
論文地址:官方論文地址
代碼地址:官方代碼地址

一、本文介紹?
在這篇文章中,我們將講解如何將LSKAttention大核注意力機制應用于YOLOv8,以實現顯著的性能提升。首先,我們介紹LSKAttention機制的基本原理,它主要通過將深度卷積層的2D卷積核分解為水平和垂直1D卷積核,減少了計算復雜性和內存占用。接著,我們介紹將這一機制整合到YOLOv8的方法,以及它如何幫助提高處理大型數據集和復雜視覺任務的效率和準確性。本文還將提供代碼實現細節和使用方法,展示這種改進對目標檢測、語義分割等方面的積極影響。通過實驗YOLOv8在整合LSKAttention機制后,實現了檢測精度提升(下面會附上改進LSKAttention機制和基礎版本的結果對比圖)。
?專欄回顧:YOLOv8改進系列專欄——本專欄持續復習各種頂會內容——科研必備
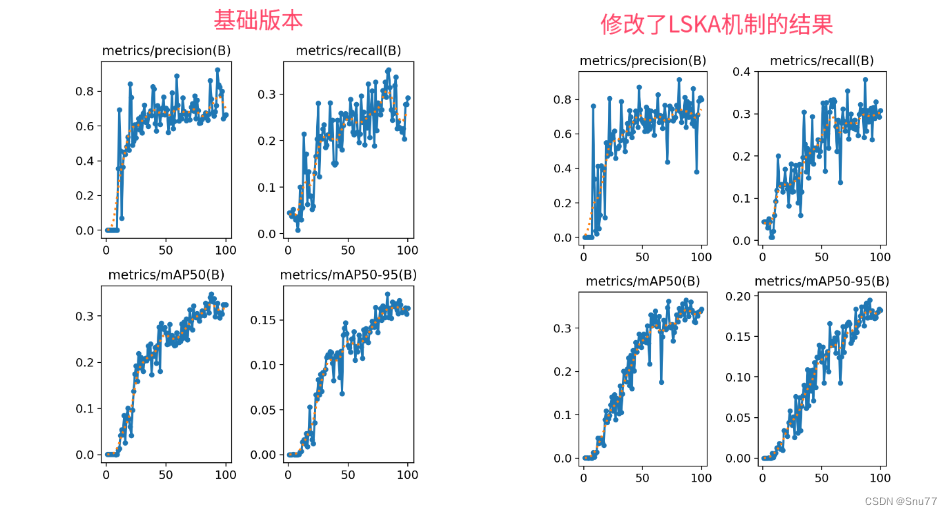
實驗效果圖如下所示->?
本次實驗我只用了一百張圖片檢測的是安全帽訓練了一百個epoch,該結果只能展示出該機制有效,但是并不能產生決定性結果,因為具體的效果還要看你的數據集和實驗環境所影響。
目錄
一、本文介紹?
二、LSKAttention的機制原理?
三、LSKAttention的代碼
四、手把手教你將LSKAttention添加到你的網絡結構中
4.1?LSKAttention的添加教程
4.2?LSKAttention的yaml文件和訓練截圖
4.2.1 LSKAttention的yaml文件
4.2.2 LSKAttention的訓練過程截圖?
五、LSKAttention可添加的位置
5.1 推薦LSKAttention可添加的位置?
5.2圖示LSKAttention可添加的位置?
六、本文總結?
二、LSKAttention的機制原理?
《Large Separable Kernel Attention》這篇論文提出的LSKAttention的機制原理是針對傳統大核注意力(Large Kernel Attention,LKA)模塊在視覺注意網絡(Visual Attention Networks,VAN)中的應用問題進行的改進。LKA模塊在處理大尺寸卷積核時面臨著高計算和內存需求的挑戰。LSKAttention通過以下幾個關鍵步驟和原理來解決這些問題:
-
核分解:LSKAttention的核心創新是將傳統的2D卷積核分解為兩個1D卷積核。首先,它將一個大的2D核分解成水平(橫向)和垂直(縱向)的兩個1D核。這樣的分解大幅降低了參數數量和計算復雜度。
-
串聯卷積操作:在進行卷積操作時,LSKAttention首先使用一個1D核對輸入進行水平方向上的卷積,然后使用另一個1D核進行垂直方向上的卷積。這兩步卷積操作串聯執行,從而實現了與原始大尺寸2D核相似的效果。
-
計算效率提升:由于分解后的1D卷積核大大減少了參數的數量,LSKAttention在執行時的計算效率得到顯著提升。這種方法特別適用于處理大尺寸的卷積核,能夠有效降低內存占用和計算成本。
-
保持效果:雖然采用了分解和串聯的策略,LSKAttention仍然能夠保持類似于原始LKA的性能。這意味著在處理圖像的關鍵特征(如邊緣、紋理和形狀)時,LSKAttention能夠有效地捕捉到重要信息。
-
適用于多種任務:LSKAttention不僅在圖像分類任務中表現出色,還能夠在目標檢測、語義分割等多種計算機視覺任務中有效應用,顯示出其廣泛的適用性。
總結:LSKAttention通過創新的核分解和串聯卷積策略,在降低計算和內存成本的同時,保持了高效的圖像處理能力,這在處理大尺寸核和復雜圖像數據時特別有價值。
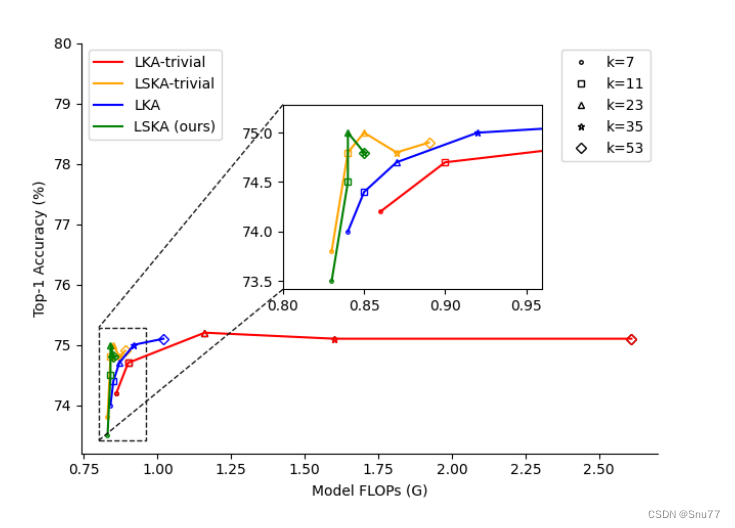
上圖展示了在不同大核分解方法和核大小下的速度-精度權衡。在這個比較中,使用了不同的標記來代表不同的核大小,并且以VAN-Tiny作為對比的模型。從圖中可以看出,LKA的樸素設計(LKA-trivial)以及在VAN中的實際設計,在核大小增加時會導致更高的GFLOPs(十億浮點運算次數)。相比之下,論文提出的LSKA(Large Separable Kernel Attention)-trivial和VAN中的LSKA在核大小增加時顯著降低了GFLOPs,同時沒有降低性能?

上圖展示了大核注意力模塊不同設計的比較,具體包括:
- LKA-trivial:樸素的2D大核深度卷積(DW-Conv)與1×1卷積結合(圖a)。
- LSKA-trivial:串聯的水平和垂直1D大核深度卷積與1×1卷積結合(圖b)。
- 原始LKA設計:在VAN中包括標準深度卷積(DW-Conv)、擴張深度卷積(DW-D-Conv)和1×1卷積(圖c)。
- 提出的LSKA設計:將LKA的前兩層分解為四層,每層由兩個1D卷積層組成(圖d)。其中,N代表Hadamard乘積,k代表最大感受野,d代表擴張率??。
個人總結:提出了一種創新的大型可分離核注意力(LSKA)模塊,用于改進卷積神經網絡(CNN)。這種模塊通過將2D卷積核分解為串聯的1D核,有效降低了計算復雜度和內存需求。LSKA模塊在保持與標準大核注意力(LKA)模塊相當的性能的同時,顯示出更高的計算效率和更小的內存占用。
三、LSKAttention的代碼
將下面的代碼在"ultralytics/nn/modules" 目錄下創建一個py文件復制粘貼進去然后按照章節四進行添加即可(需要按照有參數的注意力機制添加)。
import torch
import torch.nn as nnclass LSKA(nn.Module):def __init__(self, dim, k_size):super().__init__()self.k_size = k_sizeif k_size == 7:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,(3-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=((3-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,2), groups=dim, dilation=2)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=(2,0), groups=dim, dilation=2)elif k_size == 11:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,(3-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=((3-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,4), groups=dim, dilation=2)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=(4,0), groups=dim, dilation=2)elif k_size == 23:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 7), stride=(1,1), padding=(0,9), groups=dim, dilation=3)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(7, 1), stride=(1,1), padding=(9,0), groups=dim, dilation=3)elif k_size == 35:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 11), stride=(1,1), padding=(0,15), groups=dim, dilation=3)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(11, 1), stride=(1,1), padding=(15,0), groups=dim, dilation=3)elif k_size == 41:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 13), stride=(1,1), padding=(0,18), groups=dim, dilation=3)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(13, 1), stride=(1,1), padding=(18,0), groups=dim, dilation=3)elif k_size == 53:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 17), stride=(1,1), padding=(0,24), groups=dim, dilation=3)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(17, 1), stride=(1,1), padding=(24,0), groups=dim, dilation=3)self.conv1 = nn.Conv2d(dim, dim, 1)def forward(self, x):u = x.clone()attn = self.conv0h(x)attn = self.conv0v(attn)attn = self.conv_spatial_h(attn)attn = self.conv_spatial_v(attn)attn = self.conv1(attn)return u * attn
四、手把手教你將LSKAttention添加到你的網絡結構中
4.1?LSKAttention的添加教程
添加教程這里不再重復介紹、因為專欄內容有許多,添加過程又需要截特別圖片會導致文章大家讀者也不通順如果你已經會添加注意力機制了,可以跳過本章節,如果你還不會,大家可以看我下面的文章,里面詳細的介紹了拿到一個任意機制(C2f、Conv、Bottleneck、Loss、DetectHead)如何添加到你的網絡結構中去。
添加教程->YOLOv8改進 | 如何在網絡結構中添加注意力機制、C2f、卷積、Neck、檢測頭
需要注意的是本文的task.py配置的代碼如下(你現在不知道其是干什么用的可以看添加教程)->?
elif m in {LSKA}:args = [ch[f], *args]
4.2?LSKAttention的yaml文件和訓練截圖
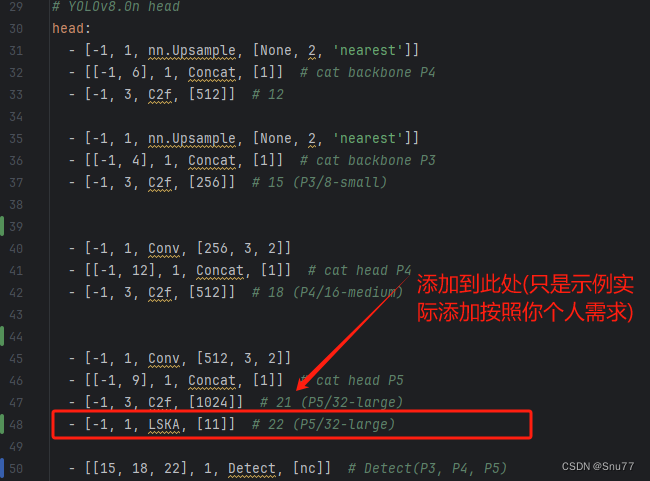
4.2.1 LSKAttention的yaml文件
參數位置可以填寫的有7、11、23、35、41、53(代表卷積核的大小),具體哪個效果好可能要大家自己進行一定的嘗試才可以,需要注意的是這里卷積核越大計算量就會變得越大。
?
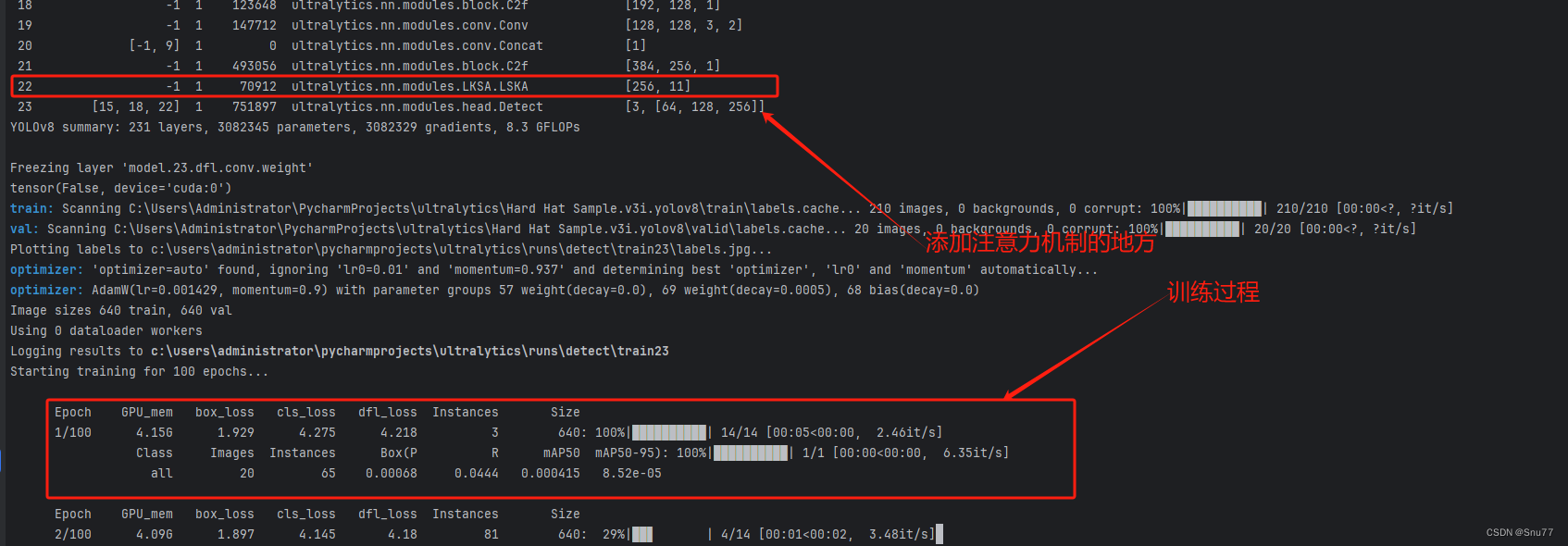
4.2.2 LSKAttention的訓練過程截圖?
下面是我添加了LSKAttention的訓練截圖。
?
五、LSKAttention可添加的位置
5.1 推薦LSKAttention可添加的位置?
LSKAttention可以是一種即插即用的注意力機制,其可以添加的位置有很多,添加的位置不同效果也不同,所以我下面推薦幾個添加的位,置大家可以進行參考,當然不一定要按照我推薦的地方添加。
殘差連接中:在殘差網絡的殘差連接中加入注意力機制(這個位置我推薦的原因是因為DCN放在殘差里面效果挺好的大家可以嘗試)
特征金字塔(SPPF):在特征金字塔網絡之前,可以幫助模型更好地融合不同尺度的特征。
Neck部分:YOLOv8的Neck部分負責特征融合,這里添加注意力機制可以幫助模型更有效地融合不同層次的特征。
輸出層前:在最終的輸出層前加入注意力機制可以使模型在做出最終預測之前,更加集中注意力于最關鍵的特征。
大家可能看我描述不太懂,大家可以看下面的網絡結構圖中我進行了標注。
5.2圖示LSKAttention可添加的位置?

?
六、本文總結?
到此本文的正式分享內容就結束了,在這里給大家推薦我的YOLOv8改進有效漲點專欄,本專欄目前為新開的平均質量分98分,后期我會根據各種最新的前沿頂會進行論文復現,也會對一些老的改進機制進行補充,目前本專欄免費閱讀(暫時,大家盡早關注不迷路~),如果大家覺得本文幫助到你了,訂閱本專欄,關注后續更多的更新~
?專欄回顧:YOLOv8改進系列專欄——本專欄持續復習各種頂會內容——科研必備








)

)









