NVIDIA在9月20日發布的NVIDIA DRIVE Thor 新一代集中式車載計算平臺,可在單個安全、可靠的系統上運行高級駕駛員輔助應用和車載信息娛樂應用。提供 2000 萬億次浮點運算性能(2000 萬億次8位浮點運算)。NVIDIA當代產品是Orin,算力是256 TOPS。再后面是已發布的Altan,算力是1000TFLOPS,這次的Thor算力是2000 TOPS強大的著實讓人震驚(但是芯片2025才出來,是時間好像有些遠的PPT產品)。
產生一個疑問,這個算力是什么算力?如何計算/標定?
先看三個名詞解釋:
TFLOPS(teraFLOPS)等于每秒一萬億(=10^12)次的浮點運算。FLOPS(Floating-point operations per second的縮寫),即每秒浮點運算次數。
TOPS(Tera Operations Per Second的縮寫),1TOPS代表處理器每秒鐘可進行一萬億次(10^12)操作。
DMIPS:Dhrystone Million Instructions executed Per Second,每秒執行百萬條指令,用來計算同一秒內系統的處理能力,即每秒執行了多少百萬條指令。
鑒于NVIDIA的Thor還是個PPT,還沒有確切產品資料情況下,我們先看下現有芯片的此種算力。特斯拉FSD(自動駕駛的芯片/區別于智能座艙SOC)。
===============================================
NPU算力
NPU算力。TOPS僅指處理器每秒萬億次操作,需要結合具體數據類型精度才可以于FLOPS轉換。8位精度下的MAC(乘積累加運算,MAC/ Multiply Accumulate)數量在FP16(半浮點數/16位浮點數)精度下等于減少了一半。 PS:NVIDIA、Intel和Arm攜手合作,共同撰寫FP8 Formats for Deep Learning白皮書。目前業界已由32位元降至16位元,如今甚至已轉向8位元(FP8精度: 8 位元浮點運算規格),這也是NVIDIA使用FP8來表征算力的原因。NVIDIA上面Thor 2000TOPS也說的是這個東東。
在NPU中,芯片都用MAC陣列(乘積累加運算,MAC/ Multiply Accumulate)作為NPU給神經網絡加速,許多運算(如卷積運算、點積運算、矩陣運算、數字濾波器運算、乃至多項式的求值運算)都可以分解為數個MAC指令,因此可以提高上述運算的效率。MAC矩陣是AI芯片的核心,是很成熟的架構。英偉達也在示例中使用3維的立方體計算單元完成矩陣乘加運算。TOPS是MAC在1秒內操作的數,計算公式為:
TOPS = MAC矩陣行 * MAC矩陣列 * 2 * 主頻;
PS:公式中的 2 可理解為一個MACC(乘加運算)為一次乘法和一次加法為2次運算操作。下面以特斯拉自動駕駛FSD芯片為例。
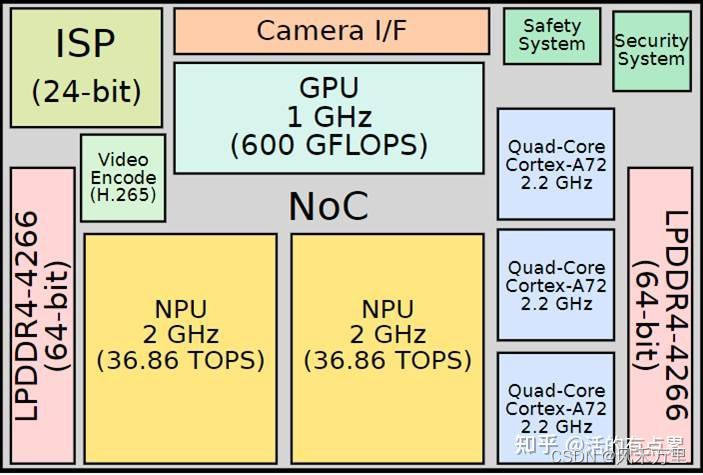
特斯拉資料中,該芯片的目標是自主4級和5級。FSD芯片采用三星(德克薩斯州奧斯汀的工廠)的14納米工藝技術制造,集成了3個四核Cortex-A72集群,共有12個CPU,工作頻率為2.2GHz,1個(ARM的)Mali G71 MP12 GPU,2個NPU工作頻率為2GHz,還有其他各種硬件加速器。FSD最多支持128位LPDDR4-4266內存。
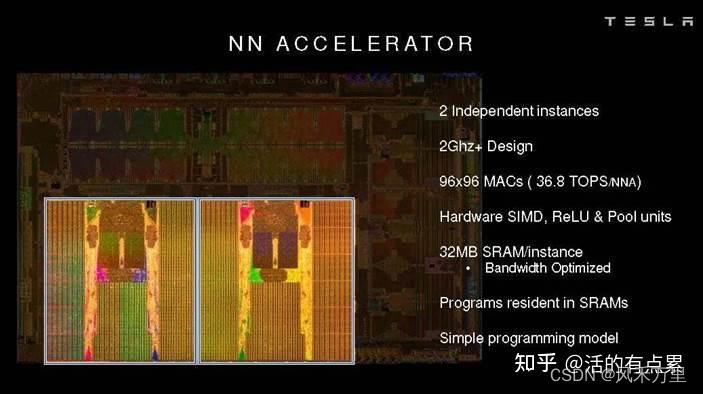
上圖右側第三行清楚的描述到:“ 96*96 MACs(單核)(36.8 TOPS/NNA)”,我們根據最上面計算公式:
TOPS = MAC矩陣行 * MAC矩陣列 * 2 * 主頻 = 96 * 96 * 2 * 2G = 36.864 TOPS(單核)
上面結果和如上圖片中算力數字匹配,是NPU單核算力。特斯拉FSD(Full Self-Driving) IC 中有2個NPU:每個周期,從SRAM讀取256byte字節的激活數據和另外128byte的權重數據到MAC陣列中。每個NPU擁有96x96 MAC,另外在精度方面,乘法為8x8bit,加法為32bit,兩種數據類型的選擇很大程度上取決于他們降功耗的努力(例如32bitFP加法器的功耗大約是32bit整數加法器的9倍)。如上圖,在2GHz的工作頻率下,每個NPU的算力為36.86TOPS,FSD芯片峰值算力為73.7TOPS(兩個單核NPU算力的累加)。
=====================================================
CPU的算力(ARM內核)
移遠通信推出SA8155P平臺的SIP模塊AG855G,移遠官網介紹中描述“AG855G的 AI 綜合算力能夠達到 8 TOPS”。那CPU算力呢?
高通官網及產品摘要中沒有找到對其產品CPU算力的直接數字描述,但是在移遠通信描述SA8155P “八核 64 位處理器,1+3+4三叢集架構,算力高達100K DMIPS”(有其他新聞媒體描述其算力為 95 KDMIPS)。加之之前找到的SA8155P 數據如下:
高通2019年發布的智能座艙芯片SA8155P,7nm工藝。CPU架構是Kryo 435(高通自己的命名)8個64位核心,3個叢集(Gold代表大核心,Silver代表小核心)
第1叢集:1×Kryo 435 Gold@2.419GHz
第2叢集:3×Kryo 435 Gold@2.131GHz
第3叢集:4×Kryo 435 Silver@1.785GHz
PS:前兩個叢集是基于ARM Cortex-A76架構定制的,第三個叢集是Cortex-A55核心定制。
Graphics: Adreno 640 700MHz
Memory:4x16,2092.8MHz,LPDDR4X with ECC
NPU:NPU130 with ECC 908 MHz
Compute DSP:Q6 V66G (4 threads/2 clusters, 1024KB L2, 4x HVX) with ECC 1.4592 GHz
……
算力數據描述:
GPU計算性能:1.1 TFLOPS
AI(NPU)算力:8 TOPS(每秒運算8萬億次)
CPU算力:100K DMIPS (也有說95K DMIPS的)
這個CPU算力是怎么來的,如下正題:CPU算力計算方式描述(DMIPS:主要測整數計算能力)
以ARM核為主查詢,ARM官網中描述,在“The Cortex-M3 RTL is delivered to licensees together with an "example" system testbench for simulation of a simple Cortex-M3 system, and a number of test programs including a Dhrystone test called "dhry". ”描述了DMIPS/MHz的計算方式:
DMIPS/MHz = 10^6 / (1757 * Number of processor clock cycles per Dhrystone loop)
ARM官網中有Cortex-M3和M4的數據(如下截圖)

ARM官網網頁資料截圖
我們可以計算Cortex-M3在Wait-states 0中的DMIPS/MHz是:
DMIPS/MHz = 10^6 / (1757 * 460.2)= 1.2367 ≈ 1.24 DMIPS/MHz
上面計算結果和圖片數據對應。在ARM官網未查到有Cortex-A76的DMIPS/MHz數值描述,但查詢到在發布Cortex-A76時,ARM首席架構師Filippo強調Cortex-A76架構較上一代(A75)性能至少提升35%,在一些數學運行任務上,新架構處理器可以有 50%—70% 的提升。
網上資料基本都是到Cortex-A75就完了,查詢到如下架構的DMIPS/MHz如下:
Arm Cortex-A75 5.2 DMIPS/MHz
Arm Cortex-A73 4.8 DMIPS/MHz
Arm Cortex-A72 4.7 DMIPS/MHz
Arm Cortex-A57 4.1 DMIPS/MHz
Arm Cortex-A55 2.7 DMIPS/MHz
Arm Cortex-A53 2.3 DMIPS/MHz
雖然高通官網及產品摘要中沒有找到對其產品CPU算力的直接數字描述,但是結合如上各網絡資料,我們視圖計算下高通這個SA8155P的真實CPU算力。
SA8155P的CPU算力計算如下(按照A75性能提升50%來計算,即 5.2 * 1.5 = 7.8 DMIPS/MHz )
SA8155P算力 = 2.419GHz * 1核 * 7.8 DMIPS/MHz + 2.131GHz * 3核 * 7.8 DMIPS/MHz + 1.785GHz * 4核 * 2.7 DMIPS/MHz = 18868.2 + 49865.4 + 19278 = 88011.6 DMIPS ≈ 88 KDMIPS
此數值和移遠通信公布的100 KDMIPS算力有約12%的誤差,但這其實是用ARM的方法計算了下三星的處理器。三星將ARM Cortex-A76內核優化后叫Kryo內核,還有硬件加速器等,猜想是三星對A76的性能優化已超50%性能提升,已到達ARM架構師Filippo(上面說的)所描述的50%-70%性能提升的中位數。另外,存儲器讀寫速度、硬件加速引擎等也都可能直接影響CPU算力表現。
當然,也有可能是如上某些數據、信息或計算還不確切。大家有資料或深入研究的也請指出。
=================================================
GPU算力
…………..后面再寫了,下面把NVIDIA的Thor發布的芯片構成信息整理:
在自動駕駛領域,提高駕駛安全性,傳感器在數量和分辨率上都面臨同步增長。同時也引入了更復雜的AI模型(NVIDIA大致每2年的產品都會有一個質的提升)。安全性是機器人開發的首要準則,要求傳感器和算法具備多樣性和冗余性。這些都需要更高的數據處理能力。
NVIDIA為實現這個應用了Grace、Hopper和Ada Lovelace。
1. Hopper有令人驚嘆的Transformer引擎以及Vision Transformer的快速變革。
2. 在Ada中多實例GPU的發明有助于車載計算資源的集中化,同時也降低了成本。
3. Grace是NVIDIA數據中心處理器。通常所有的并行處理算法都是由GPU卸載和加速的,因此其余的工作負載往往收到單線程的限制,而Grace正好擁有出色的單線程性能。
Thor內部Arm Poseidon AE內核(汽車增強版本)。Thor支持通過NVLink-C2C芯片互聯技術連接兩個芯片運行單個操作系統(現有很多興能源汽車廠家將2~4顆Orin處理器集合起來應用來滿足算力需求)。
Thor可以配置為多種模式,Thor可以將其 2000 TOPS和 2000 TFLOPs全部用于自動駕駛工作流中,也可以將其配置為一部分用于駕駛艙AI和信息娛樂,一部分用于輔助駕駛。Thor有多計算域隔離,允許并發、對時間敏感的多進程無中斷運行。可以在一臺計算機上同時運行Linux、QNX和Android。Thor集中了眾多計算資源,不僅降低了成本和功耗,同時功能也實現了質的飛躍。

NVIDIA Thor PCBA板卡
提前3年發布,也真是難為NVIDIA了,給一眾跟隨的 IC 廠商指明了前進的方向。
——第4期)



解決方法)






)


)


安裝Protocol Buffers)

