2023年初是人工智能爆發的里程碑式的重要階段,以OpenAI研發的GPT為代表的大模型大行其道,NLP領域的ChatGPT模型火爆一時,引發了全民熱議。而最新更新的GPT-4更是實現了大型多模態模型的飛躍式提升,它能夠同時接受圖像和文本的輸入,并輸出正確的文本回復。很多從事人工智能的同行一方面驚嘆于GPT-4的優秀表現,另一方面也為自己的職業生涯隱隱擔憂。如果說“大算力+強算法”的大模型是人工智能未來發展的趨勢,那么傳統的機器學習算法在真實的業務場景中還有用嗎?會不會早晚被大模型取代?我認為不會。每個業務場景都有其獨特性,優秀的算法工程師最難能可貴的地方在于對業務知識的透徹理解和長期沉淀。而業務知識就如同機器學習項目這棵大樹的根,理論知識如同大樹的多個枝干,算法應用如同枝干上的葉,只有根扎得夠深,這棵大樹才能夠開枝散葉、開花結果。到目前為止,大模型對于瞬息萬變、復雜多樣的業務形態的理解、思考還達不到人類算法工程師的水平,即使有朝一日能夠在大模型的基礎上研發出各種不同業務場景的算法應用,也依然需要算法工程師具備強悍的業務能力和扎實的機器學習理論知識,來引導大模型對特定的業務場景進行有效學習。
身處人工智能爆發式增長時代的機器學習從業者無疑是幸運的,人工智能如何更好地融入人類生活的方方面面是這個時代要解決的重要問題。滴滴國際化資深算法工程師王聰穎老師發現,很多新人在入行伊始,往往把高大上的模型理論背得滾瓜爛熟,而在真正應用時卻摸不清門路、抓不住重點,導致好鋼沒用到刀刃上,無法取得實際的業務收益。如果能有一本指導新人從入門到精通、從理論到實踐的技術書籍,那該多好,這樣不僅省去了企業培養新人的成本,也留給了新人自我學習成長的空間。
本著這個初心,王老師花了將近一年的業余時間來復盤總結了自己以及身邊同事從小白成長為獨當一面的合格算法工程師的成長歷程和項目經驗,最終以理論結合實踐的方式寫入《機器學習高級實踐:計算廣告、供需預測、智能營銷、動態定價》這本書中,希望能通過他的經驗,真正地幫助到對機器學習算法感興趣的讀者。

在本文中,我們截取書中的部分內容,將大家比較關注的機器學習領域新興分支,因果推斷進行簡要的介紹。
圖書的京東鏈接在這里:https://item.jd.com/14256304.html 點我購買直達
因果推斷
因果推斷是近年來機器學習領域新興的一個分支,它主要解決“先有雞還是先有蛋”的問題。因此,因果推斷和關聯關系最主要的區別是:因果推斷是試圖通過變量X的變化推斷其對結果Y帶來的影響有多少,而關聯關系則側重于表達變量之間的趨勢變化,如兩個變量圖片之間有相關性關系,如果圖片隨著圖片的遞增而遞增,則說明圖片和圖片正相關,如果圖片隨著圖片遞增而下降,則說明兩者負相關。因此因果性(Causality)和相關性(Correlation)有著本質的不同,為了幫助讀者更好地理解,這里舉個例子:
某研究表明,吃早飯的人比不吃早飯的人體重更輕,因此“專家”得出結論——吃早飯可以減肥。但事實上,吃早飯和體重輕很有可能只是相關性關系,而并非因果關系。吃早飯的人可能是因為三餐規律、經常鍛煉、睡眠充足等等一系列健康的生活方式,最終導致了他們的體重更輕。圖1所示為因果推斷中的混雜因子,描述了健康的生活方式、吃早飯、體重輕三者的關系。

很顯然,擁有健康的生活方式的人會吃早餐,健康生活方式同時也會導致體重輕,可見健康的生活方式是吃早餐和體重輕的共同原因。正是因為有這樣的共同原因存在,導致我們不能輕易地得出吃早餐和體重輕之間存在因果關系,所以我們認為“專家”的結論是草率的。吃早餐和減肥之間只存在相關性,不存在因果性,并把這種阻斷因果關系推斷的共同原因稱之為混雜因子。那么如圖1右所示,消除混雜因子,尋找兩個變量之間的因果關系,并量化出來某種自變量X的改變,影響了因變量Y的改變程度是因果推斷主要探討的內容。
因果推斷的前世今生
縱觀因果推斷在統計學、機器學習領域的發展史,不得不提及兩位大牛人物,一位是在1978年提出大名鼎鼎的RCM(Rubin Causal Model,等同于潛在因果框架)的Donald Rubin,另一位是在1995年提出Causal Diagram框架的Judea Pearl。2021年10月諾貝爾經濟學獎頒發給了在因果關系分析有突出貢獻的Joshua D.Angrist和Guido W.Imbens,而他們對因果關系的研究就是基于Rubin提出的潛在結果框架,Rubin對因果推斷領域的影響可見一斑。Rubin的另一大貢獻是提出PSM(Propensity Score Matching)框架解決觀測數據存在混雜因子的問題。Pearl提出的Causal Diagram框架則完全脫離了Rubin的RCM框架,使用有向無環圖來可視化的表示變量之間的因果關系,并因為提出Causal Diagram的思想做因果推斷的研究而在2011年獲得圖靈獎。兩位因果推斷領域的大牛人物開創了該領域兩種不同的框架,Pearl在2000年證明過兩種框架是等價的,而Rubin卻不認同他的觀點,Rubin認為潛在結果框架能更清晰的表達因果推斷問題,目前潛在結果框架相較于因果圖而言也是因果推斷領域更常用的分析框架,下面將分別介紹兩種因果推斷框架的分析視角。
1. 潛在結果框架(Potential Outcome Framework)
在介紹潛在結果框架之前,先列出兩個需要聲明的假設來描述個體因果效應,另外需要注意的是為了更快的幫助大家入門,本文只描述二元處理,即個體只有接受處理和不接受處理兩種情況,并對應兩種處理方式的結果。

但是在現實世界中,個體圖片在同一時刻要么接受處理,要么不接受處理,不可能同時既接受處理又不接受處理,因此個體因果作用是不可識別的,個體的觀測數據結果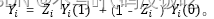
在已知個體因果作用無法識別的情況下,如何進行因果推斷呢?或許把因果作用的識別從個體轉移到了總體身上是個行之有效的解決方案,于是便有了平均因果作用(ATE, Average Treatment Effect)的概念。平均因果作用不再比較個體的因果作用,而是比較兩組群體在不同的處理下的潛在結果,這兩組群體除了接受的處理不同之外,必須具有同質的屬性,這樣計算出的平均因果作用才能無偏,隨機對照實驗(Random controlled Trial,RCT)是保證兩組群里無偏性的基本實驗方法。把全量數據隨機分為實驗組(Treatment Group)和對照組(Control Group),其中實驗組的T=1,對照組的T=0,那么平均因果作用的公式如下:
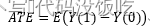
其中Y(1)和Y(0)分別是接受處理情況下實驗組的結果和不接受處理情況下對照組的結果。至此,潛在結果框架下做因果推斷的基本理論知識已經講解完畢,歸納起來主要有以下兩點。
- 隨機對照試驗保證組別的同質性。
- 從不可評估的個體因果作用轉移向評估總體的平均因果效應。
有了隨機對照試驗就萬事大吉了嗎?其實不然,設想這樣一個問題,想要評估抗癌藥物A對于患有癌癥的病人的因果作用,這種情景下還適合做隨機對照實驗嗎?答案顯然是否定的,首先癌癥是重疾,出于人道主義不可能完全隨機出來一個對照組人群對其不進行抗癌藥物干預,其次即使有奉獻主義精神的癌癥患者同意參與隨機對照實驗,在醫療的場景下,實驗周期長、費用昂貴也是隨機對照實驗最大的弊病。通過上面這個實例,我們知道真實生活中并不是所有場景都適合做隨機對照實驗,于是研究者們設法通過對觀測數據進行一系列處理達到隨機對照實驗的效果,其中最有名的就是Rubin提出的傾向分匹配算法(Propensity Score Matching,PSM)。
2.結構因果模型(Structual Causal Model,SCM)
結構因果模型是基于圖結構來描述兩個變量之間的因果關系,因此在介紹SCM之前,先來了解下貝葉斯網絡。貝葉斯網絡是一種基于有向無環圖(Directed Acyclic Graph,DAG)的概率圖模型,其自身并不能表示因果關系,它表達的是變量之間的相關關系,但貝葉斯網絡的有向無環圖是結構因果模型的圖結構基礎,而貝葉斯網絡的概率計算方式也是結構因果模型的推斷基礎。
有向無環圖是由節點和有向邊組成的,有向邊的上游是父節點,有向邊指向的方向是子節點。在DAG中的某個節點的父節點與其非子節點都獨立,根據全概率公式和條件獨立性,一個有向無環圖中的所有節點的聯合概率分布可以表達為:
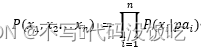
其中圖片是所有指向圖片的父節點,為了更好地幫助讀者理解有向無環圖中的聯合分布表達,這里給出一個具體的DAG實例,如圖2所示。
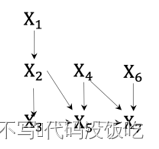
圖2. 有向無環圖實例
根據有向無環圖的條件獨立性和聯合概率分布的公式,圖2的聯合分布可以表達為:
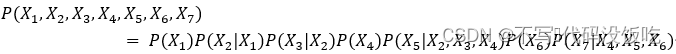
每一個有向無環圖產出了唯一的聯合分布,但是一個聯合分布不一定只對應著一個有向無環圖,比如圖片的聯合概率分布有可能是圖片,也可能是圖結構圖片,而兩種圖結構的因果關系完全相反,這也正是貝葉斯網絡不適合做因果模型的原因。為了把DAG改造成可以表達因果關系的因果圖,需要引入do算子。這里的do算子就表達的是一種干預,圖片表示將指向節點圖片的有向邊全部切除掉,并且節點圖片賦值為常數,在do算子干預后,DAG的聯合概率分布有了變化,表達為如下的形式:
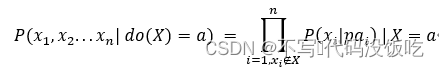
還是以圖2為例,假設do算子對節點圖片進行了干預,那么干預后的DAG的聯合概率分布表達為:
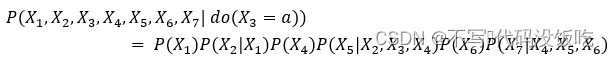
綜上所述,加入了do算子的DAG圖可以表達因果關系,其平均因果作用公式如下:
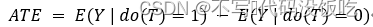
有了do算子的DAG圖就有了因果推斷的靈魂,但是新的問題來了,并不是所有的實際問題都給出顯式的圖結構。大部分的真實情況是,既無法得到圖結構又無法觀測到所有的變量。為了解決上述問題,Pearl提出了后門準則的方法,在介紹后門準則之前,先來看下d-分離的概念。
d-分離的全稱是Directional Separation,它是一種判斷變量之間是否獨立的方法。對于以圖結構為主的因果圖而言,常見的有三種路徑結構如圖3所示:

圖3.因果圖的三種路徑結構
在圖3的鏈式、叉式、反叉式三種路徑結構中,反叉式結構中的A、C天然相互獨立,B又被稱為對撞子,鏈式或者叉式結構,以B為條件可以阻斷A和C之間的關聯關系,從而實現A、C相互獨立。d-分離就是為了達到變量獨立的目的,而對不同的路徑結構采取的阻斷的操作,具體的d-分離法則歸納起來如下。
- 當某條路徑上有兩個箭頭同時指向某個變量時,那這個變量稱之為對撞子,并且這條路徑被對撞子阻斷。
- 如果某條路徑含有非對撞子,那么當以非對撞子為條件時,這條路徑可以被阻斷。
- 當某條路徑以對撞子為條件時,這條路徑不僅不會被阻斷,反而會被打開。
這里需要注意的是,以某個變量為條件指的是指定某個變量的值,比如以年齡這個變量為條件,就是指定年齡為0或者1。
在了解d-分離法則是可以通過以某個變量為條件進行阻斷,從而實現變量間的獨立之后,便可以結合后門準則消除混雜因子對未知結構的因果圖進行因果推斷了。在弄清楚后門準則之前,需要了解后門路徑、前門路徑的概念。從變量X到變量Y的后門路徑就是連接X到Y,但是箭頭不從X出發的路徑,與之相應的前門路徑是連接X到Y且箭頭從X出發的路徑,后門準則的定義是可以通過d-分離阻斷X和Y之間所有的后門路徑,那么我們認為可以識別從X到Y之間的因果關系,并把阻斷后門路徑的因子稱之為混雜因子。至此,知道了后門準則的方法無須觀測到所有的變量,只需要觀測到以哪個變量為條件可以消除后門路徑,從而使得X到Y之間的因果關系可識別。
3.總結
不管是潛在結果框架還是結構因果模型,因果推斷主要是從原因X推斷結果Y的過程,為了保證原因X和結果Y之間沒有混雜因子,一般選擇在數據樣本充足且實驗條件允許的情況下做隨機對照實驗。當條件不允許做隨機對照實驗時,通過對觀察數據進行處理從而達到消除混雜因子對原因X的影響的目的。

除了為廣大開發者量身打造的優質內容,這本書還得到了多位專業人士的認可及推薦。
- 肖仰華 復旦大學計算機科學技術學院教授, 知識工場實驗室負責人
作者結合實際應用場景深入淺出地介紹了機器學習的相關理論與技術。案例翔實、代碼豐富,具有較強的可操作性,對于機器學習的新手以及從業者來說都是一本十分有益的參考書。
- 劉紅巖 清華大學管理科學與工程系教授
翻開這本書,不會覺得在讀教科書,也感覺不到寫代碼帶來的枯燥,像是在身臨其境地與熟悉的老朋友一起解決實際問題, 抽絲剝繭地將復雜化簡呈現,幫助讀者朋友快速搭建知識體系,掌握機器學習技術。
- 傅湘玲 北京郵電大學計算機學院教授,博士生導師
作者結合自己在北郵碩士期間的理論積累和進入互聯網企業工作后的實踐經驗編寫的本書,既有完善的理論體系,又配有互聯網的真實項目案例,是幫助讀者快速成長為優秀算法工程師的技術寶典。
- 陸全 阿里巴巴高級總監
與本書作者相識多年,很佩服他們在工業界機器學習算法落地應用方向做出的貢獻。現在作者將他們多年積累的實踐經驗毫無保留地總結出來,為在機器學習領域里尋求不斷提升的年輕人提供了一份寶貴的參考和指南。
- 秦志偉 Lyft首席科學家
本書從基礎算法理論到業界核心的業務案例,有很好的平衡和覆蓋。即使是有經驗的算法工程師,在細讀本書后也一定會覺得在思路拓展上受益匪淺。它是工程師書架上不可或缺的一本機器學習算法實踐參考書籍。
- 王亮 阿里巴巴資深算法專家
經過幾十年的發展,機器學習技術已經從實驗室里走出來和越來越多的應用場景深度結合,不斷地引領搜/廣/推等領域的發展,我們相信未來機器學習會變成各行各業的一個基礎工具。本書結合機器學習的開發工具和業界機器學習應用案例,讓讀者能夠快速上手實踐,掌握這門技術。
- 夏真 杭州排列科技有限公司 CEO
機器學習技術發展速度很快,很多教材對于行業工作人員來說,稍顯落伍。本書是市面上少有的、把機器學習在幾大行業應用講透徹且案例豐富的參考書。作者用自己強大的理論基礎和多年行業實戰經驗進行的總結,推薦行業人員必備!
- 蒲杰 UBiX CTO
機器學習技術是人工智能的核心,已被廣泛應用于各工業領域。本書始于機器學習基礎理論,終于業界四大核心實戰場景。一方面能夠很好地幫助讀者掌握機器學習在工業界的工作流程,另一方面結合實戰場景有助于提高讀者機器學習實踐能力。誠摯地向想了解或從事機器學習領域的讀者推薦此書。
- 魏維 伊利諾伊大學厄巴納香檳分校副教授
本書理論聯系實踐,系統地介紹了機器學習的背景、模型,以及不同業務場景下的應用實踐。書中案例的設計十分具有啟發性。根據讀者背景的不同,該書既可以作為實務操作的入門手冊,也可以作為進階理論學習的預備材料。



2003-2022年)
)
)






)


)

中使用echarts)


