因為 Duplicate 模型沒有聚合的語意。所以該模型中的 ROLLUP,已經失去了“上卷”這一層含義。而僅僅是作為調整列順序,以命中前綴索引的作用。下面詳細介紹前綴索引,以及如何使用 ROLLUP 改變前綴索引,以獲得更好的查詢效率。
前綴索引
不同于傳統的數據庫設計,Doris 不支持在任意列上創建索引。Doris 這類 MPP 架構的 OLAP 數據庫,通常都是通過提高并發,來處理大量數據的。
本質上,Doris 的數據存儲在類似 SSTable(Sorted String Table)的數據結構中。該結構是一種有序的數據結構,可以按照指定的列進行排序存儲。在這種數據結構上,以排序列作為條件進行查找,會非常的高效。
在 Aggregate、Uniq 和 Duplicate 三種數據模型中。底層的數據存儲,是按照各自建表語句中,AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY 中指定的列進行排序存儲的。而前綴索引,即在排序的基礎上,實現的一種根據給定前綴列,快速查詢數據的索引方式。
我們將一行數據的前 36 個字節 作為這行數據的前綴索引。當遇到 VARCHAR 類型時,前綴索引會直接截斷。舉例說明:
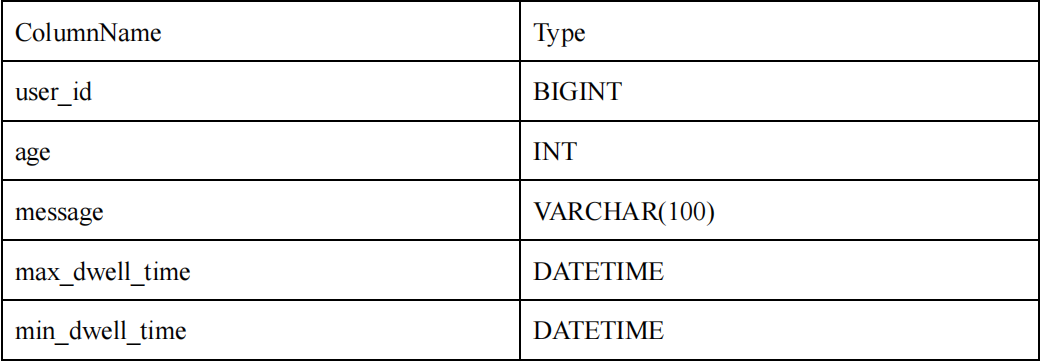
1)以下表結構的前綴索引為 user_id(8 Bytes) + age(4 Bytes) + message(prefix 20 Bytes)
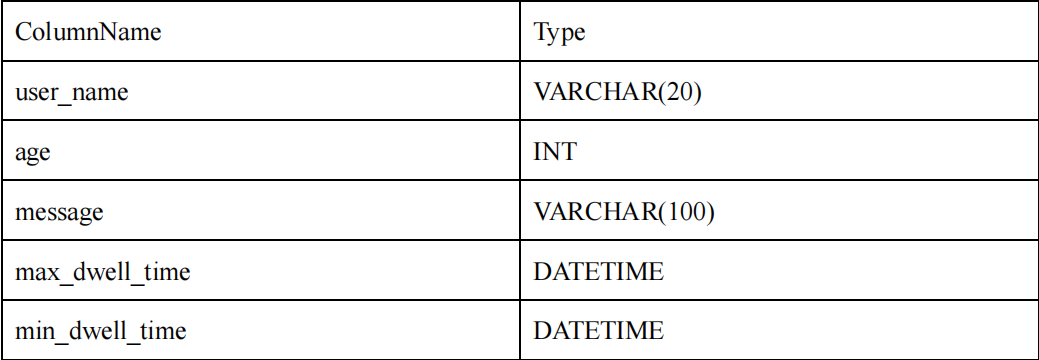
2)以下表結構的前綴索引為 user_name(20 Bytes)。即使沒有達到 36 個字節,因為遇到VARCHAR,所以直接截斷,不再往后繼續。
3)當我們的查詢條件,是前綴索引的前綴時,可以極大的加快查詢速度。比如在第一個例子中,我們執行如下查詢:
SELECT * FROM table WHERE user_id=1829239 and age=20;
該查詢的效率會遠高于如下查詢:
SELECT * FROM table WHERE age=20;
所以在建表時,正確的選擇列順序,能夠極大地提高查詢效率。
ROLLUP 調整前綴索引
因為建表時已經指定了列順序,所以一個表只有一種前綴索引。這對于使用其他不能命中前綴索引的列作為條件進行的查詢來說,效率上可能無法滿足需求。因此,我們可以通過創建 ROLLUP 來人為的調整列順序。舉例說明。 Base 表結構如下:

我們可以在此基礎上創建一個 ROLLUP 表:
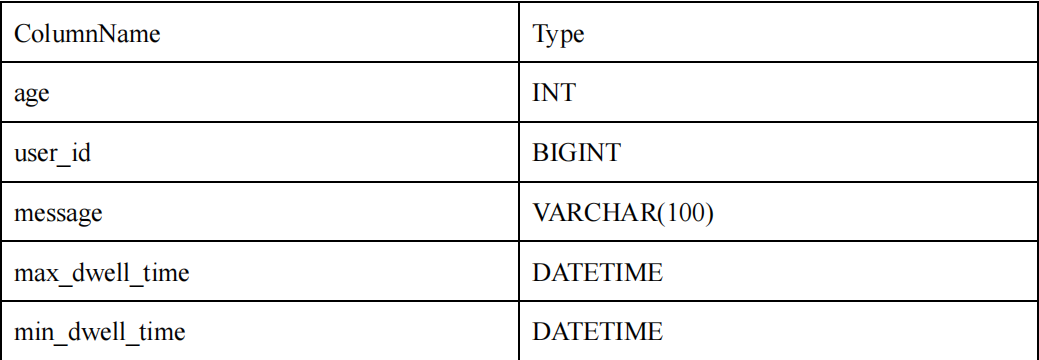
可以看到,ROLLUP 和 Base 表的列完全一樣,只是將 user_id 和 age 的順序調換了。那么當我們進行如下查詢時:
SELECT * FROM table where age=20 and message LIKE "%error%";
會優先選擇 ROLLUP 表,因為 ROLLUP 的前綴索引匹配度更高


安裝Protocol Buffers)







Jar包到Maven私有倉庫)








)