煉數成金數據分析課程---16、機器學習中的分類算法(交叉內容,后面要重點看)
一、總結
一句話總結:
大綱+實例快速學習法
主要講解常用分類算法(如Knn、決策樹、貝葉斯分類器等)的原理及python代碼實現
?
1、什么是分類?
分類模型:輸入樣本的屬性值,輸出對應的類別,將每個樣本映射到預先定義好的類別
?
2、常用分類算法?
-Knn算法
-決策樹
-貝葉斯分類器
-神經網絡
-Knn算法 -決策樹 -貝葉斯分類器 -支持向量機 -神經網絡
?
?
?
3、分類算法中的決策樹的主要思想是什么?
空間劃分:看圖
?
?
4、分類算法中的決策樹的介紹?
樹中每一個非葉節點表示一個決策,該決策的值導致不同的決策結果(葉節點)或者影響后面的決策選擇。
根據給定的未知分類的元組X,根據其屬性值跟蹤一條由根節點到葉節點的路徑,該葉節點就是該元組的分類結果預測。
?
5、構建決策樹的算法的本質是什么?
貪心:在構建決策樹時,這兩類算法的流程基本一樣,都采用貪心方法,自頂而下遞歸構建決 策樹
?
6、貪心算法如何構建決策樹?
1.創建一個結點N。如果D中的元組都在同一個類別C中,則N作為葉結點,以C標記;如果屬性列表為空,則N作為葉節點,以D中最多的類別C作為標記。
2.根據分裂準則找出“最好”的分裂屬性A,并用該分裂屬性標記N。1)A是離散的,則A的每個已知值都產生一個分支;2)A是連續的,則產生Ass和A>s兩個分支;3)若A是連續的,并且必須產生二叉樹,則產生AEA1和AEA2兩個分支,其中A1,A2非空且A1UA2=A
3.若給定的分支中的元組非空,對于D的每一個分支Dj,重復步驟1,2
?
7、分類算法中的決策樹的 屬性選擇 如何度量?
如果我們根據分裂準則把D劃分為較小的分區,最好的情況是每個分區都是純的,即落在一個給定分區的所有元組都是相同的類。最好的分裂準則就是令到每個分區盡量的純。
屬性選擇度量給學習集中的每個屬性提供了評定。具有最好度量得分的屬性被選為分裂屬性。
?
8、決策樹的剪枝的兩種常用方法是什么?
先剪枝:通過設定一定的閥值來停止樹的生長例如,在構建樹模型時,使用信息增益、基尼指數來度量劃分的優劣。可以預先設定一個閥值,當劃分一個結點的元組到時低于預設的閥值時,停止改子集的劃分
后剪枝:等樹完全生成后再通過刪除結點去修剪決策樹。由于先剪枝中,選擇合適的閥值存在一定的困難,所以后剪枝更加常用
?
9、python中使用決策分類算法常需要借助哪些包?
主要是python的sklearn庫
import numpy as np from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import precision_recall_curve from sklearn.metrics import classification_report from sklearn.naive_bayes import BernoulliNB from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.cross_validation import train_test_split import matplotlib.pyplot as plt import pandas as pd
?
?
二、內容在總結中
決策樹--空間分割
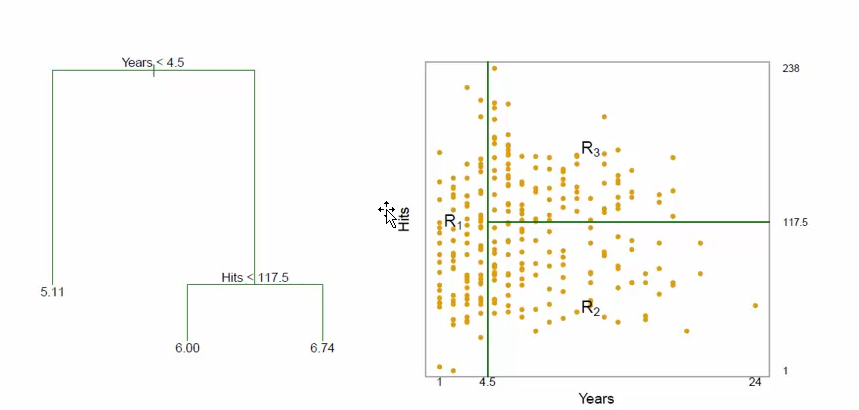
?
week13
?
?
?
?
?
?




)






)







