參考
5.7 使用重復元素的網絡(VGG)
AlexNet在LeNet的基礎上增加了3個卷積層。但AlexNet作者對它們的卷積窗口、輸出通道數和構造順序均做了大量的調整。雖然AlexNet指明了深度卷積神經網絡可以取得出色的結果,但并沒有提供簡單的規則以指導后來的研究者如何設計新的網絡。我們將在本章的后續幾節里介紹幾種不同的深度網絡設計思路。
下面介紹VGG
5.7.1 VGG塊
VGG塊的組成規律是:連續使用數個相同的填充為1、窗口形狀為3×3的卷積層后接上一個步幅為2、窗口形狀為2×2的最大池化層。卷積層保持輸入的高和寬不變,而池化層則對其減半。我們使用vgg_block函數來實現這個基礎的VGG塊,它可以指定卷積層的數量和輸入輸出通道數。
import time
import torch
from torch import nn, optimimport sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')def vgg_block(num_convs, in_channels, out_channels):blk = []for i in range(num_convs):if i == 0:blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))else:blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))blk.append(nn.ReLU())blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 這里會使寬高減半return nn.Sequential(*blk)
5.7.2 VGG網絡
與AlexNet和LeNet一樣,VGG網絡由卷積層模塊后接全連接層模塊構成。卷積層模塊串聯數個vgg_block,其超參數由變量conv_arch定義。該變量指定了每個VGG塊里卷積層個數和輸入輸出通道數。全連接模塊則跟AlexNet中的一樣。
現在我們構造一個VGG網絡。它有5個卷積塊,前2塊使用單卷積層,而后3塊使用雙卷積層。第一塊的輸入輸出通道分別是1和64,之后每次對輸出通道數翻倍,直到變為512。因為這個網絡使用了8個卷積層和3個全連接層,所以經常被稱為VGG-11。
conv_arch = ((1, 1, 64), (1, 64, 128), (2, 128, 256), (2, 256, 512), (2, 512, 512))
# 經過5個 vgg_block, 寬高會減半5次, 變成 224/32 = 7
fc_features = 512 * 7 * 7
fc_hidden_units = 4096 # 任意
下面實現VGG-11
def vgg(conv_arch, fc_features, fc_hidden_units=4096):net = nn.Sequential()# 卷積層部分# conv_arch: ((1,1,64),(1,64,128),(2,128,256),(2,256,512),(2,512,512))for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):# 每經過一個vgg_block都會使寬高減半"""(1,1,64):- 0: nn.Conv2d(1, 64, kernel_size=3, padding=1) # (1, 1, 224, 224) -> (1, 64, 224, 224)nn.MaxPool2d(kernel_size=2, stride=2) # (1, 64, 224, 224) -> (1, 64, 112, 112)(1,64,128):- 0: nn.Conv2d(64, 128, kernel_size=3, padding=1) # (1, 64, 112, 112) -> (1, 128, 112, 112)nn.MaxPool2d(kernel_size=2, stride=2) # (1, 128, 112, 112) -> (1, 128, 56, 56)(2,128,256):- 0: nn.Conv2d(128, 256, kernel_size=3, padding=1) # (1, 128, 56, 56) -> (1, 256, 56, 56)- 1: nn.Conv2d(256, 256, kernel_size=3, padding=1)nn.MaxPool2d(kernel_size=2, stride=2) # (1, 256, 56, 56) -> (1, 256, 28, 28)(2,256,512):- 0: nn.Conv2d(256, 512, kernel_size=3, padding=1) # (1, 256, 28, 28) -> (1, 512, 28, 28)- 1: nn.Conv2d(512, 512, kernel_size=3, padding=1)nn.MaxPool2d(kernel_size=2, stride=2) # (1, 512, 28, 28) -> (1, 512, 14, 14)(2,512,512):- 0: nn.Conv2d(512, 512, kernel_size=3, padding=1)- 1: nn.Conv2d(512, 512, kernel_size=3, padding=1)nn.MaxPool2d(kernel_size=2, stride=2) # (1, 512, 14, 14) -> (1, 512, 7, 7)"""net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))# 全連接層部分net.add_module("fc", nn.Sequential(d2l.FlattenLayer(),nn.Linear(fc_features, fc_hidden_units),nn.ReLU(),nn.Dropout(0.5),nn.Linear(fc_hidden_units, fc_hidden_units),nn.ReLU(),nn.Dropout(0.5),nn.Linear(fc_hidden_units, 10)))return net
net = vgg(conv_arch, fc_features, fc_hidden_units)
print(net)# X = torch.rand(1, 1, 224, 224)# for name, blk in net.named_children():
# X = blk(X)
# print(name, "output shape: ", X.shape)

5.7.3 獲取數據和訓練模型
ratio = 8
small_conv_arch = [(1, 1, 64//ratio), (1, 64//ratio, 128//ratio), (2, 128//ratio, 256//ratio), (2, 256//ratio, 512//ratio), (2, 512//ratio, 512//ratio)]
net = vgg(small_conv_arch, fc_features // ratio, fc_hidden_units // ratio)print(net)

batch_size = 64
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
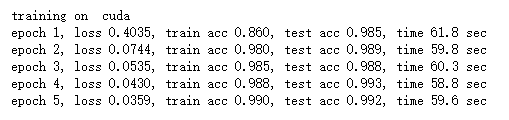
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)



![[pytorch、學習] - 5.8 網絡中的網絡(NiN)](http://pic.xiahunao.cn/[pytorch、學習] - 5.8 網絡中的網絡(NiN))



![[pytorch、學習] - 5.9 含并行連結的網絡(GoogLeNet)](http://pic.xiahunao.cn/[pytorch、學習] - 5.9 含并行連結的網絡(GoogLeNet))



![[pytorch、學習] - 9.1 圖像增廣](http://pic.xiahunao.cn/[pytorch、學習] - 9.1 圖像增廣)


![[pytorch、學習] - 9.2 微調](http://pic.xiahunao.cn/[pytorch、學習] - 9.2 微調)

)


![[github] - git使用小結(分支拉取、版本回退)](http://pic.xiahunao.cn/[github] - git使用小結(分支拉取、版本回退))