紅黑樹是什么?
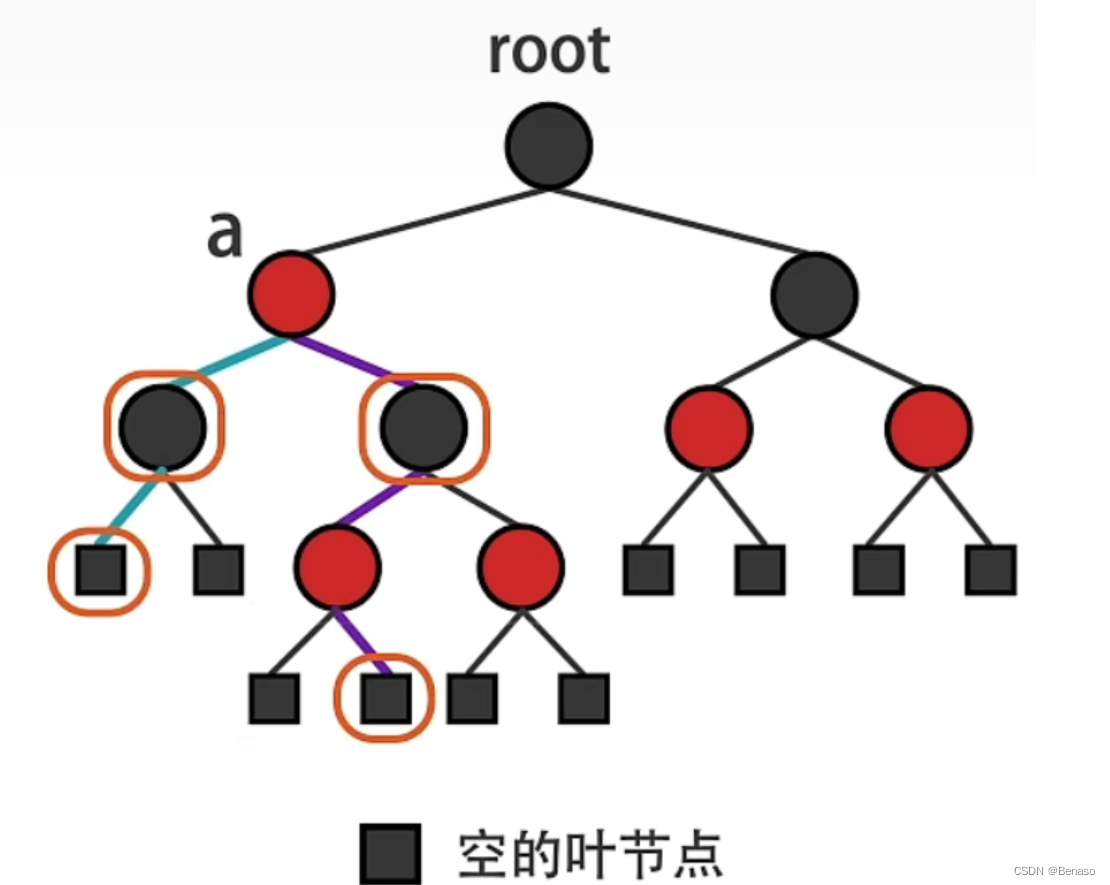
三大特點:
-
根節點是黑色,葉節點是不存儲數據的黑色空節點
-
任何相鄰的兩個節點不能同時為紅色
-
任意節點到其可到達的節點間包含相同數量的黑色節點
聯想:Java HashMap底層紅黑樹原理
HashMap基于哈希表Map接口實現,是以key-value存儲形式存在,即主要用于存儲鍵值對。
HashMap特點:
-
存取無序
-
鍵和值位置都可以為null,但是鍵的位置為null只能有一個
-
鍵位置是唯一的,底層數據結構控制鍵
哈希沖突:
定義:兩個對象調用的hashCode方法計算的哈希碼值一致導致計算機的數組索引值相同
HashMap底層數據結構
JDK1.8之前,HashMap是由數組+鏈表組成的,數組是HashMap主體,鏈表用來解決哈希沖突。即,發生hash沖突后使用equals判斷是否相等,相等則存儲在該節點的鏈表中。
JDK1.8之后,當鏈表長度大于閾值(或者紅黑樹的邊界值,默認為8),并且當前數組長度大于64時,此時索引位置上的所有數據改為紅黑樹存儲。
創建對象底層原理:
HashMap<String,Integer> map = new HashMap<>();
-
當創建HashMap集合對象時,
-
在JDK8前,構造方法中創建一個長度是16的Entry[] table 用來存儲鍵值對數據的
-
在JDK8后,不是在HashMap的構造方法底層創建數組了,而是在第一次使用put方法時,創建的數組,Node[] table用來存儲鍵值對數據的
-
-
存儲數據數組位置為空時:
-
比如將一個鍵值對 (“Benaso” ,1) 存儲到哈希表中,根據 “Benaso” 調用 String 類中重寫之后的hashCode() 方法計算出值,然后結合數組的長度采用某種算法算出向Node數組中存儲數據的空間值索引,如果該索引對應空間沒有數據,則將 (“Benaso” ,1) 存儲到數組中
-
面試題:哈希表底層采用何種算法計算hash值?還有哪些算法可以計算出hash值?
-
底層采用key的hashCode方法的值結合數組長度進行無符號右移(>>>)、按位異或(^),按位與(&)計算出索引。(異或:兩個二進制值相同為0,不同為1)
-
還可以采用平方取中法,取余數,偽隨機數法
-
哈希表采用方法原因是與其他方法相比該方法效率高
-
-
-
存儲數據數組位置不為空時:
-
例如向hash表新存一組數據(“Victor” ,1),假設根據Victor計算出的hashCode方法結合數組長度計算出的索引值也是3,那么此時數組空間不是null,此時則會比較Victor的hash值是否一致,如果不一致,則在此空間上劃出一個節點來存儲鍵值對數據 (“Victor” ,1)。——這種方法被稱為拉鏈法
-
-
假設向哈希表中存儲數據 (“Benaso” ,2) 那么根據Benaso調用hashCode方法結合數組長度計算出索引也為3,此時對比較后存儲的數據Benaso和已經存在的Benaso的hash值是否相等,如果相等,發生hash碰撞:
-
相等:則將后添加的數據的value覆蓋到其上
-
不相等:那么繼續向下和其它數據的key進行比較,如果都不相等,則劃出一個節點存儲數據。
-
-
一般不會等到存儲數據到達16才擴容,
threshold(臨界值)= capacity(容量) * loadFactor(加載因子)
這個值是當前已占用數組長度的最大值,size超過這個臨界值就重新resize(擴容),擴容后的 HashMap 容量是之前容量的兩倍。
HashMap集合類的成員
成員變量
集合的初始化容量(必須是二的n次冪)
//默認初始容量是16 -- 1<<4相當于1*2的4次方 --- 1*16 static final int DEFAULT_INITAL_CAPACITY = 1 << 4
HashMap擴容
擴容條件
-
元素個數超過12擴容,
-
鏈表節點大于8,數組長度小于64
擴容后索引要么是原索引,要么是原索引加16
-
計算新的索引高位是0那么存儲到原來索引位置
-
如果高位是1那么存儲到原來索引加舊的數組的長度




)









)




(三))