LangChain-ChatGLM在WIndows10下的部署
參考資料
1、LangChain + ChatGLM2-6B 搭建個人專屬知識庫中的LangChain + ChatGLM2-6B 構建知識庫這一節:基本的邏輯和步驟是對的,但要根據Windows和現狀做很多調整。
2、沒有動過model_config.py中的“LORA_MODEL_PATH_BAICHUAN”這一項內容,卻報錯:對報錯“LORA_MODEL_PATH_BAICHUAN”提供了重要解決思路,雖然還不是完全按文中的方式解決的。
3、[已解決ERROR: Could not install packages due to an OSError: [WinError 5] 拒絕訪問。: ‘e:\anaconda\install_r])(https://blog.csdn.net/yuan2019035055/article/details/127078460)
解決方案
一、下載源碼
采用git clone方式一直不成功,建議直接到github上搜索langchain-chatglm,在https://github.com/chatchat-space/langchain-ChatGLM頁面,點擊“CODE”->點擊“Download ZIP”,直接下載源碼,然后將文件夾改為名LangChain-ChatGLM,放到D:\_ChatGPT\langchain-chatglm_test目錄下:
二、安裝依賴
1、進入Anaconda Powershell Prompt
2、進入虛擬環境
conda activate langchain-chatglm_test
3、進入目錄
cd D:\_ChatGPT\langchain-chatglm_test\langchain-ChatGLM
4、安裝依賴
pip install -r requirements.txt --user
pip install peft
pip install timm
pip install scikit-image
pip install torch==1.13.1+cu116 torchvision torchaudio -f https://download.pytorch.org/whl/cu116/torch_stable.html
三、下載模型
3.1、下載chatglm2-6b模型
1、進入Anaconda Powershell Prompt
2、創建保存chatglm2-6b的huggingface模型的公共目錄。之所以創建一個公共目錄,是因為這個模型文件是可以被各種應用共用的。注意創建目錄所在磁盤至少要有30GB的空間,因為chatglm2-6b的模型文件至少有23GB大小。并進入該目錄
mkdir -p D:\_ChatGPT\_common
cd D:\_ChatGPT\_common
3、安裝 git lfs
git lfs install
4、在這里下載chatglm2-6b的huggingface模型文件。
git clone https://huggingface.co/THUDM/chatglm2-6b
5、下載完成后,將模型文件的目錄名改為chatglm2-6b,因為Windows下目錄如果有減號,后續應用處理會出錯。
6、如果之前已下載該模型,則不必重復下載。
3.2、下載text2vec模型
1、進入Anaconda Powershell Prompt,進入公共目錄
cd D:\_ChatGPT\_common
2、安裝 git lfs
git lfs install
3、在這里下載text2vec的huggingface模型文件。
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
4、下載完成后,將目錄改為text2vev,因為Windows下目錄如果有減號,后續應用處理會出錯。
四、參數調整
4.1、model_config.py文件
1、進入configs目錄,修改其下的model_config.py文件,
對embedding_model_dict的參數
embedding_model_dict = {..."text2vec": r"D:\_ChatGPT\_common\text2vec",...
}
修改llm_model_dict參數。
llm_model_dict = {..."chatglm-6b": {..."pretrained_model_name": r"D:\_ChatGPT\_common\chatglm2_6b","...},...
}
將LLM_MODEL的值做修改:
LLM_MODEL = "chatglm2-6b"
4.2、loader.py文件
1、進入modes\loader目錄,修改loader.py文件
2、在if LORA_MODEL_PATH_BAICHUAN:前加一句LORA_MODEL_PATH_BAICHUAN = False,如下所示:
if torch.cuda.is_available() and self.llm_device.lower().startswith("cuda"):# 根據當前設備GPU數量決定是否進行多卡部署num_gpus = torch.cuda.device_count()if num_gpus < 2 and self.device_map is None:# if LORA_MODEL_PATH_BAICHUAN is not None:LORA_MODEL_PATH_BAICHUAN = Falseif LORA_MODEL_PATH_BAICHUAN:
3、在每一個mode = XXX.from_pretrained(XXX)后面加上.quantize(8).cuda(),對模型進行量化,否則加載會報內存不夠的錯誤。
五、啟動
1、關閉fanqiang軟件
2、運行如下命令
python .\webui.py
3、訪問http://localhost:7860
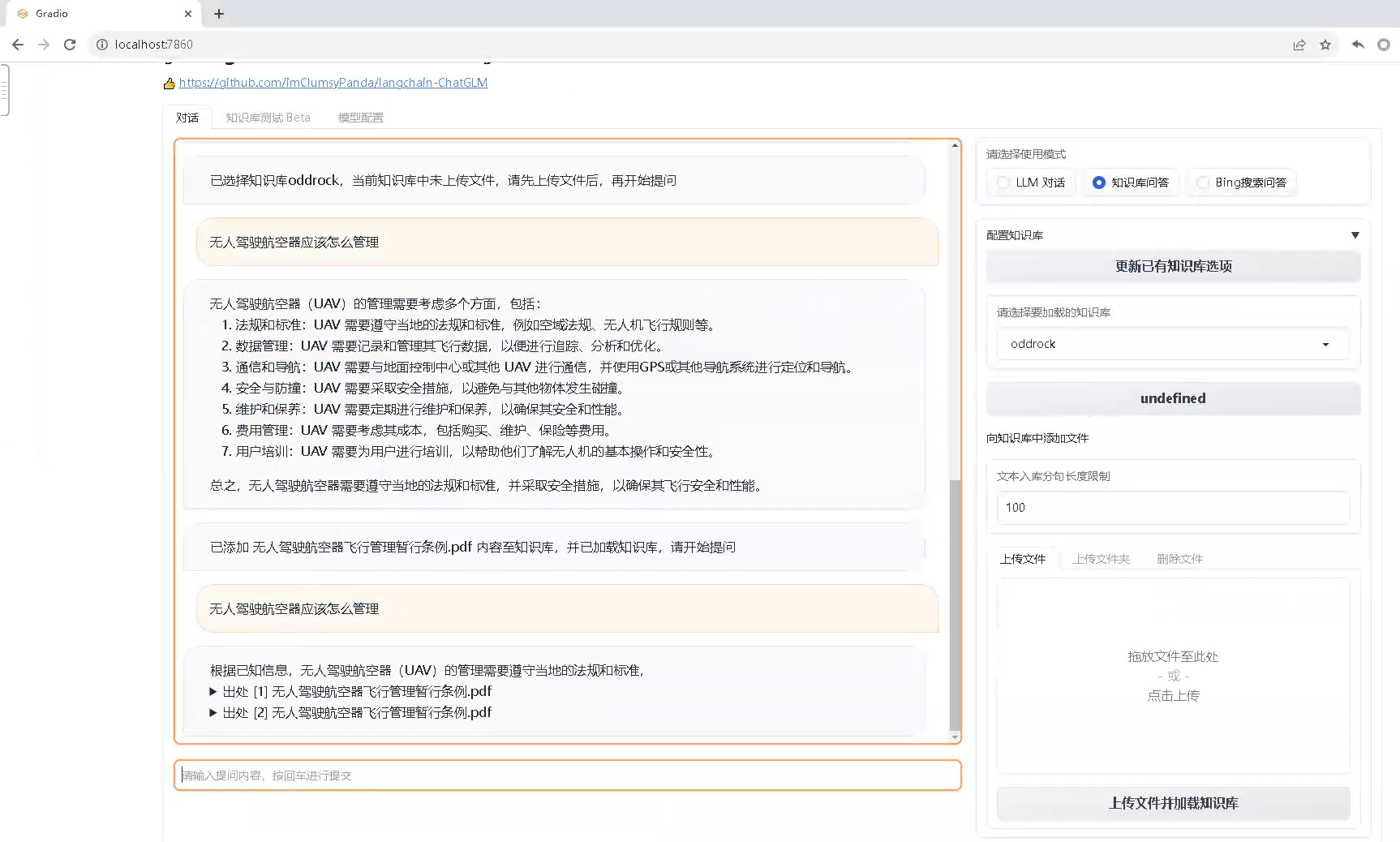
六、上傳文檔進行問答
1、在http://localhost:7860界面,在請選擇要加載的知識庫,選擇samples。
2、向知識庫中添加一個文件,點擊上傳文件并加載,等待幾分鐘以后,模型完成訓練,即可針對上傳的文件進行問答。






)

![[樹莓派]ImportError: libcblas.so.3: cannot open shared object file](http://pic.xiahunao.cn/[樹莓派]ImportError: libcblas.so.3: cannot open shared object file)
)
)



)
利用有限制通配符來提升 API 的靈活性)


VOC劃分數據集、VOC轉YOLO數據集)
