參考
5.9 含并行連結的網絡(GoogLeNet)
在2014年的ImageNet圖像識別挑戰賽中,一個名叫GoogLeNet的網絡結構大放異彩。它雖然在名字上向LeNet致敬,但在網絡結構上已經很難看到LeNet的影子。GoogLeNet吸收了NiN中網絡串聯網絡的思想,并在此基礎上做了很大改進。在隨后的幾年里,研究人員對GoogLeNet進行了數次改進,本節將介紹這個模型系列的第一個版本。
5.9.1 Inception塊
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-fn8Tzn2Z-1594258539068)(attachment:image.png)]](https://img-blog.csdnimg.cn/20200709093558846.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3BpYW5vOTQyNQ==,size_16,color_FFFFFF,t_70)
Inception塊中可以自定義的超參數是每個層的輸出通道,我們以此來控制模型的復雜度
import time
import torch
from torch import nn, optim
import torch.nn.functional as Fimport sys
sys.path.append("..")
import d2lzh_pytorch as d2ldevice = torch.device("cuda" if torch.cuda.is_available() else 'cpu')class Inception(nn.Module):def __init__(self, in_c, c1, c2, c3, c4):super(Inception, self).__init__()# 路線1: 單 1 x 1 卷積層self.p1_1 = nn.Conv2d(in_c, c1, kernel_size =1)# 路線2: 1 x 1 卷積層后接3 x 3卷積層self.p2_1 = nn.Conv2d(in_c, c2[0], kernel_size = 1)self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size = 3, padding = 1)# 路線3: 1 x 1卷積層后接5 x 5卷積層self.p3_1 = nn.Conv2d(in_c, c3[0], kernel_size = 1)self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size = 5, padding = 2)# 路線4: 3 x 3 最大池化層后接1 x 1卷積層self.p4_1 = nn.MaxPool2d(kernel_size = 3, stride = 1, padding = 1)self.p4_2 = nn.Conv2d(in_c, c4, kernel_size = 1)def forward(self, x):p1 = F.relu(self.p1_1(x))p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))p4 = F.relu(self.p4_2(self.p4_1(x)))return torch.cat((p1, p2, p3, p4), dim = 1) # 在通道維上連結輸出5.9.2 GoogLeNet模型
GoogLeNet跟VGG一樣,在主體卷積部分中使用5個模塊(block),每個模塊之間使用步幅為2的3x3最大池化層來減少輸出寬高。第一模塊使用一個64通道的7x7卷積層。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size =7, stride =2, padding =3),nn.ReLU(),nn.MaxPool2d(kernel_size = 3, stride = 2, padding = 1)
)
第二模塊使用2個卷積層: 首先通過64通道的 1x1 卷積層,然后是將通道增大3倍的 3x3 卷積層。它對應Inception塊中的第二條線路。
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size = 1),nn.Conv2d(64, 192, kernel_size = 3, padding =1),nn.MaxPool2d(kernel_size = 3, stride = 2, padding = 1)
)
第三模塊串聯2個完整的Inception塊。第一個Inception塊的輸出通道數為 64 + 128 + 32 + 32 = 256,其中4條路線的輸出通道數比例為 64: 128 : 32: 32 = 2: 4: 1: 1。其中第二、第三條路線先分別將輸入通道數減少至96/192 = 1/2 和 16/192 = 1/ 12后,再接上第二層卷積層。第二個Inception塊輸出通道數增至 128 +192 +96 + 64 = 480,每條線路的輸出通道數之比為 128: 192: 96: 64 = 4: 6 : 3 : 2。其中第二、第三條路線先分別將輸入通道數減少至 128/ 256 = 1/2 和 32/ 256 = 1/8。
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),Inception(256, 128, (128, 192),(32, 96), 64),nn.MaxPool2d(kernel_size = 3, stride =2, padding =1)
)
第四模塊更加復雜。它串聯了5個Inception塊,其輸出通道數分別是192 + 208 + 48 + 64 = 512、160 + 224 + 64 + 64 = 512、128 + 256 + 64 + 64 = 512、 112 + 288 + 64 + 64 = 528 和 256 + 320 + 128 + 128 = 832。這些線路的通道數分配和第三模塊中類似,首先含3x3卷積層的第二條線路輸出最多通道,其次是僅含1x1卷積層的第一條線路,之后是含5x5卷積層的第3條線路和含3x3最大池化層的第4條線路。其中第二、第三條線路都會按比例減小通道數。這些比例在各個Inception塊中都略有不同。
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),Inception(512, 160, (112, 224), (24, 64), 64),Inception(512, 128, (128, 256), (24, 64), 64),Inception(512, 112, (144, 288), (32, 64), 64),Inception(528, 256, (160, 320), (32, 128), 128),nn.MaxPool2d(kernel_size = 3, stride=2, padding =1)
)
第五模塊有輸出通道數為 256 + 320 + 128 + 128 = 832 和 834 + 384 + 128 + 128 = 1024的兩個Inception塊。其中每條線路的通道數的分配思路和第三、第四模塊中的一致,只是在具體數值上有所不同。需要注意的是,第五模塊的后面緊跟輸出層,該模塊同NiN一樣使用全局平均池化層來將每個通道的寬和高變成1。最后我們將輸出變成二維數組后接上一個輸出個數為標簽類別數的全連接層。
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),Inception(832, 384, (192, 384), (48, 128), 128),d2l.GlobalAvgPool2d()
)net = nn.Sequential(b1, b2, b3, b4, b5, d2l.FlattenLayer(), nn.Linear(1024, 10))print(net)



將輸入的高和寬從224降到96來簡化計算,下面演示各個模塊之間的輸出的形狀變化
net = nn.Sequential(b1, b2, b3, b4, b5, d2l.FlattenLayer(), nn.Linear(1024, 10))
X = torch.rand(1, 1, 96, 96)
for blk in net.children():X = blk(X)print("output shape: ", X.shape)

5.9.3 獲取數據和訓練模型
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr = lr)
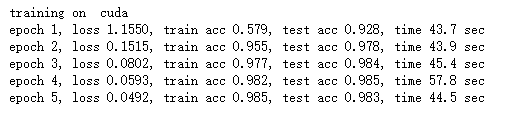
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)



![[pytorch、學習] - 9.1 圖像增廣](http://pic.xiahunao.cn/[pytorch、學習] - 9.1 圖像增廣)


![[pytorch、學習] - 9.2 微調](http://pic.xiahunao.cn/[pytorch、學習] - 9.2 微調)

)


![[github] - git使用小結(分支拉取、版本回退)](http://pic.xiahunao.cn/[github] - git使用小結(分支拉取、版本回退))






![[C++] 轉義序列](http://pic.xiahunao.cn/[C++] 轉義序列)
)