
大家好,我是極智視界,歡迎關注我的公眾號,獲取我的更多前沿科技分享
邀您加入我的知識星球「極智視界」,星球內有超多好玩的項目實戰源碼和資源下載,鏈接:https://t.zsxq.com/0aiNxERDq
12 月 1 日阿里開源了 72B 和 18B 大模型以及音頻大模型 Qwen-Audio,再加上之前八月份、九月份開源的 7B 和 14B 大模型,號稱是 "全尺寸開源"。我也去 Github 上瞅了一眼,通義應該確實是 "兜庫底" 了,所有規格的模型都開源了。
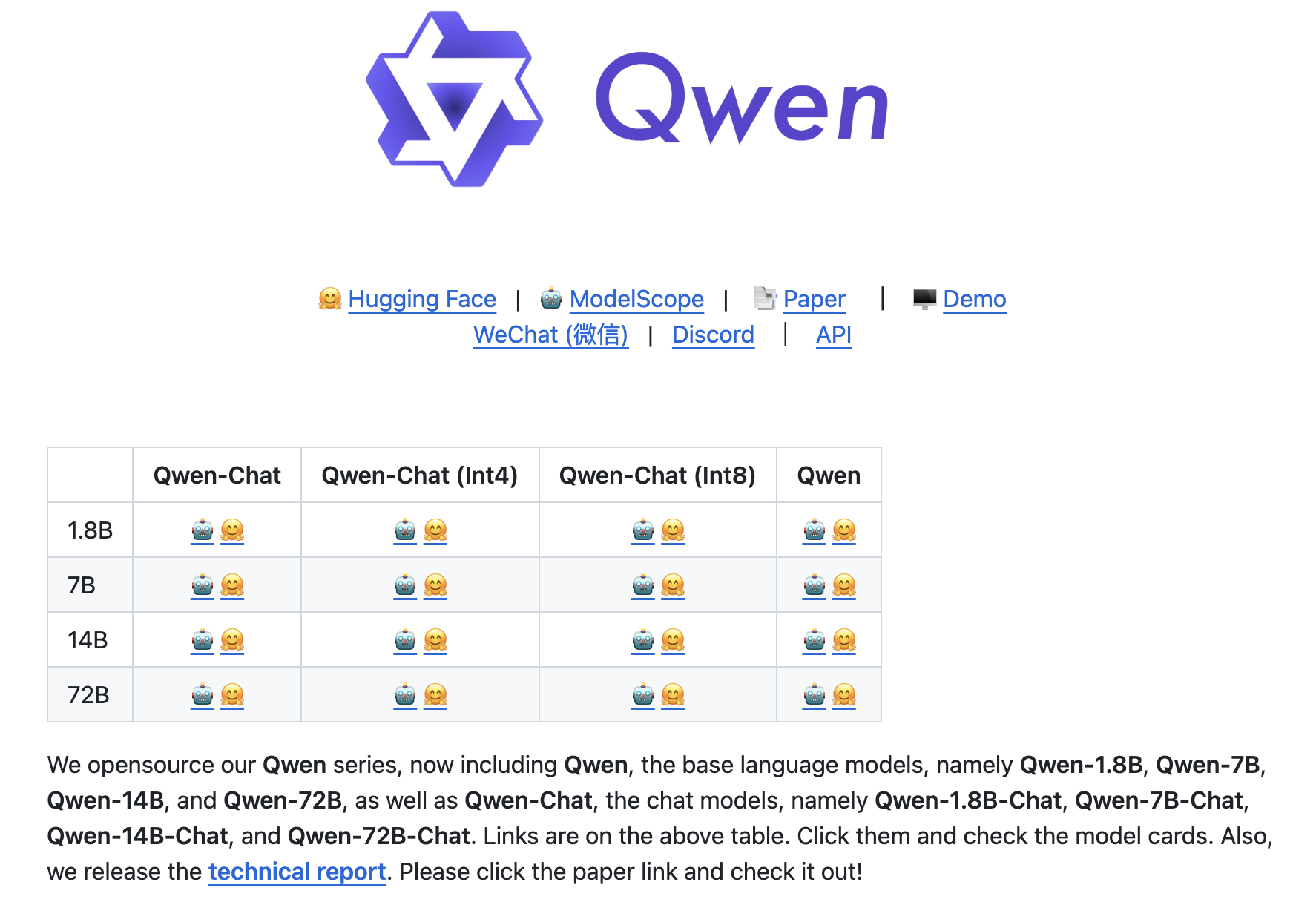
對于這個事情,我的第一反應是:難得啊,對于阿里這種技術相對封閉的公司來說。但是仔細想想,目前對于大模型來說,開不開源真的很重要嗎?其實是需要打個問號的,除非你 OpenAI 的 GPT-4 開源,不然業界應該很難激起過多的浪花,因為大家都見多不怪了。現在對于大模型真正卡脖子地方是在 "算力" 和 "數據" 上,而不在 "算法" 上。以前是這三駕馬車都很重要,然后算法可能會更加重要一些。但是現在大模型時代則不太一樣,特別是在美國芯片禁令的情況下,主要矛盾已經明顯傾向于對于算力的需求上。現在國內很多大模型從算法實現角度,都可以用 "套殼" LLaMA 來達到 "自研大模型" 商業化的目的,這個時候你通義開不開源其實并不太重要。而說到 "套殼",就又是另外一個有意思的話題了,這里不過多展開。

現在主要矛盾點在于我要有足夠的算力、足夠高質量的數據來進行微調,甚至是從頭訓練。對于很多大模型廠商來說,區別只是在我選 LLaMA 來微調還是選通義大模型來微調,而相信大多還是會選 LLaMA。這其實可以類比到手機領域,安卓大家都可以用,很多時候有安卓就夠了,你鴻蒙開源對于小米、對于 vivo 的操作系統研發意義大嗎,我小米會把自己手機操作系統切到基于鴻蒙的嗎 (可能確實有參考意義,比如對于小米澎湃 OS 的研發,但是對于大多數廠商來說還是用安卓就夠夠的了),大家更加在意的是能夠擁有性能更加好的芯片、算力更加好的處理器,比如前段時間經常上熱搜的全大核天璣 9300,這才是核心競爭力。

雖然 (是反轉沒錯了),在大家有 LLaMA 可選的情況下,通義的開源意義確實不大。但是開源總能贏得好名聲,這點毋庸置疑,何況通義開源了自己全規格的模型,其開源的 70B 大模型也是目前開源大模型中最大規模的,可以說 "誠意滿滿",對于博一個好名聲應該是不難的,這是 "名"。
然后咱們來說說 "利",通義大模型是開源了,大家要用、要微調得要有算力吧,算力哪里來,答案就是阿里云,你品,你細品。來,繼續分析,阿里還有個號稱國產 HaggingFace 的魔塔 ModelScope,要用開源的通義你就得上魔塔,而魔塔部署在哪里呢,魔塔的算力來源于哪里呢,答案依舊是阿里云,你品,你細品。阿里的這招太 "精明" 了,真的是既想要名也想要利啊。
從這個角度來說,其實在 12 月 1 日阿里宣布全量開源通義前問大模型的時候,阿里已經徹底換賽道了,已經是不想跟大家玩大模型了,已經不再是 "百模大戰" 中的一員了。未來,"百模大戰" 肯定會繼續,而阿里更加聰明,燒錢去做大模型,效果嘛打不過 GPT-4,落地商業化嘛又難,競爭對手又像瘋了一樣的涌進來,換個賽道,躺著掙錢它不香嘛。這大概率也是在學英偉達、特別是在學 AWS。提供付費算力,這才是大模型時代正確的掙錢的方式啊,這些才是大模型時代掙麻了的企業啊。繼續給阿里支招,繼續開源數據集,讓大家在阿里云上訓練(燒錢)徹底沒有技術上的障礙,而變成一個愿不愿意花錢的問題。

阿里云,是懂計算的。計算無法計算的價值,數錢數到手抽筋。

【極智視界】
《解讀 | 阿里通義千問模型全尺寸開源 "誠意滿滿"背后的名與利》


)






![[筆記]ARMv7/ARMv8 交叉編譯器下載](http://pic.xiahunao.cn/[筆記]ARMv7/ARMv8 交叉編譯器下載)








![[Kadane算法,前綴和思想]元素和最大的子矩陣](http://pic.xiahunao.cn/[Kadane算法,前綴和思想]元素和最大的子矩陣)
