前置知識
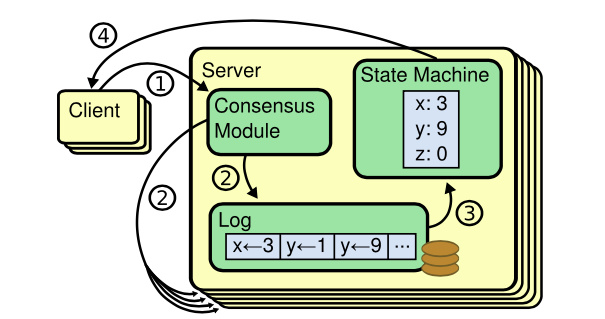
什么是一致性算法?
- 安全性保證,絕對不會返回一個錯誤的結果;
- 可用性,容忍集群部分節點失敗;
- 不依賴時序來保證一致性;
- 一條指令可以盡可能快的在集群中大多數節點響應一輪遠程過程調用時完成。小部分比較慢的節點不會影響系統整體的性能;
Raft
總結:

服務器狀態轉移:
跟隨者只響應來自其他服務器的請求。如果跟隨者接收不到消息,那么他就會變成候選人并發起一次選舉。獲得集群中大多數選票的候選人將成為領導人。在一個任期內,領導人一直都會是領導人,直到自己宕機了。
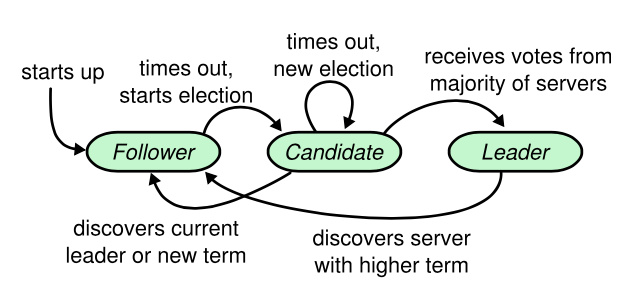
避免腦裂:奇數個服務器,在任何時候為了完成任何操作,必須湊夠過半的服務器來批準相應的操作。
例如,當一個Raft Leader競選成功,那么這個Leader必然湊夠了過半服務器的選票,而這組過半服務器中,必然與舊Leader的過半服務器有重疊。所以,新的Leader必然知道舊Leader使用的任期號(term number),因為新Leader的過半服務器必然與舊Leader的過半服務器有重疊,而舊Leader的過半服務器中的每一個必然都知道舊Leader的任期號。類似的,任何舊Leader提交的操作,必然存在于過半的Raft服務器中,而任何新Leader的過半服務器中,必然有至少一個服務器包含了舊Leader的所有操作。這是Raft能正確運行的一個重要因素。
應用程序代碼和 Raft 庫:應用程序代碼接收 RPC 或者其他客戶端請求;不同節點的 Raft 庫之間相互合作,來維護多副本之間的操作同步。
Log 是 Leader 用來對操作排序的一種手段。Log 與其他很多事物,共同構成了 Leader 對接收到的客戶端操作分配順序的機制。還有就是能夠向丟失了相應操作的副本重傳,也需要存儲在 Leader 的 Log 中。而對于 Follower 來說,Log 是用來存放臨時操作的地方。Follower 收到了這些臨時的操作,但是還不確定這些操作是否被 commit 了,這些操作可能會被丟棄。對所有節點而言,Log 幫助重啟的服務器恢復狀態
避免分割選票:為選舉定時器隨機地選擇超時時間。
broadcastTime ? electionTimeout ? MTBF(mean time between failures)
RAFT 與應用程序交互:
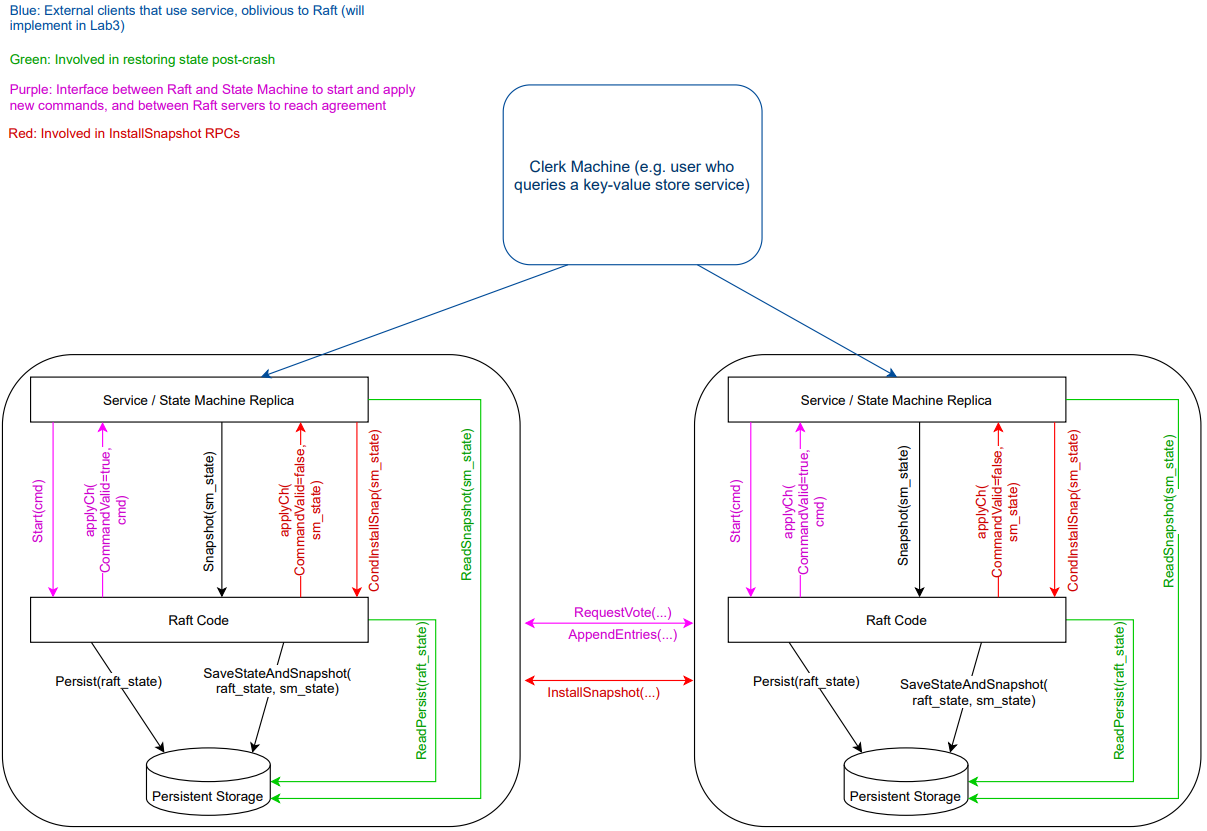
實驗內容
實現 RAFT,分為四個 part:leader election、log、persistence、log compaction。
實驗環境
OS:WSL-Ubuntu-18.04
golang:go1.17.6 linux/amd64
踩過的坑
- 死鎖:if語句提前return,未釋放鎖;
- 發rpc前后都要check狀態是否已經改變;
- 開啟進程過多,導致程序運行緩慢,leader election時間延長,從而導致多次選舉;這也就是為什么論文要求broadcastTime ? electionTimeout ? MTBF;這種情況主要每幾千次測試發生一次;
- 多次測試!最好測試1w次;
- 代碼后續更新在:https://github.com/BeGifted/MIT6.5840-2023
Part 2A: leader election
這部分主要實現選出一位領導人,如果沒有失敗,該領導人將繼續擔任領導人;如果舊領導人 fail 或往來于舊領導人的 rpc 丟失,則由新領導人接任。同時實現心跳定時發送。
raft、rpc格式
后續lab會增加內容。
type Raft struct {mu sync.Mutex // Lock to protect shared access to this peer's statepeers []*labrpc.ClientEnd // RPC end points of all peerspersister *Persister // Object to hold this peer's persisted stateme int // this peer's index into peers[]dead int32 // set by Kill()// Your data here (2A, 2B, 2C).// Look at the paper's Figure 2 for a description of what// state a Raft server must maintain.state int // follower\candidate\leadercurrentTerm int // last term server has seenvotedFor int // candidateId that received votelog []Entry // log entriescommitIndex int // index of highest entry committedlastApplied int // index of highest entry applied to state machinenextIndex []intmatchIndex []inttimeout time.DurationexpiryTime time.Time
}type RequestVoteArgs struct {// Your data here (2A, 2B).Term int //candidate termCandidateId intLastLogIndex intLastLogTerm int
}type RequestVoteReply struct {// Your data here (2A).Term int // currentTermVoteGranted bool
}type AppendEntriesArgs struct {Term int //leader termLeaderId intPrevLogIndex intPrevLogTerm intEntries []EntryLeaderCommit int // leader commitIndex
}type AppendEntriesReply struct {Term int // currentTermSuccess bool
}
RequestVote
- follower 一段時間未收到心跳發送 RequestVote,轉為 candidate;
- candidate 一段時間未收到贊成票發送 RequestVote,維持 candidate;
- 接收 RequestVote 的 server:
- T < currentTerm:reply false;
- T >= currentTerm && votedFor is nil or candidateId && 日志較舊:reply true;轉為 follower;
- else:reply false;
- RequestVoteReply:看返回的 term 如果比 currentTerm 大,轉為 follower;否則計算投票數。
AppendEntries
- 心跳,不帶 entries,維持 leader;
- 日志復制,在 last log index ≥ nextIndex[i] 時觸發;
- 接收 AppendEntries 的server:
- term < currentTerm || prevLogIndex 上 entry 的 term 與 prevLogTerm 不匹配:reply false;
- 刪除沖突的 entries,添加 new entries;
- leaderCommit > commitIndex:commitIndex = min(leaderCommit, index of last new entry);
- AppendEntries 返回:
- 成功:更新 nextIndex[i]、matchIndex[i];
- 失敗:減少 nextIndex[i],retry;
ticker
用于當某個 follower 一段時間未收到 AppendEntries 時,開啟競選 leader。
func (rf *Raft) ticker() {for rf.killed() == false {// Your code here (2A)// Check if a leader election should be started.if rf.state != Leader && time.Now().After(rf.expiryTime) {go func() { // leader selectionrf.mu.Lock()rf.state = Candidaterf.votedFor = rf.merf.currentTerm++timeout := time.Duration(250+rand.Intn(300)) * time.Millisecondrf.expiryTime = time.Now().Add(timeout)rf.persist()numGrantVote := 1 // self grantargs := RequestVoteArgs{Term: rf.currentTerm,CandidateId: rf.me,LastLogIndex: len(rf.log) - 1,LastLogTerm: rf.log[len(rf.log)-1].Term,}rf.mu.Unlock()for i := 0; i < len(rf.peers); i++ {if i == rf.me {continue}go func(i int) {reply := RequestVoteReply{}if ok := rf.sendRequestVote(i, &args, &reply); ok {rf.mu.Lock()if rf.state != Candidate || args.Term != reply.Term || args.Term != rf.currentTerm || reply.Term < rf.currentTerm {rf.mu.Unlock()return}if reply.Term > rf.currentTerm {rf.state = Followerrf.currentTerm = reply.Termrf.votedFor = -1rf.persist()} else if reply.VoteGranted {numGrantVote++if numGrantVote > len(rf.peers)/2 {rf.mu.Unlock()rf.toLeader()return}}rf.mu.Unlock()}}(i)}}()}// pause for a random amount of time between 50 and 350// milliseconds.ms := 50 + (rand.Int63() % 30)time.Sleep(time.Duration(ms) * time.Millisecond)}
}
heart beat
func (rf *Raft) heartBeat() {for rf.killed() == false {rf.mu.Lock()if rf.state != Leader {rf.mu.Unlock()return}rf.mu.Unlock()for i := 0; i < len(rf.peers); i++ {if i == rf.me {continue}go func(i int) {rf.mu.Lock()if rf.state != Leader {rf.mu.Unlock()return}log.Println(i, "rf.nextIndex[i]", rf.nextIndex[i], "len", len(rf.log))args := AppendEntriesArgs{Term: rf.currentTerm,LeaderId: rf.me,PrevLogIndex: rf.nextIndex[i] - 1,PrevLogTerm: rf.log[rf.nextIndex[i]-1].Term,Entries: []Entry{},LeaderCommit: rf.commitIndex,}reply := AppendEntriesReply{}rf.mu.Unlock()var o boolif ok := rf.sendAppendEntries(i, &args, &reply); ok {rf.mu.Lock()o = okif rf.state != Leader || args.Term != reply.Term || args.Term != rf.currentTerm || reply.Term < rf.currentTerm {rf.mu.Unlock()return}if reply.Term > rf.currentTerm {rf.state = Followerrf.currentTerm = reply.Termrf.votedFor = -1rf.persist()rf.mu.Unlock()return}if reply.Success {rf.nextIndex[i] = args.PrevLogIndex + len(args.Entries) + 1rf.matchIndex[i] = args.PrevLogIndex + len(args.Entries)} else {rf.nextIndex[i] = args.PrevLogIndex}rf.mu.Unlock()}log.Println(rf.me, "send AppendEntries to", i, o, ": currentTerm=", rf.currentTerm, "reply.Term=", reply.Term, "reply.Success", reply.Success)}(i)}time.Sleep(time.Duration(50) * time.Millisecond)}
}
實驗結果
測試10000次:

)





)


)

)


-------連載(45))




