- 學習材料:https://www.hiascend.com/developer/courses/detail/1935520434893606913
- 學習時長: 預計 30 分鐘
- 學習目的:
-
- 了解提示工程的定義與作用
-
- 熟悉提示工程的關鍵技術相關概念
-
- 掌握基于昇騰適配的大模型提示工程的入門及進階指南
提示詞工程介紹
NLP發展的四大范式
NLP(自然語言處理)發展的四大范式通常被概括為:
非神經網絡時代的完全監督學習(特征工程):這一范式主要依賴于人工設計的規則或統計模型,需要大量的人工特征工程來完成特定的NLP任務 。
基于神經網絡的完全監督學習(架構工程):隨著深度學習的發展,開始使用如RNN、CNN等神經網絡模型進行NLP任務,這一階段側重于模型架構的設計 。
預訓練+精調范式(目標工程):利用大規模語料進行預訓練,然后針對具體任務對模型進行微調(Fine-tuning)。
預訓練+提示+預測范式(Prompting):這是近期興起的一種范式,通過設計特定的提示(Prompt)來引導預訓練模型生成所需的結果,減少了對大量標注數據微調的依賴。
這些范式的演進體現了NLP技術從依賴人工規則和特征,到利用深度神經網絡,再到利用大規模預訓練模型的發展歷程。
什么是 Prompt
在大規模語言模型(LLM, Large Language Models)領域,Prompt 是一種結構化的輸入序列,用于引導預訓練的語言模型生成預期的輸出。它通常包括明確的任務要求、背景信息、格式規定以及示例,以充分利用模型的能力,在特定任務中生成高質量的響應。
Prompt 的核心作用
- 指導模型行為:通過提供清晰的任務描述和上下文,Prompt 告訴模型需要完成什么任務。
- 控制輸出質量:通過包含格式規范和示例,Prompt 可以幫助模型生成符合期望的輸出。
- 提高模型表現:Prompt 設計得當可以顯著提升模型在特定任務中的表現,尤其是在零樣本學習(Zero-Shot Learning)或少樣本學習(Few-Shot Learning)場景中。
Prompt 的組成要素
- 任務要求:明確告訴模型需要完成的任務,例如“翻譯這段文字”、“回答這個問題”等。
- 背景信息:提供與任務相關的上下文或背景知識,幫助模型更好地理解問題。
格式規定:指定輸出的格式要求,例如“請用簡短的句子回答”、“按照時間順序排列”等。 - 示例:提供一個或多個示例,展示期望的輸入和輸出格式,幫助模型理解任務的具體要求。
Prompt 的工作原理
Prompt 被輸入到大語言模型中,模型根據 Prompt 中的信息生成相應的輸出。以下是其工作流程:
- 輸入 Prompt:用戶向模型提供一個結構化的輸入序列(Prompt),其中包含任務描述、背景信息、格式要求和示例。
- 模型處理:大語言模型根據 Prompt 的內容,結合其預訓練的知識和能力,生成符合任務要求的輸出。
- 生成文本:模型輸出一段文本,作為對 Prompt 的響應。
舉例說明:
幫助小學四年級的學生寫一篇600字的人工智能介紹

Prompt 怎樣發揮作用
Prompt 的作用機制可以分為多個步驟,從輸入到最終輸出的生成過程。
- 接受輸入
- 用戶輸入 Prompt:用戶向大語言模型提供一個結構化的輸入序列(Prompt),其中包含任務描述、背景信息、格式要求和示例等。
Prompt 的內容: - 任務要求:明確告訴模型需要完成的任務,例如翻譯、問答、摘要等。
- 背景信息:提供與任務相關的上下文或背景知識,幫助模型更好地理解問題。
- 格式規定:指定輸出的格式要求,例如“請用簡短的句子回答”、“按照時間順序排列”等。
示例:提供一個或多個示例,展示期望的輸入和輸出格式,幫助模型理解任務的具體要求。
- 文本處理與編碼
- 分詞(Tokenization):將 Prompt 中的文本分解為基本單元(tokens)。這些 tokens 可能是單詞、子詞(subword)、字符或其他單位,具體取決于模型的設計。
- 編碼(Encoding):將分詞后的 tokens 轉換為模型能夠理解的數值表示(通常是向量形式)。這個過程通常使用預訓練的語言模型中的嵌入層(Embedding Layer)完成。
- 上下文窗口限制:由于大多數大語言模型具有上下文窗口限制(例如 GPT-3 的 2048 tokens 或 GPT-4 的更長上下文窗口),Prompt 的長度需要控制在模型支持的范圍內。
- 模型計算
- 輸入到模型:經過編碼的 Prompt 被輸入到大語言模型中。模型是一個深度神經網絡,通常基于 Transformer 架構。
自回歸生成:大語言模型通常是自回歸式的,這意味著它會逐個生成輸出 token。模型根據當前已生成的部分輸出和輸入的 Prompt,預測下一個最可能的 token。 - 注意力機制:Transformer 模型的核心是注意力機制(Attention Mechanism),它允許模型關注輸入序列中的不同部分,從而更好地理解和生成輸出。
概率分布:在每個時間步,模型會輸出一個概率分布,表示每個可能的 token 出現的概率。模型會選擇概率最高的 token 作為當前的輸出。
- 生成輸出
- 逐步生成:模型根據概率分布逐步生成輸出 token,直到滿足停止條件(例如達到最大長度、生成特殊結束標記等)。
- 輸出解碼:生成的 token 序列被解碼回原始文本形式,形成最終的輸出。
- 格式調整與后處理
- 格式調整:根據 Prompt 中的格式要求,對生成的輸出進行調整。例如,如果 Prompt 要求輸出為列表形式,但模型生成的是連續文本,可能需要手動分割或調整格式。
- 后處理:對輸出進行進一步的優化,例如去除重復內容、修正語法錯誤、調整語氣等。
- 質量檢查:驗證輸出是否符合任務要求,必要時可以重新調整 Prompt 或使用其他方法改進結果。
為什么需要提示詞工程
Prompt 工程(Prompt Engineering)是通過精心設計和優化 Prompt,以引導大語言模型(LLM)生成高質量、符合預期的輸出的過程
1. LLM 的黑盒特性
- LLM 是一個黑盒:盡管大語言模型經過大量數據預訓練,具有強大的語言理解和生成能力,但其內部工作機制對于用戶來說是不透明的。模型的推理過程是一個復雜的神經網絡計算過程,用戶無法直接控制或干預。
- 結果依賴于輸入:LLM 的輸出高度依賴于輸入的 Prompt。即使是同一模型,在面對不同的 Prompt 時,可能會生成截然不同的結果。
2. 提高任務完成質量
- 明確任務需求:通過精心設計 Prompt,可以更清晰地傳達任務要求,幫助模型更好地理解用戶的意圖。
- 提供上下文信息:Prompt 可以包含背景知識、示例等上下文信息,為模型提供更多的線索,從而生成更準確、更符合預期的輸出。
- 控制輸出格式:通過在 Prompt 中指定格式要求(如列表、段落、表格等),可以引導模型生成符合特定格式的輸出。
3. 實現零樣本學習與少樣本學習
- 零樣本學習(Zero-Shot Learning):在沒有額外訓練數據的情況下,通過設計合適的 Prompt,可以讓模型直接完成新任務。例如,讓模型完成從未見過的任務類型(如翻譯、問答、摘要等)。
- 少樣本學習(Few-Shot Learning):通過在 Prompt 中提供少量示例,可以顯著提升模型在新任務上的表現。這種方法避免了重新訓練模型的高昂成本,同時能夠快速適應新的應用場景。
4. 不更新模型參數即可調整行為
- 無需重新訓練:Prompt 工程的核心優勢在于,它可以在不更新模型參數的前提下,通過調整 Prompt 來改變模型的行為。這對于大規模語言模型尤為重要,因為重新訓練這些模型的成本極高(計算資源、時間、資金等)。
- 靈活性強:通過調整 Prompt,可以快速適應不同的任務需求,而無需對模型本身進行修改。
5. 改善用戶體驗
- 定制化輸出:通過優化 Prompt,可以生成更加個性化、符合用戶需求的輸出。例如,根據用戶的偏好調整語氣、風格、內容深度等。
- 減少試錯成本:精心設計的 Prompt 可以顯著提高模型的首次響應質量,減少用戶反復嘗試的次數,提升整體使用體驗。
以下是一個具體的例子,說明 Prompt 工程的重要性:
場景:生成旅行攻略
- 原始 Prompt:
我想去杭州玩,請幫我做一份攻略。

-
問題:輸出較為籠統,缺乏具體細節(如行程安排、預算、推薦景點的價格等)。
-
優化后的 Prompt:
我想去杭州玩,請綜合考慮為我做一份旅行攻略。請注意,我們從北京出發,行程5天,旅行人數3人,有一名2歲小孩,我不太喜歡行程太緊湊,希望包含吃穿住行四個方面內容,預算1萬元。推薦的景點請附上價格以及最佳訂票時間。

改進:輸出更加詳細、個性化,充分考慮了用戶的行程安排、預算限制、家庭成員情況等,提供了更具實用價值的信息。
完整回答:chat.qwen.ai/s/d13f90f2-2443-4b10-9420-33ae40e895ac?fev=0.0.166
Prompt 典型應用場景
Prompt 的典型應用場景
Prompt 是一種強大的工具,廣泛應用于自然語言處理(NLP)和圖像生成等領域。通過精心設計的 Prompt,可以引導模型完成各種復雜任務,并生成高質量的輸出
1. 自然語言處理領域
在自然語言處理領域,Prompt 主要用于指導大語言模型完成特定的語言相關任務。以下是一些典型應用場景:
(1) 文本生成
- 任務描述:根據給定的提示詞或上下文,生成符合要求的文本內容。
- 應用場景:
- 故事創作:例如,“請續寫一個關于未來世界的科幻故事,主角是一名年輕的科學家。”
- 新聞撰寫:例如,“根據以下事件摘要,撰寫一篇新聞報道:某城市發生地震,造成多人傷亡。”
- 郵件撰寫:例如,“請幫我寫一封感謝信,感謝客戶對我們的支持。”
(2) 翻譯
- 任務描述:將一種語言的文本翻譯成另一種語言。
- 應用場景:
- 多語言支持:例如,“請將這段英文翻譯成中文:The quick brown fox jumps over the lazy dog.”
- 實時翻譯:例如,在跨語言交流中,使用 Prompt 實現即時翻譯。
(3) 問答系統
- 任務描述:根據問題生成準確的答案。
- 應用場景:
- 知識檢索:例如,“請問巴黎圣母院的歷史背景是什么?”
- 客服機器人:例如,“如何更換手機號碼?”
(4) 摘要生成
- 任務描述:從長文本中提取關鍵信息,生成簡潔的摘要。
- 應用場景:
- 新聞摘要:例如,“請為以下新聞文章生成一段50字的摘要。”
- 學術論文摘要:例如,“請為這篇研究論文生成一份簡短的摘要。”
(5) 文本分類
- 任務描述:根據文本內容將其歸類到特定的類別。
- 應用場景:
- 情感分析:例如,“請判斷以下評論的情感傾向:正面、負面或中性。”
- 主題分類:例如,“請將這篇文章歸類為科技、娛樂或體育。”
(6) 代碼改寫與解釋
- 任務描述:根據代碼片段生成解釋或改寫代碼。
- 應用場景:
- 代碼解釋:例如,“請解釋以下代碼的功能:
for i in range(len(arr)): arr[i] += 1” - 代碼優化:例如,“請將這段代碼改寫為更高效的版本。”
- 代碼解釋:例如,“請解釋以下代碼的功能:
(7) 對話系統
- 任務描述:模擬人類對話,生成連貫的回復。
- 應用場景:
- 虛擬助手:例如,“你好,我想預訂一張明天去北京的機票。”
- 聊天機器人:例如,“今天天氣怎么樣?”
(8) 創意寫作
- 任務描述:根據提示生成創意性的文本內容。
- 應用場景:
- 詩歌創作:例如,“請寫一首關于秋天的五言絕句。”
- 劇本創作:例如,“請為一部電影編寫一個開頭場景。”
2. 圖像領域
在圖像生成和處理領域,Prompt 也被廣泛應用于指導模型完成特定任務。以下是一些典型應用場景:
(1) 圖像生成
- 任務描述:根據文本描述生成相應的圖像。
- 應用場景:
- 藝術創作:例如,“生成一幅描繪森林中的精靈跳舞的圖像。”
- 廣告設計:例如,“生成一張展示現代辦公室環境的圖片。”
(2) 風格轉換
- 任務描述:將圖像轉換為特定的藝術風格。
- 應用場景:
- 藝術效果:例如,“將這張照片轉換為梵高的《星夜》風格。”
- 復古效果:例如,“將這張照片添加復古濾鏡,使其看起來像老照片。”
(3) 圖像編輯
- 任務描述:根據提示修改圖像中的某些元素。
- 應用場景:
- 背景替換:例如,“將這張照片中的背景替換為海灘。”
- 人物修飾:例如,“將照片中的人物頭發顏色改為金色。”
(4) 自動標注
- 任務描述:根據圖像內容生成標簽或描述。
- 應用場景:
- 圖像分類:例如,“這張圖片的內容是什么?”
- 目標檢測:例如,“請標記出圖像中的所有行人。”
(5) 視頻生成
- 任務描述:根據文本描述生成視頻內容。
- 應用場景:
- 動畫制作:例如,“生成一段描述太空探險的動畫視頻。”
- 虛擬現實:例如,“根據用戶輸入的場景描述生成虛擬現實內容。”
3. 其他領域
除了 NLP 和圖像領域,Prompt 還可以應用于其他領域,例如:
(1) 數據分析
- 任務描述:根據數據生成報告或分析結果。
- 應用場景:
- 財務分析:例如,“根據這份財報,生成一份年度財務總結。”
- 市場調研:例如,“根據調查數據,生成一份市場趨勢分析報告。”
(2) 游戲開發
- 任務描述:生成游戲腳本、情節或角色對話。
- 應用場景:
- 劇情生成:例如,“生成一個冒險游戲的開場情節。”
- NPC 對話:例如,“為游戲角色設計一段對話。”
(3) 教育
- 任務描述:生成教學材料或練習題。
- 應用場景:
- 課程設計:例如,“根據這個主題,生成一份適合初中生的學習計劃。”
- 習題生成:例如,“生成10道關于代數的練習題。”
(4) 醫療
- 任務描述:根據醫學數據生成診斷報告或治療建議。
- 應用場景:
- 病例分析:例如,“根據患者的病歷,生成一份初步診斷報告。”
- 藥物推薦:例如,“根據患者癥狀,推薦合適的藥物。”
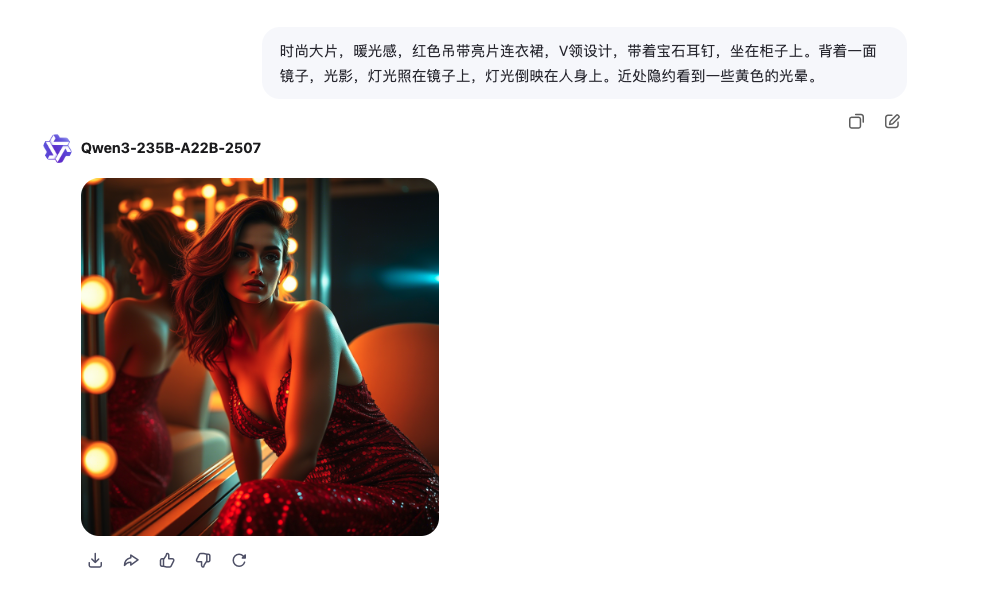
最后以一個文生圖結束今天的學習:
時尚大片,暖光感,紅色吊帶亮片連衣裙,V領設計,帶著寶石耳釘,坐在柜子上。背著一面鏡子,光影,燈光照在鏡子上,燈光倒映在人身上。近處隱約看到一些黃色的光暈。
相比,有什么優缺點?)




的MCAL配置之GtmCfg)

 ,功能全面、界面美觀)
安裝)







)
時,沒有崩潰在函數調用處,而是崩在被調用函數內部)

