參考
5.6 深度卷積神經網絡(AlexNet)
在LeNet提出后的將近20年里,神經網絡一度被其他機器學習方法超越,如支持向量機。雖然LeNet可以在早期的小數據集上取得好的成績,但是在更大的真實數據集上的表現并不盡如人意。一方面,神經網絡計算復雜。雖然20世紀90年代也有過一些針對神經網絡的加速硬件,但并沒有像之后GPU那樣大量普及。因此,訓練一個多通道、多層和有大量參數的卷積神經網絡在當年很難完成。另一方面,當年研究者還沒有大量深入研究參數初始化和非凸優化算法等諸多領域,導致復雜的神經網絡的訓練通常較困難。
在很長一段時間里更流行的是研究者通過勤勞與智慧所設計并生成的手工特征。這類圖像分類研究的主要流程是:
- 獲取圖像數據集;
- 使用已有的特征提取函數生成圖像的特征;
- 使用機器學習模型對圖像的特征分類。
當時認為的機器學習部分僅限最后這一步。如果那時候跟機器學習研究者交談,他們會認為機器學習既重要又優美。優雅的定理證明了許多分類器的性質。機器學習領域生機勃勃、嚴謹而且極其有用。然而,如果跟計算機視覺研究者交談,則是另外一幅景象。他們會告訴你圖像識別里“不可告人”的現實是:計算機視覺流程中真正重要的是數據和特征。也就是說,使用較干凈的數據集和較有效的特征甚至比機器學習模型的選擇對圖像分類結果的影響更大。
5.6.1 學習特征表示
研究者相信,多層神經網絡可能可以學得數據的多級表征,并逐級表示越來越抽象的概念。以圖像分類為例:在多層神經網絡中,圖像的第一級的表示可以是在特定位置和角度是否出現邊緣;而第二級的表示說不定能夠將這些邊緣組合出有趣的模式,如花紋;在第三級的表示中,也許上以及的花紋能進一步匯合成對應物體特定部位的模式。這樣逐級表示下去,最終,模型能夠較容易根據最后一級的表示完成分類任務。需要強調的是,輸入的逐級表示由多層模型中的參數決定,而這些參數都是學習出來的。
5.6.1.1 缺失要素一: 數據
包含許多特征的深度模型需要大量的有標簽的數據才能表現得比其他經典方法更好。限于早期計算機有限的存儲和90年代有限的研究預算,大部分研究只基于小的公開數據集。例如,不少研究論文基于加州大學歐文分校(UCI)提供的若干個公開數據集,其中許多數據集只有幾百至幾千張圖像。這一狀況在2010年前后興起的大數據浪潮中得到改善。特別是,2009年誕生的ImageNet數據集包含了1,000大類物體,每類有多達數千張不同的圖像。這一規模是當時其他公開數據集無法與之相提并論的。ImageNet數據集同時推動計算機視覺和機器學習研究進入新的階段,使此前的傳統方法不再有優勢。
5.6.1.2 缺失要素二: 硬件
深度學習對計算資源要求很高。早期的硬件計算能力有限,這使訓練較復雜的神經網絡變得很困難。然而,通用GPU的到來改變了這一格局。很久以來,GPU都是為圖像處理和計算機游戲設計的,尤其是針對大吞吐量的矩陣和向量乘法從而服務于基本的圖形變換。值得慶幸的是,這其中的數學表達與深度網絡中的卷積層的表達類似。通用GPU這個概念在2001年開始興起,涌現出諸如OpenCL和CUDA之類的編程框架。這使得GPU也在2010年前后開始被機器學習社區使用。
5.6.2 AlexNet
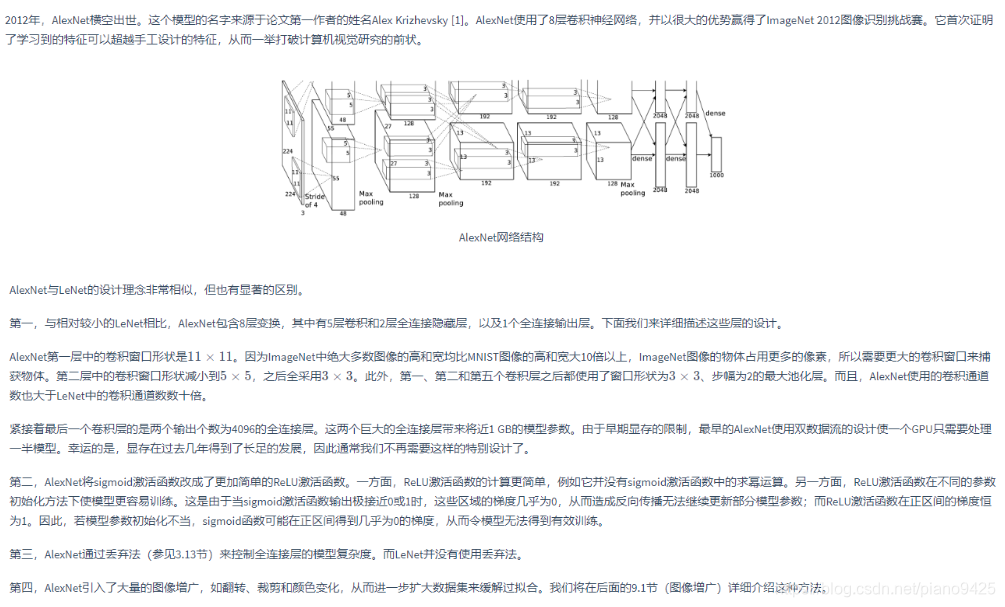
下面實現簡化過的AlexNet
import time
import torch
import torch.nn as nn
import torch.optim as optim
import torchvisionimport sys
sys.path.append("..")
import d2lzh_pytorch as d2ldevice = torch.device("cuda" if torch.cuda.is_available() else 'cpu')class AlexNet(nn.Module):def __init__(self):super(AlexNet, self).__init__()self.conv = nn.Sequential(# N = (W - F + 2P)/S + 1,除不盡向下取整(記不清了,向上取整對不上,向下取整剛好對上...)nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding: (256, 1, 224, 224) -> (256, 96, 54,54)nn.ReLU(),nn.MaxPool2d(3, 2), # kernel_size, stride: (256, 96, 54, 54) -> (256, 96, 26, 26)# 減少卷積窗口,使用填充為2來使得輸入的高和寬一致,且增大輸出通道數nn.Conv2d(96, 256, 5, 1, 2), # (256, 96, 26, 26) -> (256, 256, 26, 26)nn.ReLU(),nn.MaxPool2d(3, 2), # (256, 256, 26, 26) -> (256, 256, 12, 12)# 連續3個卷積層,且使用更小的卷積窗口。除了最后的卷積層外,進一步增大了輸出通道數。# 前兩個卷積層不使用池化層來減小輸入的高和寬nn.Conv2d(256, 384, 3, 1, 1), # (256, 256, 12, 12) -> (256, 384, 12, 12)nn.ReLU(),nn.Conv2d(384, 384, 3, 1, 1), # (256, 384, 12, 12) -> (256, 384, 12, 12)nn.ReLU(),nn.Conv2d(384, 256, 3, 1, 1), # (256, 384, 12, 12) -> (256, 256, 12, 12)nn.ReLU(),nn.MaxPool2d(3,2) # (256, 256, 12, 12) -> (256, 256, 5, 5))# 這里全連接層的輸出個數比LeNet中的大數倍。使用丟棄層來緩解過擬合self.fc = nn.Sequential(nn.Linear(256*5*5, 4096),nn.ReLU(),nn.Dropout(0.5),nn.Linear(4096, 4096),nn.ReLU(),nn.Dropout(0.5),# 輸出層。由于這里使用Fashion-MNIST,所以用類別數為10nn.Linear(4096, 10),)def forward(self, img):feature = self.conv(img) # 256 * 1 * 224 * 224output = self.fc(feature.view(img.shape[0], -1))return output
net = AlexNet()
print(net)

5.6.3 讀取數據
def load_data_fashion_mnist(batch_size, resize= None, root="~/Datasets/FashionMNIST"):trans = []if resize:trans.append(torchvision.transforms.Resize(size = resize))trans.append(torchvision.transforms.ToTensor())transform = torchvision.transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform)mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform)train_iter = torch.utils.data.DataLoader(mnist_train, batch_size = batch_size, shuffle=True, num_workers=4)test_iter = torch.utils.data.DataLoader(mnist_test, batch_size = batch_size, shuffle=False, num_workers=4)return train_iter, test_iterbatch_size = 128
train_iter, test_iter = load_data_fashion_mnist(batch_size, resize = 224)
5.6.4 訓練
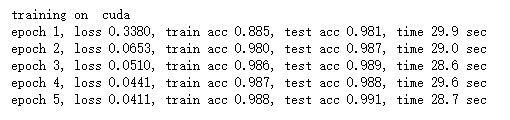
lr, num_epochs = 0.001, 5
optimizer = optim.Adam(net.parameters(), lr =lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)


 UVA - 519)
![[pytorch、學習] - 5.7 使用重復元素的網絡(VGG)](http://pic.xiahunao.cn/[pytorch、學習] - 5.7 使用重復元素的網絡(VGG))



![[pytorch、學習] - 5.8 網絡中的網絡(NiN)](http://pic.xiahunao.cn/[pytorch、學習] - 5.8 網絡中的網絡(NiN))



![[pytorch、學習] - 5.9 含并行連結的網絡(GoogLeNet)](http://pic.xiahunao.cn/[pytorch、學習] - 5.9 含并行連結的網絡(GoogLeNet))



![[pytorch、學習] - 9.1 圖像增廣](http://pic.xiahunao.cn/[pytorch、學習] - 9.1 圖像增廣)


![[pytorch、學習] - 9.2 微調](http://pic.xiahunao.cn/[pytorch、學習] - 9.2 微調)
