[機器學習]推薦系統之協同過濾算法
在現今的推薦技術和算法中,最被大家廣泛認可和采用的就是基于協同過濾的推薦方法。本文將帶你深入了解協同過濾的秘密。下面直接進入正題.
1. 什么是推薦算法
推薦算法最早在1992年就提出來了,但是火起來實際上是最近這些年的事情,因為互聯網的爆發,有了更大的數據量可以供我們使用,推薦算法才有了很大的用武之地。
最開始,所以我們在網上找資料,都是進yahoo,然后分門別類的點進去,找到你想要的東西,這是一個人工過程,到后來,我們用google,直接搜索自己需要的內容,這些都可以比較精準的找到你想要的東西,但是,如果我自己都不知道自己要找什么腫么辦?最典型的例子就是,如果我打開豆瓣找電影,或者我去買說,我實際上不知道我想要買什么或者看什么,這時候推薦系統就可以派上用場了。
2. 推薦算法的條件
現在的各種各樣的推薦算法,但是不管怎么樣,都繞不開幾個條件,這是推薦的基本條件
1.根據和你共同喜好的人來給你推薦?
2.根據你喜歡的物品找出和它相似的來給你推薦?
3.根據你給出的關鍵字來給你推薦,這實際上就退化成搜索算法了?
4.根據上面的幾種條件組合起來給你推薦
3. 推薦算法分類
推薦算法大致可以分為三類:
3.1 基于內容的推薦算法
基于內容的推薦算法,原理是用戶喜歡和自己關注過的Item在內容上類似的Item,比如你看了哈利波特I,基于內容的推薦算法發現哈利波特II-VI,與你以前觀看的在內容上面(共有很多關鍵詞)有很大關聯性,就把后者推薦給你,這種方法可以避免Item的冷啟動問題(冷啟動:如果一個Item從沒有被關注過,其他推薦算法則很少會去推薦,但是基于內容的推薦算法可以分析Item之間的關系,實現推薦),弊端在于推薦的Item可能會重復,典型的就是新聞推薦,如果你看了一則關于MH370的新聞,很可能推薦的新聞和你瀏覽過的,內容一致;另外一個弊端則是對于一些多媒體的推薦(比如音樂、電影、圖片等)由于很難提內容特征,則很難進行推薦,一種解決方式則是人工給這些Item打標簽。
3.2 協同過濾推薦算法
協同過濾算法,原理是用戶喜歡那些具有相似興趣的用戶喜歡過的商品,比如你的朋友喜歡電影哈利波特I,那么就會推薦給你,這是最簡單的基于用戶的協同過濾算法(user-based collaboratIve filtering),還有一種是基于Item的協同過濾算法(item-based collaborative filtering),這兩種方法都是將用戶的所有數據讀入到內存中進行運算的,因此成為Memory-based Collaborative Filtering,另一種則是Model-based collaborative filtering,包括Aspect Model,pLSA,LDA,聚類,SVD,Matrix Factorization等,這種方法訓練過程比較長,但是訓練完成后,推薦過程比較快。
3.3基于知識的推薦算法。
最后一種方法是基于知識的推薦算法,也有人將這種方法歸為基于內容的推薦,這種方法比較典型的是構建領域本體,或者是建立一定的規則,進行推薦。 混合推薦算法,則會融合以上方法,以加權或者串聯、并聯等方式盡心融合。 當然,推薦系統還包括很多方法,其實機器學習或者數據挖掘里面的方法,很多都可以應用在推薦系統中,比如說LR、GBDT、RF(這三種方法在一些電商推薦里面經常用到),社交網絡里面的圖結構等,都可以說是推薦方法。
今天這篇文章要講的基于用戶的協同過濾算法.
3 什么是協同過濾
協同過濾是利用集體智慧的一個典型方法。要理解什么是協同過濾 (Collaborative Filtering, 簡稱 CF),首先想一個簡單的問題,如果你現在想看個電影,但你不知道具體看哪部,你會怎么做?大部分的人會問問周圍的朋友,看看最近有什么好看的電影推薦,而我們一般更傾向于從口味比較類似的朋友那里得到推薦。這就是協同過濾的核心思想。
換句話說,就是借鑒和你相關人群的觀點來進行推薦,很好理解。
4 協同過濾的實現
要實現協同過濾的推薦算法,要進行以下三個步驟:
4.1)收集數據
4.2)找到相似用戶和物品
4.3進行推薦
4.1 收集數據
這里的數據指的都是用戶的歷史行為數據,比如用戶的購買歷史,關注,收藏行為,或者發表了某些評論,給某個物品打了多少分等等,這些都可以用來作為數據供推薦算法使用,服務于推薦算法。需要特別指出的在于,不同的數據準確性不同,粒度也不同,在使用時需要考慮到噪音所帶來的影響。
4.2找到相似用戶和物品
這一步也很簡單,其實就是計算用戶間以及物品間的相似度。以下是幾種計算相似度的方法:?

4.3 進行推薦
在知道了如何計算相似度后,就可以進行推薦了。
在協同過濾中,有兩種主流方法:
1)基于用戶的協同過濾
2)基于物品的協同過濾
具體怎么來闡述他們的原理呢,看個圖大家就明白了
基于用戶的 CF 的基本思想相當簡單,基于用戶對物品的偏好找到相鄰鄰居用戶,然后將鄰居用戶喜歡的推薦給當前用戶。計算上,就是將一個用戶對所有物品的偏好作為一個向量來計算用戶之間的相似度,找到 K 鄰居后,根據鄰居的相似度權重以及他們對物品的偏好,預測當前用戶沒有偏好的未涉及物品,計算得到一個排序的物品列表作為推薦。 下圖給出了一個例子,對于用戶 A,根據用戶的歷史偏好,這里只計算得到一個鄰居 - 用戶 C,然后將用戶 C 喜歡的物品 D 推薦給用戶 A。?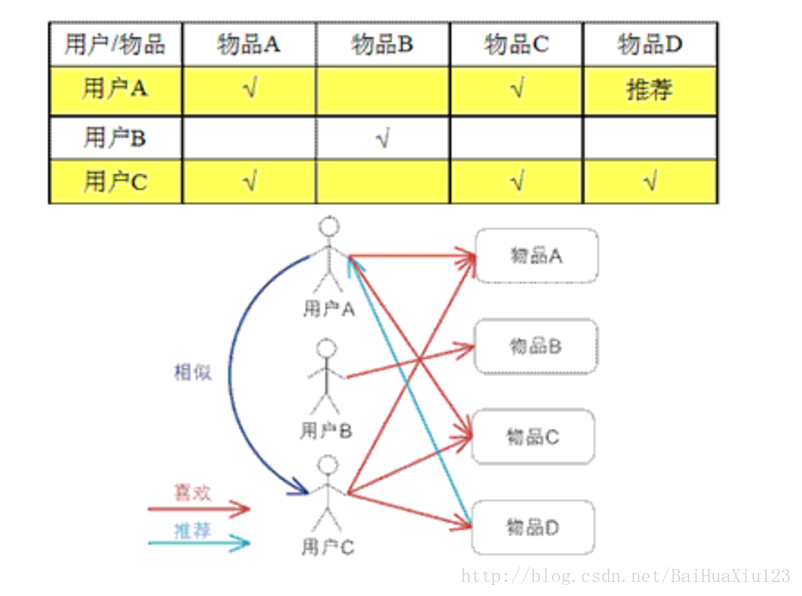
基于物品的 CF 的原理和基于用戶的 CF 類似,只是在計算鄰居時采用物品本身,而不是從用戶的角度,即基于用戶對物品的偏好找到相似的物品,然后根據用戶的歷史偏好,推薦相似的物品給他。從計算的角度看,就是將所有用戶對某個物品的偏好作為一個向量來計算物品之間的相似度,得到物品的相似物品后,根據用戶歷史的偏好預測當前用戶還沒有表示偏好的物品,計算得到一個排序的物品列表作為推薦。下圖給出了一個例子,對于物品 A,根據所有用戶的歷史偏好,喜歡物品 A 的用戶都喜歡物品 C,得出物品 A 和物品 C 比較相似,而用戶 C 喜歡物品 A,那么可以推斷出用戶 C 可能也喜歡物品 C。?
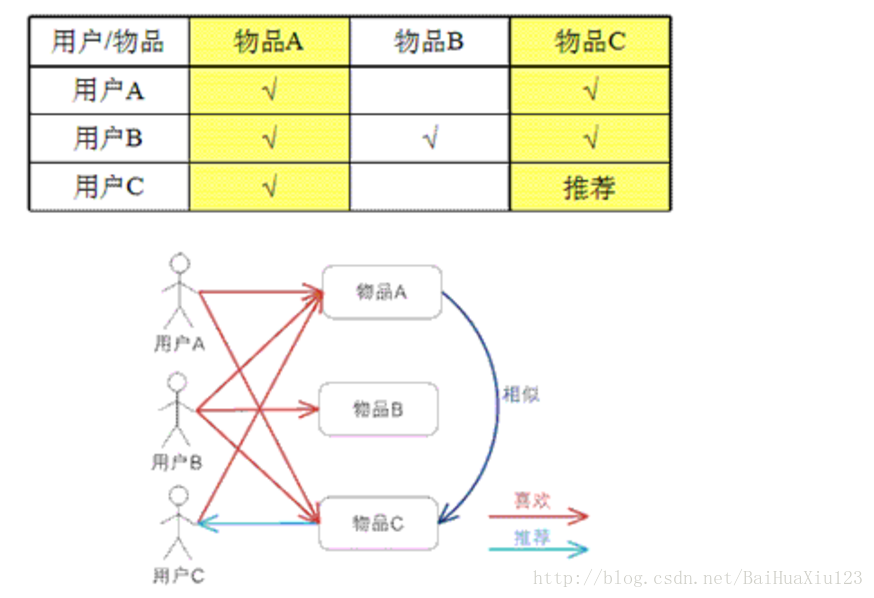
算法存在的問題
這個算法實現起來也比較簡單,但是在實際應用中有時候也會有問題的。
比如一些非常流行的商品可能很多人都喜歡,這種商品推薦給你就沒什么意義了,所以計算的時候需要對這種商品加一個權重或者把這種商品完全去掉也行。
再有,對于一些通用的東西,比如買書的時候的工具書,如現代漢語詞典,新華字典神馬的,通用性太強了,推薦也沒什么必要了。
適用場景
在非社交網絡的網站中,內容內在的聯系是很重要的推薦原則,它比基于相似用戶的推薦原則更加有效。比如在購書網站上,當你看一本書的時候,推薦引擎會給你推薦相關的書籍,這個推薦的重要性遠遠超過了網站首頁對該用戶的綜合推薦。可以看到,在這種情況下,Item CF 的推薦成為了引導用戶瀏覽的重要手段。同時 Item CF 便于為推薦做出解釋,在一個非社交網絡的網站中,給某個用戶推薦一本書,同時給出的解釋是某某和你有相似興趣的人也看了這本書,這很難讓用戶信服,因為用戶可能根本不認識那個人;但如果解釋說是因為這本書和你以前看的某本書相似,用戶可能就覺得合理而采納了此推薦。
具體實現
# -*- coding=utf-8 -*-import math
import sys
from texttable import Texttable # # 使用 |A&B|/sqrt(|A || B |)計算余弦距離 # # # def calcCosDistSpe(user1,user2): avg_x=0.0 avg_y=0.0 for key in user1: avg_x+=key[1] avg_x=avg_x/len(user1) for key in user2: avg_y+=key[1] avg_y=avg_y/len(user2) u1_u2=0.0 for key1 in user1: for key2 in user2: if key1[1] > avg_x and key2[1]>avg_y and key1[0]==key2[0]: u1_u2+=1 u1u2=len(user1)*len(user2)*1.0 sx_sy=u1_u2/math.sqrt(u1u2) return sx_sy # # 計算余弦距離 # # def calcCosDist(user1,user2): sum_x=0.0 sum_y=0.0 sum_xy=0.0 for key1 in user1: for key2 in user2: if key1[0]==key2[0] : sum_xy+=key1[1]*key2[1] sum_y+=key2[1]*key2[1] sum_x+=key1[1]*key1[1] if sum_xy == 0.0 : return 0 sx_sy=math.sqrt(sum_x*sum_y) return sum_xy/sx_sy # # # 相似余弦距離 # # # def calcSimlaryCosDist(user1,user2): sum_x=0.0 sum_y=0.0 sum_xy=0.0 avg_x=0.0 avg_y=0.0 for key in user1: avg_x+=key[1] avg_x=avg_x/len(user1) for key in user2: avg_y+=key[1] avg_y=avg_y/len(user2) for key1 in user1: for key2 in user2: if key1[0]==key2[0] : sum_xy+=(key1[1]-avg_x)*(key2[1]-avg_y) sum_y+=(key2[1]-avg_y)*(key2[1]-avg_y) sum_x+=(key1[1]-avg_x)*(key1[1]-avg_x) if sum_xy == 0.0 : return 0 sx_sy=math.sqrt(sum_x*sum_y) return sum_xy/sx_sy # # 讀取文件 # # def readFile(file_name): contents_lines=[] f=open(file_name,"r") contents_lines=f.readlines() f.close() return contents_lines # # 解壓rating信息,格式:用戶id\t硬盤id\t用戶rating\t時間 # 輸入:數據集合 # 輸出:已經解壓的排名信息 # def getRatingInformation(ratings): rates=[] for line in ratings: rate=line.split("\t") rates.append([int(rate[0]),int(rate[1]),int(rate[2])]) return rates # # 生成用戶評分的數據結構 # # 輸入:所以數據 [[2,1,5],[2,4,2]...] # 輸出:1.用戶打分字典 2.電影字典 # 使用字典,key是用戶id,value是用戶對電影的評價, # rate_dic[2]=[(1,5),(4,2)].... 表示用戶2對電影1的評分是5,對電影4的評分是2 # def createUserRankDic(rates): user_rate_dic={} item_to_user={} for i in rates: user_rank=(i[1],i[2]) if i[0] in user_rate_dic: user_rate_dic[i[0]].append(user_rank) else: user_rate_dic[i[0]]=[user_rank] if i[1] in item_to_user: item_to_user[i[1]].append(i[0]) else: item_to_user[i[1]]=[i[0]] return user_rate_dic,item_to_user # # 計算與指定用戶最相近的鄰居 # 輸入:指定用戶ID,所以用戶數據,所以物品數據 # 輸出:與指定用戶最相鄰的鄰居列表 # def calcNearestNeighbor(userid,users_dic,item_dic): neighbors=[] #neighbors.append(userid) for item in users_dic[userid]: for neighbor in item_dic[item[0]]: if neighbor != userid and neighbor not in neighbors: neighbors.append(neighbor) neighbors_dist=[] for neighbor in neighbors: dist=calcSimlaryCosDist(users_dic[userid],users_dic[neighbor]) #calcSimlaryCosDist calcCosDist calcCosDistSpe neighbors_dist.append([dist,neighbor]) neighbors_dist.sort(reverse=True) #print neighbors_dist return neighbors_dist # # 使用UserFC進行推薦 # 輸入:文件名,用戶ID,鄰居數量 # 輸出:推薦的電影ID,輸入用戶的電影列表,電影對應用戶的反序表,鄰居列表 # def recommendByUserFC(file_name,userid,k=5): #讀取文件數據 test_contents=readFile(file_name) #文件數據格式化成二維數組 List[[用戶id,電影id,電影評分]...] test_rates=getRatingInformation(test_contents) #格式化成字典數據 # 1.用戶字典:dic[用戶id]=[(電影id,電影評分)...] # 2.電影字典:dic[電影id]=[用戶id1,用戶id2...] test_dic,test_item_to_user=createUserRankDic(test_rates) #尋找鄰居 neighbors=calcNearestNeighbor(userid,test_dic,test_item_to_user)[:k] recommend_dic={} for neighbor in neighbors: neighbor_user_id=neighbor[1] movies=test_dic[neighbor_user_id] for movie in movies: #print movie if movie[0] not in recommend_dic: recommend_dic[movie[0]]=neighbor[0] else: recommend_dic[movie[0]]+=neighbor[0] #print len(recommend_dic) #建立推薦列表 recommend_list=[] for key in recommend_dic: #print key recommend_list.append([recommend_dic[key],key]) recommend_list.sort(reverse=True) #print recommend_list user_movies = [ i[0] for i in test_dic[userid]] return [i[1] for i in recommend_list],user_movies,test_item_to_user,neighbors # # # 獲取電影的列表 # # # def getMoviesList