大家好,我是若川。三天假期總是那么短暫,明天就要上班了。今天推薦一篇相對簡單的文章。
點擊下方卡片關注我、加個星標

之前有同學在前端技術分享時提到了SEO,另一同學問我SEO是什么,我當時非常詫異,作為前端應該對SEO很了解才對,不過仔細想想,現在前后端分離的大趨勢下,SPA單頁WEB應用也隨之興起,現在的前端新生對SEO不了解也是有原因的,所以本次就帶著大家重識SEO!
什么是SEO
 SEO(Search Engine Optimization),中文翻譯成
SEO(Search Engine Optimization),中文翻譯成搜索引擎優化,是指通過采用易于搜索引擎索引的合理手段,使網站各項基本要素適合搜索引擎的檢索原則并且對用戶更友好,從而更容易被搜索引擎收錄及優先排序
發展史
SEO在國內起步比較晚,主要經歷了四個發展階段:
2003年初到2004年底,Google剛進入中國不久,SEO在國內剛剛起步
2004年底到2005年上半年, 全國涌現出上百家SEO公司
2005年下半年至2006年9月,SEO作弊泛濫成災,嚴重破壞了市場秩序,威脅到搜索引擎的利益,SEO一度成為作弊的代名詞,引起一些主流搜索引擎的大量清理
2006年9月至今,隨著SEO培訓的興起,SEO技術越來越普及化也更加正規合理化
優點
成本低
利用SEO來給網站做優化,不僅提升網站的排名,還能增加搜索引擎的友好度。企業除支付相關人員的費用外,一般不需要投入其它費用,所以成本很低。
通用性強
SEO人員通過對網站機構、布局、內容、關鍵詞等要素的合理設計,讓網站符合搜索引擎的規則。雖然有很多搜索引擎,但你只要做好百度所搜引擎優化,其它的搜索引擎排名也會跟著提高。
穩定性好
正常情況下,只要是正規方法優化的網站,排名都會比較穩定。只有搜索引擎算法更改或者競爭對手更有優勢,才會讓網站出現比較大的變化。
公平性
在搜索引擎中,所有網站展示機會都是均等的,需要企業公平的競爭排名。搜索引擎不是根據網站的規模、知名度來作為排名的依據,而是綜合多方面的因素,這樣就給網站提供了一個公平競爭的環境。
有效規避無效點擊
有些企業為了增加知名度而選擇付費推廣,這種點擊收費的推廣方式,會遭到同行業的惡意點擊,讓你的費用迅速用完。而利用SEO技術優化的網站就不會出現這種問題,同行業點擊的越多,對網站越有利,可以增加搜索引擎的友好度,進而提升網站的排名。
缺點
見效慢
SEO需要人工來做的,不會立刻收到效果的。一般來說,從開始優化到關鍵詞有排名需要1至3個月左右,如果是競爭激烈的關鍵詞,可能需要更長的時間。
被動性
網站和搜索引擎是一種被動排名關系。網站的優化需要符合搜索引擎規則,這樣才能讓網站的排名靠前。搜索引擎的規則不是一成不變的,它會不定期的修改算法,將更好的內容展示給用戶。因此,需要對網站的優化進行相對應的調整,以應對各種變化。
不確定性
SEO人員無法掌控搜索引擎運行規則的細節,只能通過經驗來對網站進行優化,無法保證重要性的關鍵詞需要多久能排在首頁。另外,網站在搜索引擎的排名受到多種因素的綜合影響,有可能出現優化后排名沒有提升的情況。
原理
 通過總結搜索引擎的收錄和排名規律,對網站進行合理優化,使你的網站在百度及其他搜索引擎網站的搜索結果排名提高。
通過總結搜索引擎的收錄和排名規律,對網站進行合理優化,使你的網站在百度及其他搜索引擎網站的搜索結果排名提高。
爬行抓取,網絡爬蟲通過特定規則跟蹤網頁的鏈接,從一個鏈接爬到另一個鏈接,把爬行的數據存入本地數據庫
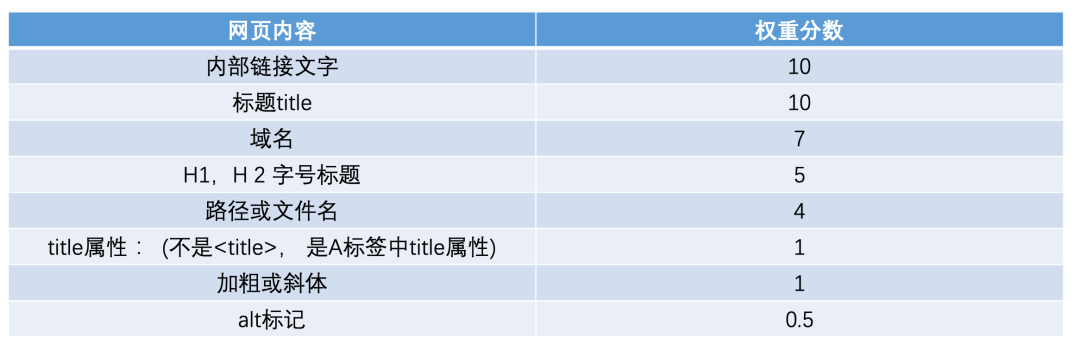
使用索引器對數據庫中重要信息進行處理,如標題、關鍵字、摘要,或者進行全文索引,在索引數據庫中,網頁文字內容,關鍵詞出現的位置、字體、顏色、加粗、斜體等相關信息都有相應記錄。
索引器將用戶提交的搜索詞與數據中的信息進行匹配,從索引數據庫中找出所有包含搜索詞的網頁,并且根據排名算法計算出哪些網頁應該排在前面,然后按照一定格式返回給用戶
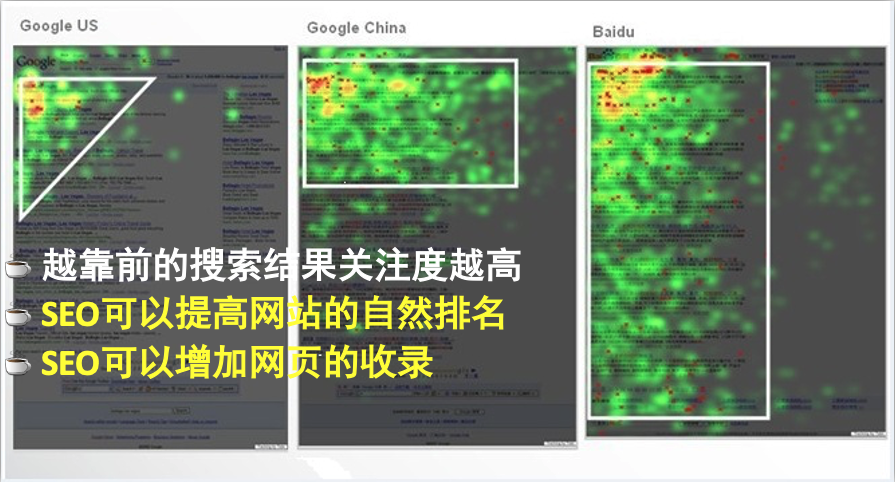
將檢索的結果返回給用戶,這就有一個先后順序,搜索引擎的排序主要由以下方面共同確定:
三劍客:TDK
何謂 TDK?做前端的同學也都應該對它們熟稔于心:<title>標簽、<meta name="description"> 標簽和 <meta name="keywords"> 標簽。顧名思義,它們分別代表當前頁面的標題、內容摘要和關鍵詞,對于 SEO 來說,title是其中最重要的一員。
<title> 標簽
從用戶的角度來看,它的值即用戶在搜索引擎搜索結果中以及瀏覽器標簽頁中看到的標題,如下圖:

title通常由當前頁面的標題加幾個關鍵詞組成,同時力求簡潔明了。總之,用最少的字讓別人知道你接下來要說啥,控制在 40 字以內。比如:
<title>【轉轉】二手交易網,二手手機交易網,58閑置交易APP,轉轉客服</title>
好的 title 不僅讓用戶知道該頁面要講什么東西,提前判斷有沒有我需要的內容,對于搜索引擎也同樣如此。所以,設置 title 時不但要注意以上幾點,更重要的是,不要重復!
description
它通常不參與搜索引擎的收錄及排名,但它會成為搜索引擎在搜索結果頁中展示網頁摘要的備選目標之一,當然也可能選取其他內容,比如網頁正文開頭部分的內容。以 title 部分的示例圖對應的頁面為例,它的 description 對應的內容是這樣的:
<meta?name="description"?content="58同城“轉轉”為二手買賣雙方提供快人一步的閑置交易平臺,擔保交易,微信支付,30秒發布,3天出手,讓您隨時隨地買個便宜,下載轉轉APP,快速出手賺的更多!轉轉官方客服請聯系微信公眾號,轉轉暫未開通客服電話,請不要相信假冒轉轉的客服電話。">
可以看到,正是搜索結果摘要顯示的內容。
有鑒于此, description的值要盡可能表述清楚頁面的內容,從而讓用戶更清楚的認識到即將前往的頁面是否對他有價值。同時字數最好控制在 80 - 100 字以內,各頁面間不要重復!
keywords
<meta name="keywords" content="轉轉,二手閑置,二手交易網,二手手機交易網,轉轉APP下載,轉轉客服">它主要為搜索引擎提供當前頁面的關鍵詞信息,關鍵詞之間用英文逗號間隔,通常建議三五個詞就足夠了,表達清楚該頁面的關鍵信息,建議控制在 50 字以內。切忌大量堆砌關鍵詞!
其他元信息標簽
SEO 三劍客 “TDK” 都屬于元信息標簽。元信息標簽即用來描述當前頁面 HTML 文檔信息的標簽們,與語義化標簽相對,它們通常不出現在用戶的視野中,所以,只是給機器看的信息,比如瀏覽器、搜索引擎等
meta:robots 標簽
撇開 “TDK”,其中與 SEO 相關的有一個 <meta name="robots"> 標簽(通常含有 name 屬性的 meta 標簽都會有一個 content 屬性相伴,這我們已經在 D 和 K “劍客”身上領略過了)。默認的,有這樣的標簽屬性設置:<meta name="robots" content="index,follow,archive">。它跟上文中提到的帶有 rel 屬性的 a 標簽略有相似。
| CONTENT | 含義 |
|---|---|
| INDEX | 允許抓取當前頁面 |
| NOINDEX | 不許抓取當前頁面 |
| FOLLOW | 允許從當前頁面的鏈接向下爬行 |
| NOFOLLOW | 不許從當前頁面的鏈接向下爬行 |
| ARCHIVE | 允許生成快照 |
| NOARCHIVE | 不許生成快照 |
通過以上三組值的相互組合,可以向搜索引擎表達很多有用的信息。比如,對于一個博客站來說,其文章列表頁其實對于搜索引擎收錄來說沒什么意義,但又不得不通過列表頁去爬取收錄具體的文章頁面,于是可以作如下嘗試:
<meta?name="robots"?content="index,follow,noarchive">
canoncial 和 alternate 標簽
還有一組標簽是含有 rel 屬性的 <link rel="" href="">標簽,它們分別是:
<link rel="canoncial" href="https://www.zhuanzhuan.com" />
<link rel="alternate" href="https://m.zhuanzhuan.com" />
先來看 canoncial 標簽。當站內存在多個內容相同或相似的頁面時,可以使用該標簽來指向其中一個作為規范頁面。要知道,不只是主路由不同,即便是 http 協議不同(http/https)、查詢字符串的微小差異,搜索引擎都會視為完全不同的頁面/鏈接。假如有很多這種雷同頁面,其權重便被無情稀釋了。比如文章列表頁有很多個,比如同一個商品頁面的鏈接含有不同的業務參數等。以后者為例,假設有如下鏈接:
www.zhuanzhuan.com/goods/xxxxwww.zhuanzhuan.com/goods/xxxx?…www.zhuanzhuan.com/goods/xxxx?…
此時我們可以為后兩者在 head 中添加 link 標簽:
<link?rel="canoncial"?href="www.shop.com/goods/xxxx"?/>
以此彰顯第一個鏈接的正統地位,告訴搜索引擎,其他那倆都是“庶出”,不必在意。假如搜索引擎遵守該標簽的約定,則會很大程度避免頁面權重的分散,不至影響搜索引擎的收錄及排名情況。它的含義與 http``301 永久重定向相似,不同之處在于,用戶訪問標記了 canonical 標簽的頁面并不會真的重定向到其他頁面。
再來看 alternate 標簽。假如你為移動端和 pc 端設備分別提供了單獨的站點,這個標簽或許能派上用場。有兩個鏈接如下:
https://www.zhuanzhuan.comhttps://m.zhuanzhuan.com
它們分別是轉轉網站首頁的 pc 端和移動端,于是就可以在它們的 head 標簽中提供如下標簽,標志其互相對應的關系:
<link?rel="canoncial"?href="https://www.zhuanzhuan.com"?/>
<link?rel="alternate"?href="https://m.zhuanzhuan.com"?media="only?screen?and?(max-width:?750px)"/>
前者放在移動端的頁面中,表示 pc 端頁面大哥馬首是瞻;后者則放在 pc 端對應的頁面中,表示當屏幕尺寸小于 750px 的時候,就應該我移動端頁面小弟上場服務了!
robots.txt
robots.txt 文件由一條或多條規則組成。每條規則可禁止(或允許)特定抓取工具抓取相應網站中的指定文件路徑。通俗一點的說法就是:告訴爬蟲,我這個網站,你哪些能看,哪些不能看的一個協議。
為什么要使用 robots.txt
搜索引擎(爬蟲),訪問一個網站,首先要查看當前網站根目錄下的robots.txt,然后依據里面的規則,進行網站頁面的爬取。也就是說,robots.txt起到一個基調的作用,也可以說是爬蟲爬取當前網站的一個行為準則。那使用robots.txt的目的,就很明確了。
更好地做定向SEO優化,重點曝光有價值的鏈接給爬蟲
將敏感文件保護起來,避免爬蟲爬取收錄
robots.txt的示例
如下:
#?first?group
User-agent:?Baiduspider
User-agent:?Googlebot
Disallow:?/article/#?second?group
User-agent:?*
Disallow:?/Sitemap:?https://www.xxx.com/sitemap.xml
以上:
允許百度和谷歌的搜索引擎訪問站內除 article 目錄下的所有文件/頁面(eg: article.html 可以,article/index.html 不可以);
不允許其他搜索引擎訪問網站;
指定網站地圖所在。
假如你允許整站都可以被訪問,則可以不在根目錄添加 robots 文件
文件規范
文件格式和命名
文件格式為標準
ASCII或UTF-8文件必須命名為
robots.txt只能有 1 個
robots.txt文件
文件位置 必須位于它所應用到的網站主機的根目錄下
常用的關鍵字
User-agent:網頁抓取工具的名稱
Disallow:不應抓取的目錄或網頁
Allow:應抓取的目錄或網頁
Sitemap:網站的站點地圖的位置
React & Vue 服務器渲染對SEO友好的SSR框架
React(Next.js):
https://www.nextjs.cn
https://github.com/vercel/next.js
Vue(Nuxt.js):
https://www.nuxtjs.cn
https://github.com/nuxt/nuxt.js
結束語
正確認識SEO,不過分追求SEO,網站還是以內容為主。
提供一個常用的SEO綜合查詢的地址(http://seo.chinaz.com),感興趣的可以去了解下。
參考文章
https://juejin.cn/post/6844904029923835911
https://www.sohu.com/a/320507630_120165202
最近組建了一個江西人的前端交流群,如果你是江西人可以加我微信 ruochuan12 拉你進群。
今日話題
時光飛逝,端午節三天假期馬上結束了,快樂的時光總是短暫的。歡迎分享、收藏、點贊、在看我的公眾號文章~
一個愿景是幫助5年內前端人走向前列的公眾號
可加我個人微信?ruochuan12,長期交流學習
推薦閱讀
我在阿里招前端,我該怎么幫你(可進模擬面試群)
2年前端經驗,做的項目沒技術含量,怎么辦?
點擊上方卡片關注我、加個星標

·················?若川簡介?·················
你好,我是若川,畢業于江西高校。現在是一名前端開發“工程師”。寫有《學習源碼整體架構系列》多篇,在知乎、掘金收獲超百萬閱讀。
從2014年起,每年都會寫一篇年度總結,已經寫了7篇,點擊查看年度總結。
同時,活躍在知乎@若川,掘金@若川。致力于分享前端開發經驗,愿景:幫助5年內前端人走向前列。





)








![羅馬數字 java_【leetcode刷題】[簡單]13.羅馬數字轉整數(roman to integer)-java](http://pic.xiahunao.cn/羅馬數字 java_【leetcode刷題】[簡單]13.羅馬數字轉整數(roman to integer)-java)



)
