data encoding for efficient storage: A comparative analysis in apache iotdb vldb2022
- On aligning tuples for regression KDD22
- Grouping time series for efficient columnar storage sigmod2023
- Frequency domain data encoding in apache iotdb vldb2022
- Separation or not: On handing out-of-order time-series data in leveled lsm-tree icde2022
- Non-blocking raft for high throughput iot data icde2023
- Swapping repair for misplaced attribute values icde2020
- 從一到無窮大 #7 Database-as-a-Service租戶隔離挑戰與解決措施
- Are You Sure You Want to Use MMAP in Your Database Management System?
- The Design of InfluxDB IOx: In-Memory Columnar Database Written in Rust with Apache Arrow (Paul Dix)












)

![[樹莓派]ImportError: libcblas.so.3: cannot open shared object file](http://pic.xiahunao.cn/[樹莓派]ImportError: libcblas.so.3: cannot open shared object file)
)
)


