📜作者:不想脫發的基兄
📺專欄:《嵌入式面試》
📣格言:不管前方的路有多苦,只要走的方向正確,不管多么崎嶇不平,都比站在原地更接近幸福。

前言:
2022年秋招我面試嵌入式MCU開發方向,經過了多場的筆試與面試,在準備的過程中看了非常多的資料,我的匯總的筆記一直寫在有道云筆記中,沒有分享出來。現在已經到了23年春招了,特此整理后分享出來。資料看過了覺得不錯就保存下來了,如果有不對的地方,歡迎批評指正,侵權聯刪!
1、遞歸函數定義沒有問題,遞歸深層次后易引發什么問題?
(1)影響執行效率
(2)棧溢出。
因為每一次調用函數是,棧區都要給函數分配空間,而且上一次調用并沒有結束,調用的次數太多,棧區的內存不夠分配了,便會出現棧溢出的情況。
2、堆與棧的區別?
(1)棧的空間是系統自動分配和回收,堆的空間是用戶手動分配回收(malloc,calloc,realloc,free)
(2)棧的空間較小,堆的空間較大
(3)棧的地址空間往地址向下增長,堆的地址空間是由低地址到高地址
(4)棧的存儲效率更高
3、循環控制條件關鍵字goto被經常使用,但是goto的使用場合為什么受到局限?
因為goto會破壞程序的棧邏輯。
4、循環控制條件關鍵字goto的使用場景有哪些?
(1)常用來跳出死循壞;
(2)打印錯誤;
(3)goto被經常使用,只是使用場合受到局限,因為他會破壞程序的棧邏輯。
5、字節對齊的理解
5.1 什么是字節對齊?
字節對齊主要是針對結構體而言的,通常編譯器會自動對其成員變量進行對齊,以提高數據存取的效率;
5.2 字節對齊的兩種方式
默認對齊方式、指定對齊方式;
(1)默認對齊方式內存分配滿足以下三個條件:
結構體第一個成員的地址和結構體的首地址相同;
結構體每個成員地址相對于結構體首地址的偏移量(offset)是該成員大小的整數倍,如果不是則編譯器會在成員之間添加填充字節;
結構體總的大小要是其成員中最大size的整數倍,如果不是編譯器會在其末尾添加填充字節。
如char是1字節,short是2字節,int是4字節...
(2)指定對齊方式使用以下方式聲明:
//注:通過#pragma pack(n)改變C編譯器的字節對齊方式
#pragma pack(4) //安裝4字節的對齊方式指定對齊方式內存分配滿足以下幾個條件:
結構體第一個成員的地址和結構體的首地址相同
結構體每個成員的地址偏移需要滿足:N大于等于該成員的大小,那么該成員的地址偏移需滿足默認對齊方式(地址偏移是其成員大小的整數倍);N小于該成員的大小,那么該成員的地址偏移是N的整數倍。
結構體總的大小需要時N的整數倍,如果不是需要在結構體的末尾進行填充。
如果N大于結構體成員中最大成員的大小,則N不起作用,仍然按照默認方式對齊。
注:在使用#pragma pack設定對齊方式一定要是2的整數冪,也就是(1,2,4,8,16,…),不然不起作用的,仍然按照默認方式對齊。
例1:結構體使用字節對齊為1
// date:2022年 11月 08日 星期二 19:35:36 CST
// author: HeiBaiYe
// path: /mnt/hgfs/CD2206/02-c語言
#include <stdio.h>#pragma pack(1) //通過#pragma pack(n)改變C編譯器的字節對齊方式 在C語言中,結構是一種復合數據類型
struct s1{char ch; // 1int a; //4double b; //8char c1; //1
};#pragma pack(1)
struct s2{char ch; //1int a; //4double b; //8
};int main()
{printf("s1的大小:%ld\n ",sizeof(struct s1));printf("s2的大小:%ld\n ",sizeof(struct s2));return 0;
}
結果:
s1的大小:14
s2的大小:13
例2:結構體使用默認字節對齊方式,m值
// date:2022年 11月 08日 星期二 19:35:36 CST
// author: HeiBaiYe
// path: /mnt/hgfs/CD2206/02-c語言
#include <stdio.h>
struct s1{char ch; // 1int a; //4double b; //8char c1; //1
};struct s2{char ch; //1int a; //4double b; //8
};int main()
{printf("s1的大小:%ld\n ",sizeof(struct s1));printf("s2的大小:%ld\n ",sizeof(struct s2));return 0;
}結果:
s1的大小:24
s1的大小:16
參考鏈接:https://blog.csdn.net/wdl20170204/article/details/109386825
6、局部變量和全局變量可以重名嗎?
(1)能,局部變量會屏蔽全局變量。C++中要用全局變量,需要使用 "::"(域解析符) 。C語言中局部變量可以與全局變量同名,在函數內引用這個變量時,會用到同名的局部變量,而不會用到全局變量。
(2)對于有些編譯器而言,在同一個函數內可以定義多個同名的局部變量,比如在兩個循環體內都定義一個同名的局部變量,而那個局部變量的作用域就在那個循環體內。
7、UNIX系統中fsync函數的作用?
fsync()負責將參數fd 所指的文件數據, 由系統緩沖區寫回磁盤, 以確保數據同步。
頭文件:#include
定義函數:int fsync(int fd);
函數說明:fsync()負責將參數fd 所指的文件數據, 由系統緩沖區寫回磁盤, 以確保數據同步.
返回值:成功則返回0, 失敗返回-1, errno 為錯誤代碼。
參考鏈接:https://blog.csdn.net/Michaelwubo/article/details/41210547
8、const關鍵字使用有哪些?
8.1 修飾變量
const的 常規用法,在變量初次定義時賦初,并用關鍵字const修飾,使變量只可訪問,不能重新賦值修改變量。
8.2 修飾指針
(1)限制指針變量修飾:指針變量指向的位置不能被修改。定義時,被 const 修飾的指針變量指針只能在定義時初始化,不能定義之后重新指向新的數據。
(2)限制指針變量指向的數據修飾【指針的解引用】:修飾的指針變量指向的變量的值不能被修改,但是該指針可以指向其它空間。
(3)同時限制指針變量和指針變量指向的變量的值修飾:指針變量指向的位置不能被修改,并且指針變量指向變量的值也不能被修改。
(4)修飾函數形參【指針】:函數形參可以利用const關鍵字進行限制,來防止在函數內部修改指針指向的數據。
9、內存布局中有哪些段?
文本段(.text)、數據段(.data)、.bss段、堆(heap)、棧(stack)
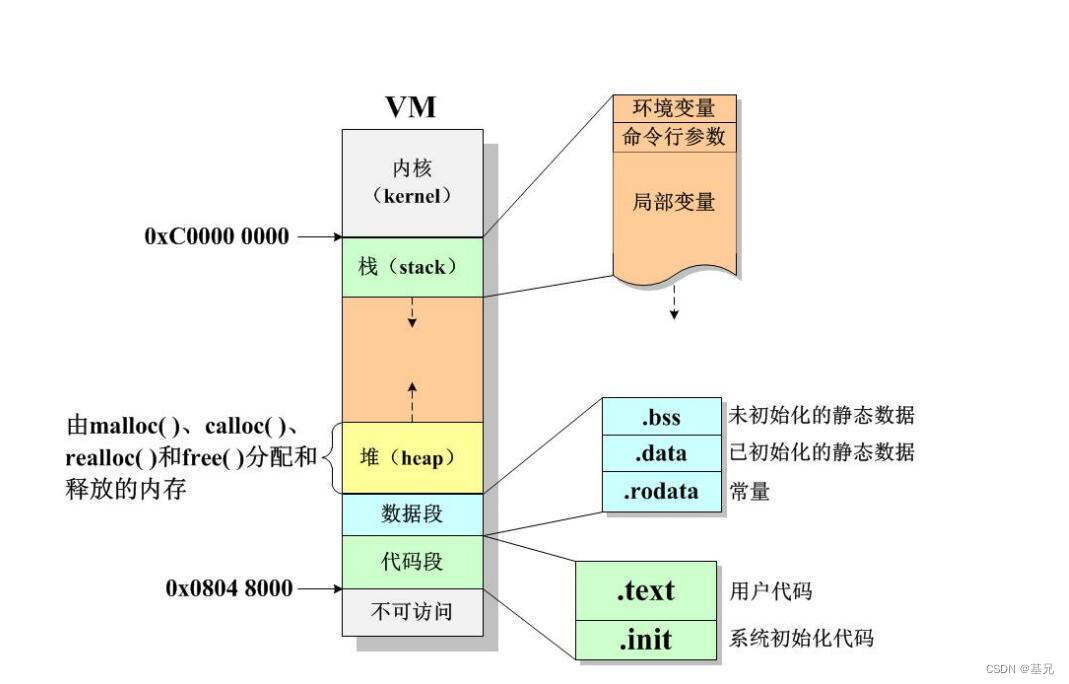
圖 虛擬空間的各個部分
10、volatile關鍵字的作用?
(1)裸機編程時,某變量是指向寄存器中某一特定地址,添加volatile的變量不進行優化處理;
(2)某函數與中斷函數共享全局變量時,加上volatile,讓編譯器不要省略該變量的訪問;
(3)多線程中修飾共享全局變量,讓編譯器不要省略該變量的訪問。
11、sizeof()與strlen()的區別?
(1)sizeof是運算符,計算能容納實現所建立的最大對象的字節大小,參數可以是數組、指針、類型、對象、函數等;
(2)strlen是函數,功能是返回字符串的長度,參數必須是字符型指針(char*)。
12、內存泄漏和內存溢出是什么?
(1)內存溢出:指程序申請內存時,沒有足夠的內存供申請者使用。或者說,給了你一塊存儲int類型數據的存儲空間,但是你卻存儲long類型的數據,那么結果就是內存不夠用,此時就會報錯Out Of Memory,即所謂的內存溢出。
(2)內存泄漏:是指程序在申請內存后,無法釋放已申請的內存空間。一次內存泄漏似乎不會有大的影響,但內存泄漏堆積后的后果就是內存溢出。
13、定義一個指針賦值字符串與定義一個數組賦值字符串有什么區別?
(1)指針賦值字符串是指向一定內存的指針,只不過是指向字符串常量的指針,指針中的數據不能修改。
(2)數組賦值字符串是一片char型的數組,可以理解為緩沖區,只不過是賦值為了字符串。
14、malloc()與calloc分配空間有什么不一樣?
(1)malloc申請后空間的值是隨機的,并沒有進行初始化;而calloc卻在申請后,對空間逐一進行初始化,并設置值為0;
(2)malloc要申請的空間大小,需要我們手動的去計算;calloc并不需要人為的計算空間的大小。
15、實現循環的方式?
while、for 、do while 、goto 循環。
16、全局變量和局部變量在內存中有什么不同?
(1)全局變量保存在內存的全局存儲區中,占用靜態的存儲單元;
(2)局部變量保存在棧中,只有在所在函數被調用時才動態地為變量分配存儲單元。
17、預處理的作用是什么?
預處理器可以刪除注釋、包含其他文件以及執行宏(宏macro是一段重復文字的簡短描寫)替代。
18、編譯器的作用?
編譯器就是將一種語言(通常為高級語言)翻譯為另一種語言(通常為低級語言)的程序。一個現代編譯器的主要工作流程:源代碼(.c)→ 預處理器(.i) → 編譯器 (.s)→ 目標代碼 (.o)→ 鏈接器 → 可執行程序 。
19、.ELF文件是什么?
.ELF是C語言在linux中的可執行文件。
20、C語言程序編譯的流程是什么?
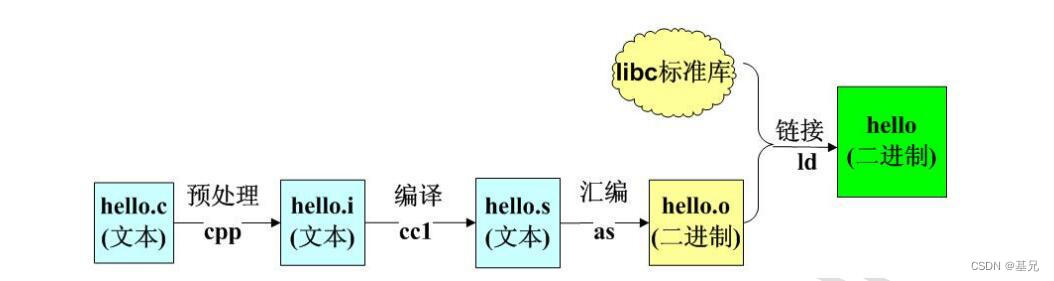
圖 編譯過程
(1)預處理:根據以字符#開頭的命令修給原始的C程序,結果得到另一個C程序,通常以.i作為文件擴展名。主要是進行文本替換、宏展開、刪除注釋這類簡單工作。
對應的命令:linux> gcc -E hello.c hello.i
(2)編譯:編譯器將文本文件hello.i翻譯成hello.s,包含相應的匯編語言程序。
對應的命令:linux> gcc -S hello.c hello.s
(3)匯編:將.s文件翻譯成機器語言指令,把這些指令打包成一種叫做可重定位目標程序的格式,并將結果保存在目標文件.o中(把匯編語言翻譯成機器語言的過程)。
把一個源程序翻譯成目標程序的工作過程分為五個階段:詞法分析;語法分析;語義檢查和中間代碼生成;代碼優化;目標代碼生成。主要是進行詞法分析和語法分析,又稱為源程序分析,分析過程中發現有語法錯誤,給出提示信息。
對應的命令:linux> gcc -c hello.c hello.o
(4)鏈接:將靜態庫和動態庫的庫函數連接到可執行程序中。靜態庫是指編譯鏈接時,把庫文件的代碼全部加入到可執行文件中,因此生成的文件比較大,但在運行時也就不再需要庫文件了。其后綴名一般為.a。動態庫與之相反,在編譯鏈接時并沒有把庫文件的代碼加入到可執行文件中,而是在程序執行時由運行時鏈接文件加載庫,這樣可以節省系統的開銷。動態庫一般后綴名為.so,gcc在編譯時默認使用動態庫。
原文鏈接:https://blog.csdn.net/daide2012/article/details/73065204
21、如何用C語言實現C++的類?
(1)由于C語言是面向過程,而C++是面向對象,所以在定義數據時,可以用C的結構體成員充當C++類的成員定義;
(2)由于結構體只能定義變量,不能夠定義函數,所以通過函數指針的方法來實現其類函數的定義。
參考鏈接:https://blog.csdn.net/forever__1234/article/details/61429870
結語
C語言是嵌入式的基礎,像我總結的這些面試題,都是去年我去面試好幾家公司所遇到的常見面試題。因此,在面試找工作的那段時間,歸納總結常遇到過的面試題,并將不會的知識點進行檢索歸納,是很必要的。這樣做的話,可以提升自己的知識面,面試時,就能從容面對不同面試官各種不同的問題。


:Decoupling maxlogit for out-of-distribution detection (2023 CVPR))


:使用 Aircrack-ng 破解 WEP 密碼)
)
)用法解析)








)


