python并行運算庫
HiPlot is Facebook’s Python library to support visualization of high-dimensional data table, released this January. It is particularly well known for its sophisticated interactive parallel plot.
HiPlot是Facebook的Python庫,用于支持高維數據表的可視化,該庫于今年1月發布。 它以其復雜的交互式并行繪圖而聞名。
Before anything, take a look at their compelling demo video. This explains how high its interactivity is, which we would appreciate when we do EDA.
在開始之前,請看一下他們引人注目的演示視頻 。 這解釋了它的交互性有多高,在進行EDA時我們將不勝感激。
, and play around their demo app with sample data here. Do not forget to select the range on axis and hold-and-move to check the interactivity.
,并在此處使用示例數據試用他們的演示應用程序。 不要忘記選擇軸上的范圍并按住不放以檢查交互性。
HiPlot is not just good looking, but also has following four appreciated characteristics:
HiPlot不僅外觀漂亮,而??且還具有以下四個令人贊賞的特征:
Very easy to implement
非常容易實現
Implementing the parallel plot using their hiplot module is literally by one line and almost a no-brainer.
實際上,使用他們的hiplot模塊實現并行繪圖只需一行,幾乎可以輕松完成 。
Highly interactive
高度互動
As you can see in the demo video above, the plot is highly interactive. Giving some mouse clicks lets you deep dive to any subset of data.
正如您在上面的演示視頻中看到的那樣,該情節具有高度的交互性。 只需單擊一下鼠標,您就可以深入探究任何數據子集。
Run fast
快跑
Despite its appearance, the runtime to visualize the large dataset as a parallel plot is short. Let’s see this later.
盡管有它的外觀,但以并行繪圖的形式可視化大型數據集的運行時間很短。 讓我們稍后再看。
Native HTML rendering function
本機HTML呈現功能
They prepared a native function to turn the parallel plot to HTML code (hooray!!) Produced HTML page can be downloaded as .html file or deployed from Flask with almost no additional rendering effort. I tried to run it on heroku through Flask in the exercise below.
他們準備了一個本機函數,可以將并行繪圖轉換為HTML代碼(萬歲!)。生成HTML頁面可以作為.html文件下載,也可以從Flask進行部署,而幾乎無需進行其他渲染。 我在下面的練習中嘗試通過Flask在Heroku上運行它。
Thanks to these benefits, I believe HiPlot is one of first-choice tool sets for EDA in data analysis project before jumping in other time-consuming visualizations.
由于這些好處,我相信HiPlot是數據分析項目中EDA的首選工具集之一,然后再跳入其他耗時的可視化過程。
Let’s take a look at each of the benefits one by one.
讓我們一一看一下每個好處。
Iris數據入門 (Getting Started with Iris Data)
Let’s see how easy it is to get you started with HiPlot using the famous iris data set.
讓我們看看使用著名的虹膜數據集開始使用HiPlot是多么容易。

Installation of HiPlot is just as easy as ordinary modules. Just use pip:
HiPlot的安裝與普通模塊一樣容易。 只需使用pip:
pip install -U hiplotTo use external csv file, you even do not have to use Pandas DataFrame. They prepared a native method to run parallel plot directly from csv file as such Experiment.from_csv(). When you need to use DataFrame, use Experiment.from_dataframe() instead. And it is totally fine to use Jupyter Notebook.
要使用外部csv文件,您甚至不必使用Pandas DataFrame。 他們準備了一種本地方法,可以直接從csv文件運行平行繪圖,例如Experiment.from_csv() 。 當您需要使用DataFrame時,請改用Experiment.from_dataframe() 。 并且使用Jupyter Notebook完全可以。
import hiplot as hip
iris_hiplot = hip.Experiment.from_csv('iris.csv')
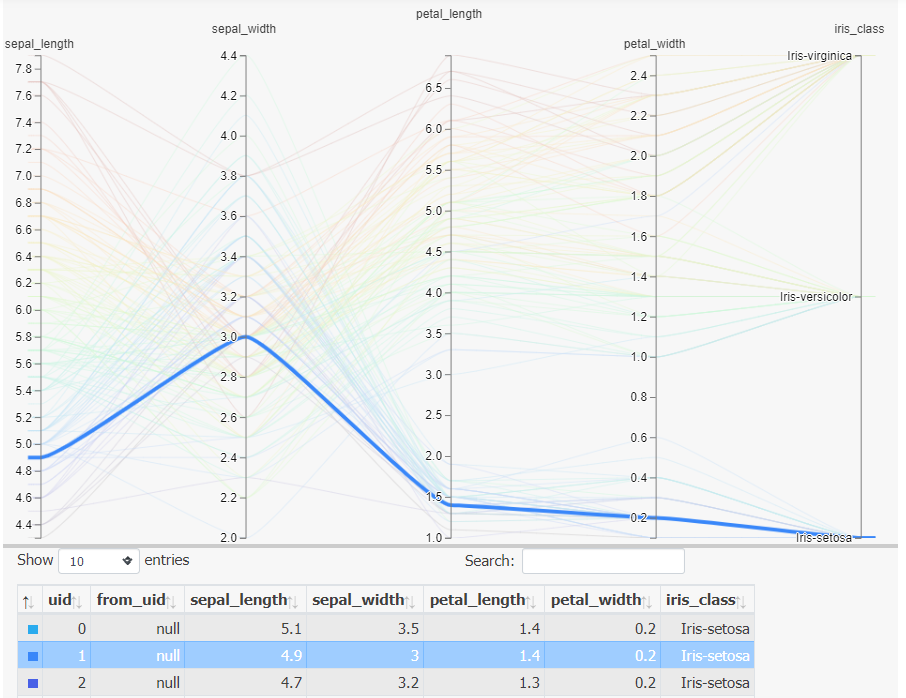
iris_hiplot.display()And here’s what you will see:
這是您將看到的:

HiPlot具有高度的交互性 (HiPlot is Highly Interactivity)
You are going to love HiPlot once you start playing around.
一旦開始玩耍,您就會愛上HiPlot。
As you already saw in the demo movie above, here are some examples of the uses of interactive chart.
正如您在上面的演示影片中已經看到的那樣,下面是一些使用交互式圖表的示例。

HiPlot運行快 (HiPlot Runs Fast)
To test the run time to show the parallel plot for larger data, I used Kaggle FIFA 19 complete player dataset. It is a dataset from a video game “FIFA 19”, as the name explains a game of soccer (or you may call football), where you can play as a team manager of a actual soccer team or as an actual soccer player. The dataset contains the all playable characters list with their skill levels (e.g. how good they are at heading, free kick etc.) The number of rows is 18,207 and of columns is 89. The first row is Messi from Argentina.
為了測試運行時顯示更大數據的平行圖,我使用了Kaggle FIFA 19完整播放器數據集 。 它是來自視頻游戲“ FIFA 19”的數據集,顧名思義,這是一場足球比賽(或者您可以稱為足球),您可以在其中扮演實際足球隊的球隊經理或實際足球運動員的角色。 數據集包含所有可玩角色列表以及他們的技能水平(例如,他們的頭球,任意球等水平)。行數為18207,列數為89。第一行是阿根廷的梅西。
To do the performance test, I intentionally make the data size 10 times larger. I concatenated the FAFA 19 dataset 10 times, ended up with having 182,070 rows. Usually, visualizing large data set takes time to run and causes huge latency after the chart shows up. Interactivity? Forget and rerun the script! What about HiPlot?
為了進行性能測試,我故意將數據大小增大了10倍。 我將FAFA 19數據集連接了10次,最終有182,070行。 通常,可視化大數據集需要時間才能運行,并且在圖表顯示后會導致巨大的延遲。 互動性? 忘記并重新運行腳本! 那HiPlot呢?
I ran HiPlot on 182,070 rows x 89 columns dataset without any edits. It took 81 seconds to process and additional 5 mins to display the graph. I think it is short enough for its size.
我在182,070行x 89列數據集上運行了HiPlot,沒有進行任何編輯。 處理花了81秒,另外花了5分鐘顯示圖形。 我認為它足夠短。
fifa = pd.read_csv('fifa19_data.csv',index_col='Unnamed: 0')
fifa_extended = pd.concat([fifa,fifa,fifa,fifa,fifa,fifa,fifa,fifa,fifa,fifa],axis=0,ignore_index=True,sort=False)
fifa_hiplot = hip.Experiment.from_dataframe(fifa_extended)
fifa_hiplot.display()
What is even greater about HiPlot is that data size does not harm its interactivity too much. After selecting the range on axis, it tries to show only the plots belonging to the range. This change re-renders the plot almost within a second, which is surprising quick compared to other visualization tools.
HiPlot更重要的是,數據大小不會太大地損害其交互性。 在軸上選擇范圍后,它將嘗試僅顯示屬于該范圍的圖。 此更改幾乎在一秒鐘內即可重新渲染圖,與其他可視化工具相比,這是令人驚訝的快速。

本機HTML渲染功能 (Native HTML Rendering Function)
When we want to share the plot with someone else, we may run the code on notebook and copy-and-paste the plot, but it removes the graph interactivity.
當我們想與其他人共享繪圖時,我們可以在筆記本上運行代碼并復制并粘貼繪圖,但是它刪除了圖形交互性。
HiPlot has its native HTML rendering function Experience.to_html(), which returns HTML file with the plot embedded with just one line of code.
HiPlot具有其本機HTML呈現功能Experience.to_html() ,該函數返回HTML文件,其中嵌入的圖僅包含一行代碼。
Let me go with the original rows and fewer columns from FIFA 19 dataset for simplicity.
為了簡單起見,讓我來看一下FIFA 19數據集中的原始行和較少的列。
fifa = pd.read_csv('fifa19_data.csv',index_col='Unnamed: 0')
fifa_small = fifa[['Age','Nationality','Value','Height', 'Weight', 'Crossing', 'Finishing', 'HeadingAccuracy', 'ShortPassing', 'Volleys', 'Dribbling', 'Curve', 'FKAccuracy', 'LongPassing', 'BallControl', 'Acceleration']]
fifa_hiplot = hip.Experiment.from_dataframe(fifa_small)
fifa_hiplot.display()This code will produce a new .html file on your local with the plot.
此代碼將在您的本地圖上生成一個新的.html文件。
_ = fifa_hiplot.to_html("fifa_hiplot.html")Now you can share the .html file directly with your team members to let them play around the plot.
現在,您可以直接與團隊成員共享.html文件,讓他們在劇情中玩耍。

Since Experience.to_html() returns html code, it’s even just easily connected to web server and deploy the plot externally.
由于Experience.to_html()返回html代碼,因此它甚至可以輕松連接到Web服務器并在外部部署繪圖。
Let me try it with Flask and Heroku. As I explained a lot here, I needed four files pushed to GitHub repository, to be synced with Heroku app.
讓我與Flask和Heroku一起嘗試。 正如我在這里所做的很多解釋,我需要將四個文件推送到GitHub存儲庫,以便與Heroku應用程序同步。
fifa19_data.csv: FIFA19 dataset file.
fifa19_data.csv :FIFA19數據集文件。
hiplot_fifa.py: Python code to run and kick off Flask app.
hiplot_fifa.py :運行和啟動Flask應用程序的Python代碼。
import hiplot as hip
import pandas as pd
from flask import Flaskapp = Flask(__name__)@app.route('/')
def fifa_experiment():
fifa = pd.read_csv('fifa19_data.csv',index_col='Unnamed: 0')
fifa_hiplot = hip.Experiment.from_dataframe(fifa[['Age','Nationality','Value','Height', 'Weight', 'Crossing','Finishing', 'HeadingAccuracy', 'ShortPassing', 'Volleys', 'Dribbling', 'Curve', 'FKAccuracy', 'LongPassing', 'BallControl', 'Acceleration']])
return fifa_hiplot.to_html()if __name__ == "__main__":
app.run()requirements.txt: a requirement file for Heroku to install the necessary modules.
requirements.txt :Heroku安裝必需模塊的需求文件。
gunicorn==19.9.0
pandas==0.24.2
hiplot==0.1.12
Flask==1.1.1Procfile: a start-up command for Heroku to run when it starts the app.
Procfile :Heroku在啟動應用程序時運行的啟動命令。
web: gunicorn hiplot_fifa:appSync the code files and make a set up on Heroku. Opening the web app gives the following HiPlot graph page, which is globally accessible through domain name.
同步代碼文件,并在Heroku上進行設置。 打開Web應用程序將顯示以下HiPlot圖表頁面,該頁面可通過域名進行全局訪問。
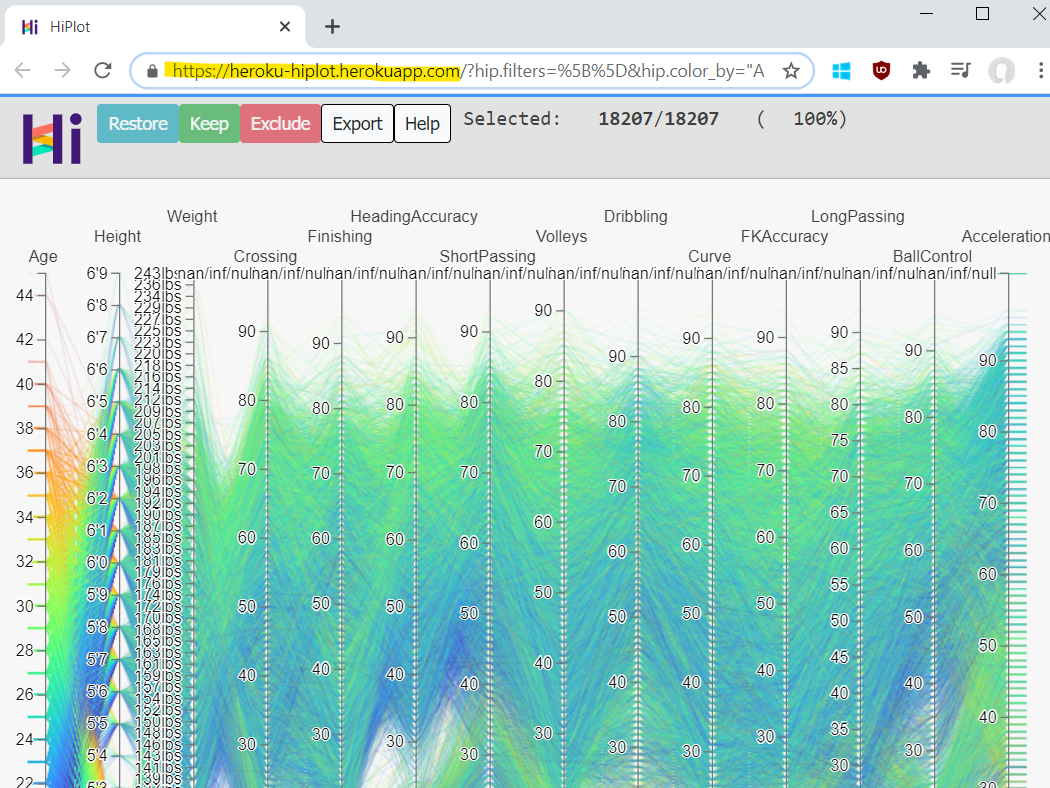
尾注 (Ending Note)
In this post, I introduced the HiPlot the current best option of parallel plot to start EDA to take a look at the variable interaction overview.
在本文中,我介紹了HiPlot(當前并行繪圖的最佳選擇)以啟動EDA,以了解變量交互作用概述。
It is easy to run, highly interactive, fast, and with much shareable through HTML file or code.
它易于運行,高度交互,快速且可通過HTML文件或代碼共享。
Although the data science projects definitely need further investigation such as looking at the shape of distribution of values, imputing the missing values etc, HiPlot would be a much help to start off the data preprocessing and understanding.
盡管數據科學項目確實需要進一步研究,例如查看值的分布形狀,估算缺失值等,但HiPlot將對啟動數據預處理和理解提供很大幫助。
翻譯自: https://towardsdatascience.com/introduction-to-best-parallel-plot-python-library-hiplot-8387f5786d97
python并行運算庫
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/275765.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/275765.shtml 英文地址,請注明出處:http://en.pswp.cn/news/275765.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Asp.net 文件上傳的 FileUpload FileName 和 FileUpload PostedFile.FileName的細節問題

java 友元_C++ 友元函數 | 菜鳥教程

剛學編程的程序員必備這5大編程網站,你知道幾個?

【贈書福利】不扶好眼鏡,請別打開這本挑戰JS語言特性的書

MySQL存儲過程之事務管理
![羅馬數字 java_【leetcode刷題】[簡單]13.羅馬數字轉整數(roman to integer)-java](http://pic.xiahunao.cn/羅馬數字 java_【leetcode刷題】[簡單]13.羅馬數字轉整數(roman to integer)-java)
羅馬數字 java_【leetcode刷題】[簡單]13.羅馬數字轉整數(roman to integer)-java

我在工作中是如何使用Git的

克服浮躁_設計思維:您克服并贏得低迷的最終工具。

mongodb數組字段prefix匹配返回
)
java參數化查詢_小博老師解析Java核心技術 ——JDBC參數化查詢(二)

Lightbox 效果

前端搶飯碗系列之Vue項目如何做單元測試

React Native組件開發指南

java activiti jbpm_activiti和jbpm工作流引擎哪個比較好?


識別人聲_演唱人聲的5個技巧

你知道source map如何幫你定位源碼么?

OOP 中的 方法調用、接口、鴨式辯型、訪問者模式

Substitution控件MethodName無法取到Session的解決辦法
