1 算法介紹
- 一種基于質心的算法
- 通過更新候選質心使其成為給定區域內點的均值
- 候選質心的位置是通過一種稱為“爬山”技術迭代調整的,該技術找到估計的概率密度的局部最大值
1.1 基本形式
- 給定d維空間的n個數據點集X,那么對于空間中的任意點x的均值漂移向量基本形式可以表示為:
- 其中Sk表示數據集的點到x的距離小于球半徑h的數據點
- 漂移過程就類似于”梯度下降“
- 通過計算漂移向量,然后把球圓心x的位置更新一下
- 求解一個向量,使得圓心一直往數據集密度最大的方向移動(每次迭代找到圓里面的平均位置作為新的圓心位置)

1.2 加入核函數的漂移向量
- 引入核函數可以知道數據集的密度,梯度是函數增加最快的方向
- 這里的核函數為
- 對每個點的核函數求微分,有:

- g(x)=-k'(x)
- 第二個中括號前面的是實數值
- 第二項的向量方向與梯度方向一致
- 所以令加入核函數后的偏移向量為:

- 繼續
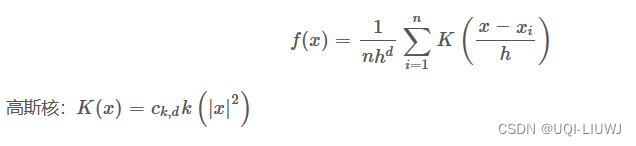
1.3 聚類流程
假設在一個多維空間中有很多數據點需要進行聚類,Mean?Shift的過程如下:
- 在未被標記的數據點中隨機選擇一個點作為中心center;
- 找出離center距離在bandwidth之內的所有點,記做集合M,認為這些點屬于簇c
- 同時,把這些求內點屬于這個類的頻率加1,這個參數將用于最后步驟的分類
- 以center為中心點,計算從center開始到集合M中每個元素的向量,將這些向量相加,得到向量shift 【如果是帶核函數的均值漂移,那么m(x)有額外的計算方式】
- center?=?center+shift。即center沿著shift的方向移動,移動距離是||shift||
- 重復步驟2、3、4,直到shift的大小很小(就是迭代到收斂),記住此時的center
- 這個迭代過程中遇到的點都應該歸類到簇c
- 如果收斂時當前簇c的center與其它已經存在的簇c2中心的距離小于閾值,那么把c2和c合并。否則,把c作為新的聚類,增加1類
- 重復1、2、3、4、5直到所有的點都被標記訪問。
- 分類:根據每個類,對每個點的訪問頻率,取訪問頻率最大的那個類,作為當前點集的所屬類。
對新樣本進行標記是通過找到給定樣本的最近質心來執行的。
2 sklearn 實現
2.1 基本使用方法
class sklearn.cluster.MeanShift(*, bandwidth=None, seeds=None, bin_seeding=False, min_bin_freq=1, cluster_all=True, n_jobs=None, max_iter=300)2.2 主要參數
| bandwidth | 搜尋圓的大小 |
| seeds | 用于初始化核的種子 |
| cluster_all | 如果為true,則所有點都被聚類,即使是那些不在任何核內的孤兒點也一樣。孤兒被分配到最近的核。 如果為false,則孤兒的聚類標簽為-1 |
2.3 舉例
from sklearn.cluster import MeanShift
import numpy as npX = np.array([[1, 2], [1, 4], [1, 0],[10, 2], [10, 4], [10, 0]])ms=MeanShift(bandwidth=1).fit(X)ms.cluster_centers_
'''
array([[10., 4.],[10., 2.],[10., 0.],[ 1., 4.],[ 1., 2.],[ 1., 0.]])
'''ms.labels_
#array([4, 3, 5, 1, 0, 2], dtype=int64)









,看了這篇文章,媽媽再也不用擔心我Linux找不到門了。)
)


識別手語)




:通過source_location實現日志函數)