MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
論文:https://arxiv.org/abs/2110.02178

?1簡介
MobileviT是一個用于移動設備的輕量級通用可視化Transformer,據作者介紹,這是第一次基于輕量級CNN網絡性能的輕量級ViT工作,性能SOTA!。性能優于MobileNetV3、CrossviT等網絡。
輕量級卷積神經網絡(CNN)是移動視覺任務的實際應用。他們的空間歸納偏差允許他們在不同的視覺任務中以較少的參數學習表征。然而,這些網絡在空間上是局部的。為了學習全局表征,采用了基于自注意力的Vision Transformer(ViTs)。與CNN不同,ViT是heavy-weight。
在本文中,本文提出了以下問題:是否有可能結合CNN和ViT的優勢,構建一個輕量級、低延遲的移動視覺任務網絡?
為此提出了MobileViT,一種輕量級的、通用的移動設備Vision Transformer。MobileViT提出了一個不同的視角,以Transformer作為卷積處理信息。
?
實驗結果表明,在不同的任務和數據集上,MobileViT顯著優于基于CNN和ViT的網絡。
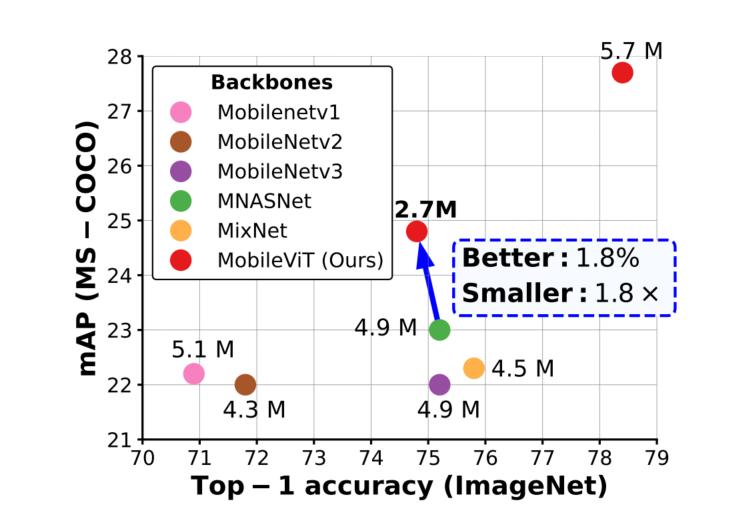
在ImageNet-1k數據集上,MobileViT在大約600萬個參數的情況下達到了78.4%的Top-1準確率,對于相同數量的參數,比MobileNetv3和DeiT的準確率分別高出3.2%和6.2%。
在MS-COCO目標檢測任務中,在參數數量相近的情況下,MobileViT比MobileNetv3的準確率高5.7%。
2.Mobile-ViT
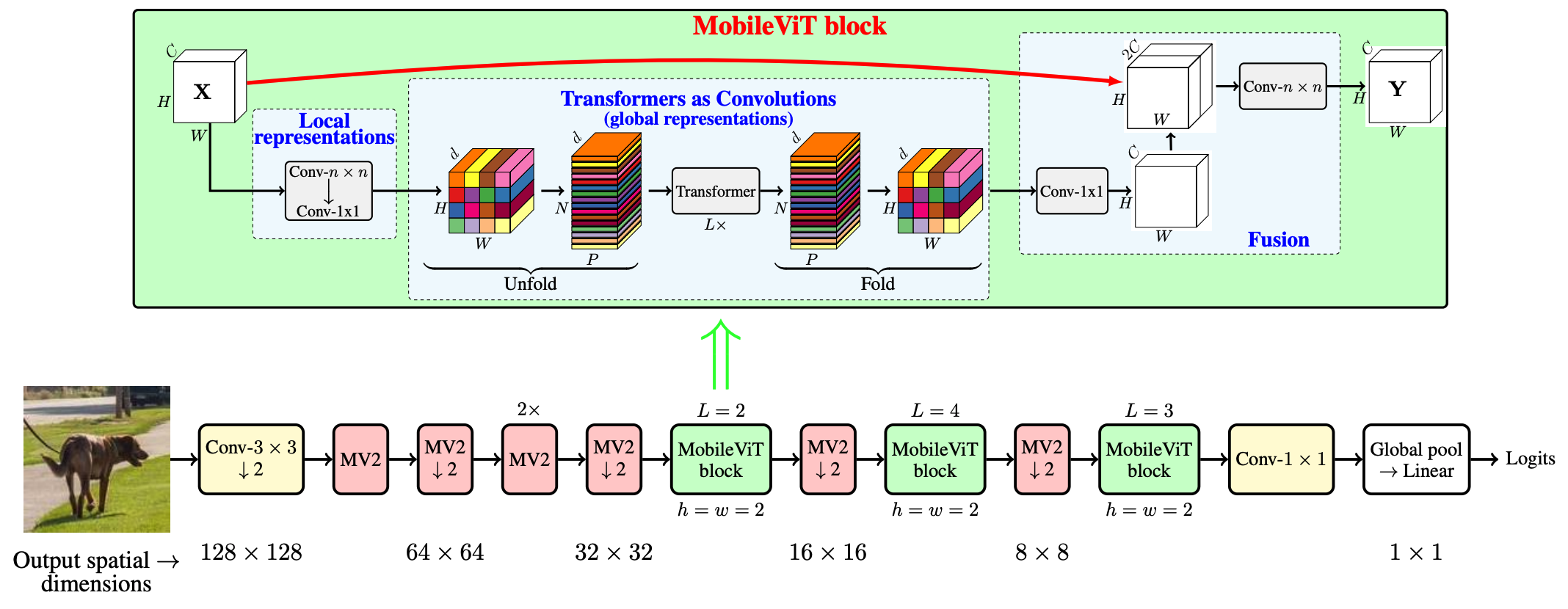
MobileViT Block如下圖所示,其目的是用較少的參數對輸入張量中的局部和全局信息進行建模。
形式上,對于一個給定的輸入張量, MobileViT首先應用一個n×n標準卷積層,然后用一個一個點(或1×1)卷積層產生特征。n×n卷積層編碼局部空間信息,而點卷積通過學習輸入通道的線性組合將張量投影到高維空間(d維,其中d>c)。
?
通過MobileViT,希望在擁有有效感受野的同時,對遠距離非局部依賴進行建模。一種被廣泛研究的建模遠程依賴關系的方法是擴張卷積。然而,這種方法需要謹慎選擇膨脹率。否則,權重將應用于填充的零而不是有效的空間區域。
另一個有希望的解決方案是Self-Attention。在Self-Attention方法中,具有multi-head self-attention的vision transformers(ViTs)在視覺識別任務中是有效的。然而,vit是heavy-weight,并由于vit缺乏空間歸納偏差,表現出較差的可優化性。
下面附上改進代碼
---------------------------------------------分割線--------------------------------------------------
在common中加入如下代碼
需要安裝一個einops模塊
pip --default-timeout=5000 install -i https://pypi.tuna.tsinghua.edu.cn/simple einops
這邊建議直接興建一個?
?
import torch
import torch.nn as nnfrom einops import rearrangedef conv_1x1_bn(inp, oup):return nn.Sequential(nn.Conv2d(inp, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),nn.SiLU())def conv_nxn_bn(inp, oup, kernal_size=3, stride=1):return nn.Sequential(nn.Conv2d(inp, oup, kernal_size, stride, 1, bias=False),nn.BatchNorm2d(oup),nn.SiLU())class PreNorm(nn.Module):def __init__(self, dim, fn):super().__init__()self.norm = nn.LayerNorm(dim)self.fn = fndef forward(self, x, **kwargs):return self.fn(self.norm(x), **kwargs)class FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout=0.):super().__init__()self.net = nn.Sequential(nn.Linear(dim, hidden_dim),nn.SiLU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)class Attention(nn.Module):def __init__(self, dim, heads=8, dim_head=64, dropout=0.):super().__init__()inner_dim = dim_head * headsproject_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** -0.5self.attend = nn.Softmax(dim = -1)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):qkv = self.to_qkv(x).chunk(3, dim=-1)q, k, v = map(lambda t: rearrange(t, 'b p n (h d) -> b p h n d', h = self.heads), qkv)dots = torch.matmul(q, k.transpose(-1, -2)) * self.scaleattn = self.attend(dots)out = torch.matmul(attn, v)out = rearrange(out, 'b p h n d -> b p n (h d)')return self.to_out(out)class Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):super().__init__()self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([PreNorm(dim, Attention(dim, heads, dim_head, dropout)),PreNorm(dim, FeedForward(dim, mlp_dim, dropout))]))def forward(self, x):for attn, ff in self.layers:x = attn(x) + xx = ff(x) + xreturn xclass MV2Block(nn.Module):def __init__(self, inp, oup, stride=1, expansion=4):super().__init__()self.stride = strideassert stride in [1, 2]hidden_dim = int(inp * expansion)self.use_res_connect = self.stride == 1 and inp == oupif expansion == 1:self.conv = nn.Sequential(# dwnn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),nn.BatchNorm2d(hidden_dim),nn.SiLU(),# pw-linearnn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),)else:self.conv = nn.Sequential(# pwnn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),nn.BatchNorm2d(hidden_dim),nn.SiLU(),# dwnn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),nn.BatchNorm2d(hidden_dim),nn.SiLU(),# pw-linearnn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),)def forward(self, x):if self.use_res_connect:return x + self.conv(x)else:return self.conv(x)class MobileViTBlock(nn.Module):def __init__(self, dim, depth, channel, kernel_size, patch_size, mlp_dim, dropout=0.):super().__init__()self.ph, self.pw = patch_sizeself.conv1 = conv_nxn_bn(channel, channel, kernel_size)self.conv2 = conv_1x1_bn(channel, dim)self.transformer = Transformer(dim, depth, 4, 8, mlp_dim, dropout)self.conv3 = conv_1x1_bn(dim, channel)self.conv4 = conv_nxn_bn(2 * channel, channel, kernel_size)def forward(self, x):y = x.clone()# Local representationsx = self.conv1(x)x = self.conv2(x)# Global representations_, _, h, w = x.shapex = rearrange(x, 'b d (h ph) (w pw) -> b (ph pw) (h w) d', ph=self.ph, pw=self.pw)x = self.transformer(x)x = rearrange(x, 'b (ph pw) (h w) d -> b d (h ph) (w pw)', h=h//self.ph, w=w//self.pw, ph=self.ph, pw=self.pw)# Fusionx = self.conv3(x)x = torch.cat((x, y), 1)x = self.conv4(x)return xclass MobileViT(nn.Module):def __init__(self, image_size, dims, channels, num_classes, expansion=4, kernel_size=3, patch_size=(2, 2)):super().__init__()ih, iw = image_sizeph, pw = patch_sizeassert ih % ph == 0 and iw % pw == 0L = [2, 4, 3]self.conv1 = conv_nxn_bn(3, channels[0], stride=2)self.mv2 = nn.ModuleList([])self.mv2.append(MV2Block(channels[0], channels[1], 1, expansion))self.mv2.append(MV2Block(channels[1], channels[2], 2, expansion))self.mv2.append(MV2Block(channels[2], channels[3], 1, expansion))self.mv2.append(MV2Block(channels[2], channels[3], 1, expansion)) # Repeatself.mv2.append(MV2Block(channels[3], channels[4], 2, expansion))self.mv2.append(MV2Block(channels[5], channels[6], 2, expansion))self.mv2.append(MV2Block(channels[7], channels[8], 2, expansion))self.mvit = nn.ModuleList([])self.mvit.append(MobileViTBlock(dims[0], L[0], channels[5], kernel_size, patch_size, int(dims[0]*2)))self.mvit.append(MobileViTBlock(dims[1], L[1], channels[7], kernel_size, patch_size, int(dims[1]*4)))self.mvit.append(MobileViTBlock(dims[2], L[2], channels[9], kernel_size, patch_size, int(dims[2]*4)))self.conv2 = conv_1x1_bn(channels[-2], channels[-1])self.pool = nn.AvgPool2d(ih//32, 1)self.fc = nn.Linear(channels[-1], num_classes, bias=False)def forward(self, x):x = self.conv1(x)x = self.mv2[0](x)x = self.mv2[1](x)x = self.mv2[2](x)x = self.mv2[3](x) # Repeatx = self.mv2[4](x)x = self.mvit[0](x)x = self.mv2[5](x)x = self.mvit[1](x)x = self.mv2[6](x)x = self.mvit[2](x)x = self.conv2(x)x = self.pool(x).view(-1, x.shape[1])x = self.fc(x)return xdef mobilevit_xxs():dims = [64, 80, 96]channels = [16, 16, 24, 24, 48, 48, 64, 64, 80, 80, 320]return MobileViT((256, 256), dims, channels, num_classes=1000, expansion=2)def mobilevit_xs():dims = [96, 120, 144]channels = [16, 32, 48, 48, 64, 64, 80, 80, 96, 96, 384]return MobileViT((256, 256), dims, channels, num_classes=1000)def mobilevit_s():dims = [144, 192, 240]channels = [16, 32, 64, 64, 96, 96, 128, 128, 160, 160, 640]return MobileViT((256, 256), dims, channels, num_classes=1000)def count_parameters(model):return sum(p.numel() for p in model.parameters() if p.requires_grad)if __name__ == '__main__':img = torch.randn(5, 3, 256, 256)vit = mobilevit_xxs()out = vit(img)print(out.shape)print(count_parameters(vit))vit = mobilevit_xs()out = vit(img)print(out.shape)print(count_parameters(vit))vit = mobilevit_s()out = vit(img)print(out.shape)print(count_parameters(vit))yolo.py中導入并注冊
加入MV2Block, MobileViTBlock

?
?
修改yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 backbone
backbone:# [from, number, module, args] 640 x 640
# [[-1, 1, Conv, [32, 6, 2, 2]], # 0-P1/2 320 x 320[[-1, 1, Focus, [32, 3]],[-1, 1, MV2Block, [32, 1, 2]], # 1-P2/4[-1, 1, MV2Block, [48, 2, 2]], # 160 x 160[-1, 2, MV2Block, [48, 1, 2]],[-1, 1, MV2Block, [64, 2, 2]], # 80 x 80[-1, 1, MobileViTBlock, [64,96, 2, 3, 2, 192]], # 5 out_dim,dim, depth, kernel_size, patch_size, mlp_dim[-1, 1, MV2Block, [80, 2, 2]], # 40 x 40[-1, 1, MobileViTBlock, [80,120, 4, 3, 2, 480]], # 7[-1, 1, MV2Block, [96, 2, 2]], # 20 x 20[-1, 1, MobileViTBlock, [96,144, 3, 3, 2, 576]], # 11-P2/4 # 9]# YOLOv5 head
head:[[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [256, False]], # 13[-1, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [128, False]], # 17 (P3/8-small)[-1, 1, Conv, [128, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [256, False]], # 20 (P4/16-medium)[-1, 1, Conv, [256, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [512, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]?
-
修改mobilevit.py

?
補充說明
einops.EinopsError: Error while processing rearrange-reduction pattern "b d (h ph) (w pw) -> b (ph pw) (h w) d".
Input tensor shape: torch.Size([1, 120, 42, 42]). Additional info: {'ph': 4, 'pw': 4}
是因為輸入輸出不匹配造成
記得關掉rect哦!一個是在參數里,另一個在下圖。如果要在test或者val中跑,同樣要改
?
)

![[樹莓派]ImportError: libcblas.so.3: cannot open shared object file](http://pic.xiahunao.cn/[樹莓派]ImportError: libcblas.so.3: cannot open shared object file)
)
)



)
利用有限制通配符來提升 API 的靈活性)


VOC劃分數據集、VOC轉YOLO數據集)





)
)