參考
9.1 圖像增廣
在5.6節(深度卷積神經網絡)里我們提過,大規模數據集是成功應用神經網絡的前提。圖像增廣(image augmentation)技術通過對訓練圖像做一系列隨機改變,來產生相似但又不相同的訓練樣本,從而擴大訓練數據集的規模。圖像增廣的另一種解釋是,隨機改變訓練樣本可以降低模型對某些屬性的依賴,從而提高模型的泛化能力。
import time
import torch
from torch import nn, optim
from torch.utils.data import Dataset, DataLoader
import torchvision
from PIL import Imageimport sys
sys.path.append("..")
import d2lzh_pytorch as d2ldevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
9.1.1 常用的圖像增廣方法
d2l.set_figsize()
img = Image.open('../img/cat2.jpg')
d2l.plt.imshow(img)

下面定義繪圖函數show_images
# 傳入圖片, 行、列 和規模
def show_images(imgs, num_rows, num_cols, scale=2):figsize = (num_cols * scale, num_rows * scale)_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)for i in range(num_rows):for j in range(num_cols):axes[i][j].imshow(imgs[i * num_cols + j])axes[i][j].axes.get_xaxis().set_visible(False)axes[i][j].axes.get_yaxis().set_visible(False)return axes
大部分圖像增廣都有一定的隨機性。為了方便觀察圖像增廣效果,接下來我們定義一個輔助函數apply。這個函數對輸入圖像img多次運行圖像增廣方法aug并展示所有的結果。
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):Y = [aug(img) for _ in range(num_rows * num_cols)]show_images(Y, num_rows, num_cols, scale)
9.1.1.1 翻轉和裁剪
左右翻轉圖像通常不改變物體的類別。它是最早也是最廣泛使用的一種圖像增廣方法。下面我們通過torchvision.transforms模塊創建RandomHorizontalFlip實例來實現一半概率的圖像水平(左右)翻轉。
apply(img, torchvision.transforms.RandomHorizontalFlip(),num_rows= 2, scale=3)

上下翻轉不如左右翻轉通用。但是至少對于樣例圖像,上下翻轉不會造成識別障礙。下面我們創建RandomVerticalFllip實例來實現一半概率的圖像垂直(上下翻轉)
apply(img, torchvision.transforms.RandomVerticalFlip(), scale=2.7)

在我們使用的樣例圖像里,貓在圖像正中間,但一般情況下可能不是這樣。在5.4節(池化層)里我們解釋了池化層能降低卷積層對目標位置的敏感度。除此之外,我們還可以通過對圖像隨機裁剪來讓物體以不同的比例出現在圖像的不同位置,這樣能夠降低模型對目標位置的敏感性。
在下面的代碼里,我們每次隨機裁剪出一塊面積為原面積10% ~ 100%的區域,且該區域的寬高和高之比隨機取自 0.5 ~ 2, 然后再將該區域的寬和高分別縮放到200像素。若無特殊說明, 本節中 a 和 b之間的隨機數指的是從區間[a,b]中隨機均勻采樣所得的連續值.
shape_aug = torchvision.transforms.RandomResizedCrop(200, scale=(0.1, 1), ratio = (0.5, 2))
apply(img, shape_aug, scale =3)

9.1.1.2 變化顏色
另一類增廣方法是變化顏色。我們可以從4個方面改變圖像的顏色: 亮度(brightness)、對比度(contrast)、飽和度(saturation)和色調(hue)。再下面的例子里,我們將圖像的亮度隨機變化為原亮度的50% (1 - 0.5) ~ 150% (1 + 0.5)
apply(img, torchvision.transforms.ColorJitter(brightness = 0.5), scale = 2.5)

我們也可以隨機色調
apply(img, torchvision.transforms.ColorJitter(hue = 0.5), scale = 3)

類似地,我們也可以隨機變化圖像的對比度。
apply(img, torchvision.transforms.ColorJitter(contrast = 0.5), scale = 3)

我們也可以同時設置如何隨機變化圖像的亮度(brightness)、對比度(contrast)、飽和度(saturation)和色調(hue)。
color_aug = torchvision.transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue = 0.5
)apply(img, color_aug, num_cols=3, num_rows=2, scale =2.7)

9.1.1.3 疊加多個圖像增廣方法
實際應用中我們將會將多個圖像增廣方法疊加使用。我們可以通過Compose實例將上面定義的多個圖像增廣方法疊加起來,再應用到每張圖像上mm
augs = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(), color_aug, shape_aug
])apply(img, augs)

9.1.2 使用圖像增廣訓練模型
下面我們來看一個將圖像增廣應用在實際訓練中的例子。這里我們使用CIFAR-10數據集,而不是之前我們一直使用的Fashion-MNIST數據集。這是因為Fashion-MNIST數據集中物體的位置和尺寸都已經經過歸一化處理,而CIFAR-10數據集中物體的顏色和大小更加顯著。下面展示了CIFAR-10數據集中前32張訓練圖像。
all_images = torchvision.datasets.CIFAR10(train= True, root="~/Datasets/CIFAR", download=True)
# all_images的每一個元素都是(image, label)
注: 此處根據下載的位置,用迅雷下載會比較快
show_images([all_images[i][0] for i in range(8)], 2, 4, scale=3)

為了在預測時得到確定的結果,我們通常只將圖像增廣應用在訓練樣本上,而不在預測時使用含隨機操作的圖像增廣。在這里我們只使用最簡單的隨機左右翻轉。此外,我們使用ToTensor將小批量圖像轉成PyTorch需要的格式,即形狀為(batch_size, channels, height, width)、值域在0~1之間且類型為32位浮點數
flip_aug = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor()
])no_aug = torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])
接下來,我們定義一個輔助函數來方便讀取圖像并應用圖像增廣.
num_workers = 0 if sys.platform.startswith('win32') else 4def load_cifar10(is_train, augs, batch_size, root = "~/Datasets/CIFAR"):datasets = torchvision.datasets.CIFAR10(root=root, train=is_train, transform=augs, download =True)return DataLoader(datasets, batch_size=batch_size, shuffle=is_train, num_workers=num_workers)
使用圖像增廣訓練模型
# 定義train函數使用GPU訓練并評價模型def train(train_iter, test_iter, net, loss, optimizer, device, num_epochs):net = net.to(device)print("training on", device)batch_count =0for epoch in range(num_epochs):train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()for X, y in train_iter:X = X.to(device)y = y.to(device)y_hat = net(X)l = loss(y_hat, y)optimizer.zero_grad()l.backward()optimizer.step()train_l_sum += l.cpu().item()train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()n += y.shape[0]batch_count += 1test_acc = d2l.evaluate_accuracy(test_iter, net)print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
然后可以定義train_with_data_aug函數使用圖像增廣來訓練模型了。該函數使用Adam算法作為訓練使用的優化算法,然后將圖像增廣應用于訓練數據集之上,最好調用剛才定義的train函數訓練并評價模型。
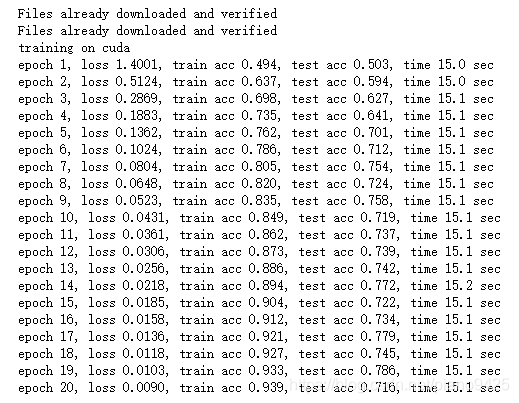
def train_with_data_aug(train_augs, test_augs, lr = 0.001):batch_size, net = 256, d2l.resnet18(10)optimizer = torch.optim.Adam(net.parameters(), lr=lr)loss = torch.nn.CrossEntropyLoss()train_iter = load_cifar10(True, train_augs, batch_size)test_iter = load_cifar10(False, test_augs, batch_size)train(train_iter, test_iter, net, loss, optimizer, device, num_epochs=20)
下面使用隨機左右翻轉的圖像增廣來訓練模型
train_with_data_aug(flip_aug, no_aug)


![[pytorch、學習] - 9.2 微調](http://pic.xiahunao.cn/[pytorch、學習] - 9.2 微調)

)


![[github] - git使用小結(分支拉取、版本回退)](http://pic.xiahunao.cn/[github] - git使用小結(分支拉取、版本回退))






![[C++] 轉義序列](http://pic.xiahunao.cn/[C++] 轉義序列)
)



![[Head First Java] - 簡單的建議程序](http://pic.xiahunao.cn/[Head First Java] - 簡單的建議程序)