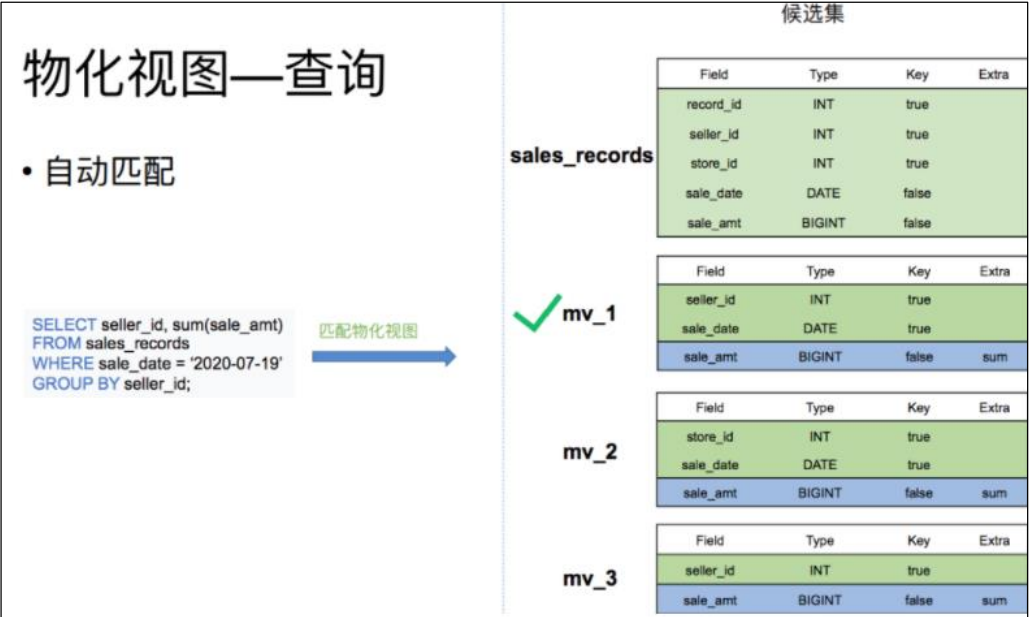
物化視圖創建完成后,用戶的查詢會根據規則自動匹配到最優的物化視圖。
比如我們有一張銷售記錄明細表,并且在這個明細表上創建了三張物化視圖。一個存儲了不同時間不同銷售員的售賣量,一個存儲了不同時間不同門店的銷售量,以及每個銷售員的總銷售量。
當查詢7月19日,各個銷售員都買了多少錢的話。就可以匹配 mv_1 物化視圖。直接對 mv_1 的數據進行查詢。
查詢自動匹配
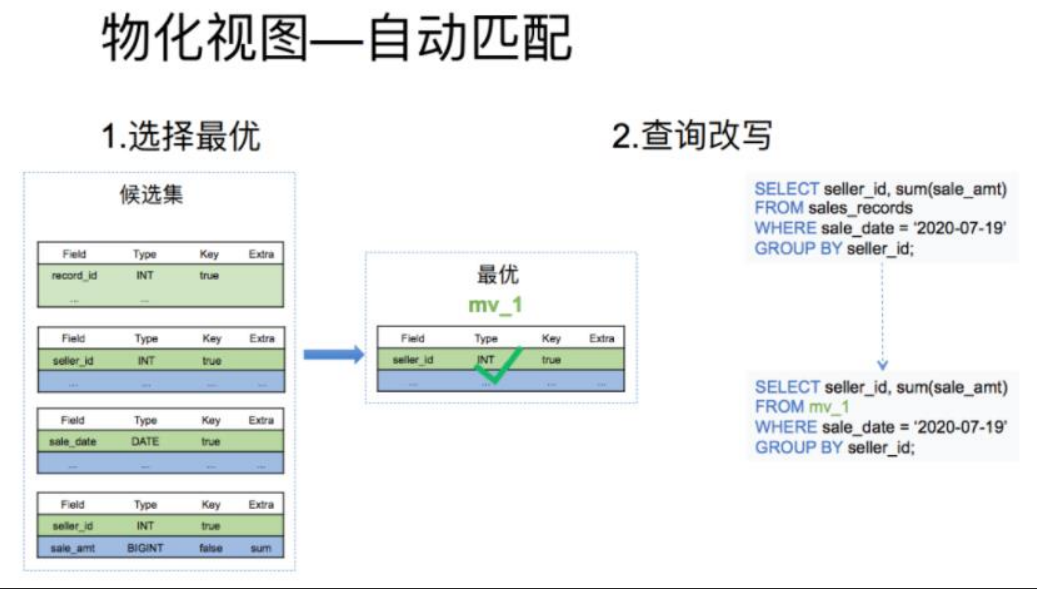
物化視圖的自動匹配分為下面兩個步驟:
(1)根據查詢條件刪選出一個最優的物化視圖:這一步的輸入是所有候選物化視圖表的元數據,根據查詢的條件從候選集中輸出最優的一個物化視圖
(2)根據選出的物化視圖對查詢進行改寫:這一步是結合上一步選擇出的最優物化視圖,進行查詢的改寫,最終達到直接查詢物化視圖的目的。

其中 bitmap 和 hll 的聚合函數在查詢匹配到物化視圖后,查詢的聚合算子會根據物化視圖的表結構進行一個改寫。
最優路徑選擇
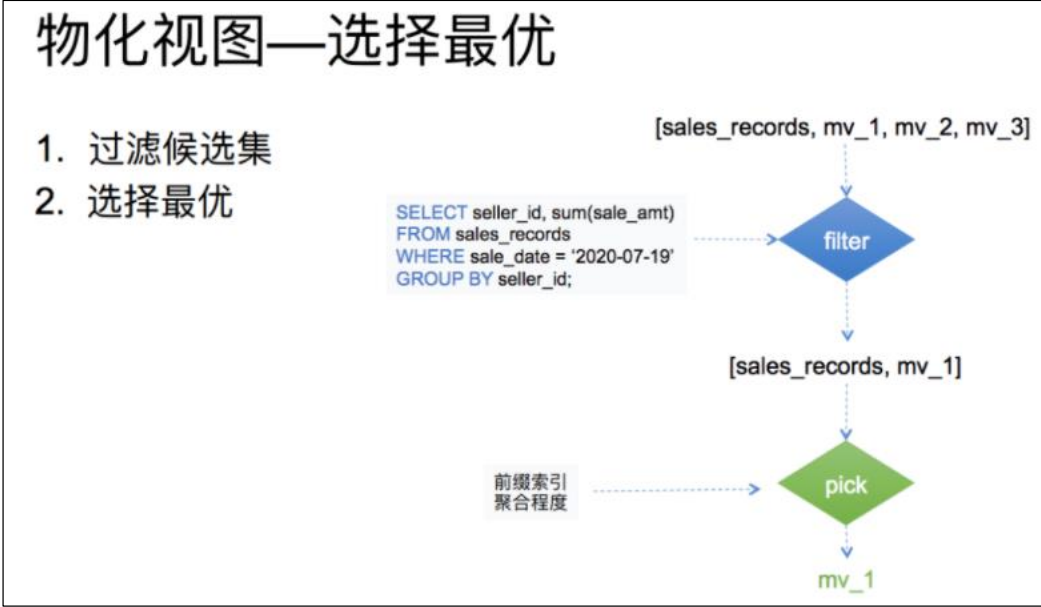
這里分為兩個步驟:
(1)對候選集合進行一個過濾。只要是查詢的結果能從物化視圖數據計算(取部分行,部分列,或部分行列的聚合)出都可以留在候選集中,過濾完成后候選集合大小>=1。
(2)從候選集合中根據聚合程度,索引等條件選出一個最優的也就是查詢花費最少物化視圖。
這里再舉一個相對復雜的例子,來體現這個過程:

候選集過濾目前分為 4 層,每一層過濾后去除不滿足條件的物化視圖。
比如查詢 7 月 19 日,各個銷售員都買了多少錢,候選集中包括所有的物化視圖以及 base表共 4 個:
第一層過濾先判斷查詢 where 中的謂詞涉及到的數據是否能從物化視圖中得到。也就是銷售時間列是否在表中存在。由于第三個物化視圖中根本不存在銷售時間列。所以在這一層過濾中,mv_3 就被淘汰了。
第二層是過濾查詢的分組列是否為候選集的分組列的子集。也就是銷售員 id 是否為表中分組列的子集。由于第二個物化視圖中的分組列并不涉及銷售員 id。所以在這一層過濾中,mv_2 也被淘汰了。
第三層過濾是看查詢的聚合列是否為候選集中聚合列的子集。也就是對銷售額求和是否能從候選集的表中聚合得出。這里 base 表和物化視圖表均滿足標準。
最后一層是過濾看查詢需要的列是否存在于候選集合的列中。由于候選集合中的表均滿足標準,所以最終候選集合中的表為 銷售明細表,以及 mv_1,這兩張。
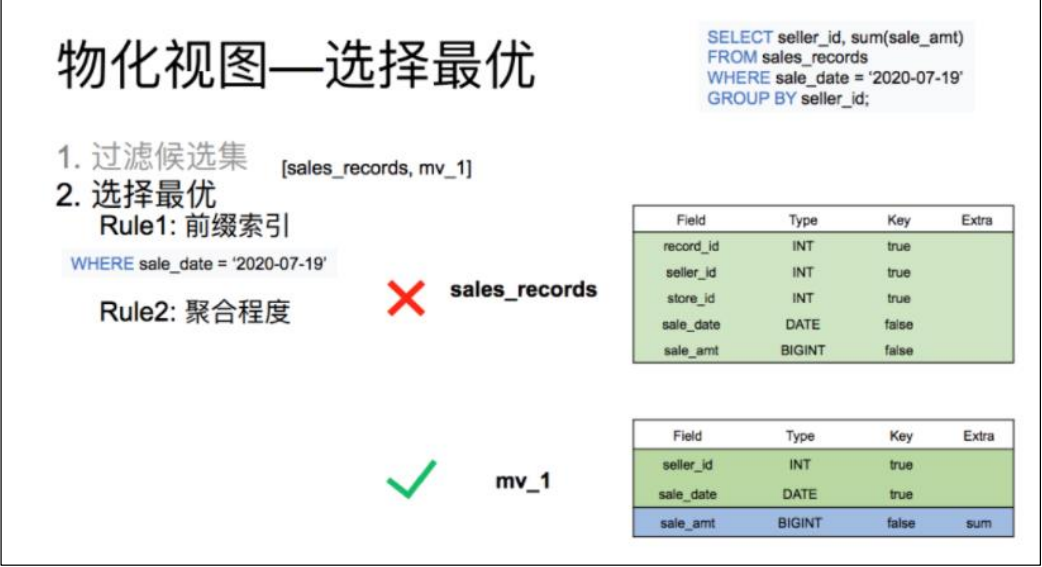
候選集過濾完后輸出一個集合,這個集合中的所有表都能滿足查詢的需求。但每張表的查詢效率都不同。這時候就需要再這個集合根據前綴索引是否能匹配到,以及聚合程度的高低來選出一個最優的物化視圖。
從表結構中可以看出,base 表的銷售日期列是一個非排序列,而物化視圖表的日期是一個排序列,同時聚合程度上 mv_1 表明顯比 base 表高。所以最后選擇出 mv_1 作為該查詢的最優匹配。

最后再根據選擇出的最優解,改寫查詢。
剛才的查詢選中 mv_1 后,將查詢改寫為從 mv_1 中讀取數據,過濾出日志為 7月19日的 mv_1 中的數據然后返回即可。
查詢改寫

有些情況下的查詢改寫還會涉及到查詢中的聚合函數的改寫。
比如業務方經常會用到 count distinct 對 PV UV 進行計算。
例如:
廣告點擊明細記錄表中存放哪個用戶點擊了什么廣告,從什么渠道點擊的,以及點擊的時間。并且在這個 base 表基礎上構建了一個物化視圖表,存儲了不同廣告不同渠道的用戶bitmap 值。
由于 bitmap union 這種聚合方式本身會對相同的用戶 user id 進行一個去重聚合。當用戶查詢廣告在 web 端的 uv 的時候,就可以匹配到這個物化視圖。匹配到這個物化視圖表后就需要對查詢進行改寫,將之前的對用戶 id 求 count(distinct) 改為對物化視圖中 bitmap union列求 count。
所以最后查詢取物化視圖的第一和第三行求 bitmap 聚合中有幾個值。
使用及限制

(1)目前支持的聚合函數包括,常用的 sum,min,max count,以及計算 pv ,uv, 留存率,等常用的去重算法 hll_union,和用于精確去重計算 count(distinct)的算法bitmap_union。
(2)物化視圖的聚合函數的參數不支持表達式僅支持單列,比如: sum(a+b)不支持。
(3)使用物化視圖功能后,由于物化視圖實際上是損失了部分維度數據的。所以對表的 DML 類型操作會有一些限制:
如果表的物化視圖 key 中不包含刪除語句中的條件列,則刪除語句不能執行。 比如想要刪除渠道為 app 端的數據,由于存在一個物化視圖并不包含渠道這個字段,則這個刪除不能執行,因為刪除在物化視圖中無法被執行。這時候你只能把物化視圖先刪除,然后刪除完數據后,重新構建一個新的物化視圖。
(4)單表上過多的物化視圖會影響導入的效率:導入數據時,物化視圖和 base 表數據是同步更新的,如果一張表的物化視圖表超過 10 張,則有可能導致導入速度很慢。這就像單次導入需要同時導入 10 張表數據是一樣的。
(5)相同列,不同聚合函數,不能同時出現在一張物化視圖中,比如:select sum(a), min(a) from table 不支持。
(6)物化視圖針對 Unique Key 數據模型,只能改變列順序,不能起到聚合的作用,所以在 Unique Key 模型上不能通過創建物化視圖的方式對數據進行粗粒度聚合操作。

)

)





)
![[chroot+seccomp逃逸] THUCTF2019 之 固若金湯](http://pic.xiahunao.cn/[chroot+seccomp逃逸] THUCTF2019 之 固若金湯)
】)






)
