數據缺失值預處理
- 創建數據集
- 展示數據集
- 缺失值處理
創建數據集
首先創建一個人工數據集,作為下文對數據缺失值預處理的案例,
import osos.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:f.write('NumRooms, Alley, Price\n')f.write('NA, Pave, 127500\n')f.write('2,NA, 106000\n')f.write('4,NA, 178100\n')f.write('NA,NA, 140000\n')
案例中包含數值缺失值(屬性NumRooms)字符串缺失值(屬性Alley);
展示數據集
通過 pandas 庫 read_csv 函數讀取 csv 文件,
import pandas as pddata = pd.read_csv(data_file)
print(data)
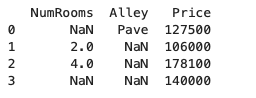
需要注意的是,不是 NaN 而是 NA 的原因,是因為上述創建數據集時 NA 前包含空格;
缺失值處理
對缺失數據的處理,典型方法包括 插值 與 刪除,而對于很少的數據集,一般不采用刪除的方法。以下展示插值的方法,插值包含 對于數值缺失值的插值 以及 對于字符串缺失值的插值。
首先對數值缺失值做插值處理,插入平均值,
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]inputs = inputs.fillna(inputs.mean(numeric_only=True))
print(inputs)
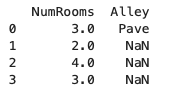
注意加入 numeric_only=True 的原因是為了區分出數值缺失值以及字符串缺失值;
對于字符串的缺失值,可以把所有缺失值做成一個類。列中所有不同的值各自作為一個類,通過 pandas 庫的 get_dummies 函數,進行分類操作,
inputs = pd.get_dummies(inputs, dummy_na=True, dtype=int)
print(inputs)

如果不加入 dtype=int 屬性,則一般默認為結果值為 True/False 而非 1/0;
將所有的缺失值以及所有的字符串轉化為數值后,就可以轉換為張量格式的 tensor 了,
import torchX, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
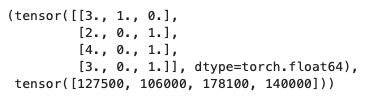
64位浮點數一般計算比較慢,所以深度學習通常會使用32位浮點數;
以上便是一個對于數據缺失值的簡單處理,以及最后轉化為深度學習的數據結構。

)


安裝Protocol Buffers)







Jar包到Maven私有倉庫)






