Flink 系列文章
1、Flink 部署、概念介紹、source、transformation、sink使用示例、四大基石介紹和示例等系列綜合文章鏈接
13、Flink 的table api與sql的基本概念、通用api介紹及入門示例
14、Flink 的table api與sql之數據類型: 內置數據類型以及它們的屬性
15、Flink 的table api與sql之流式概念-詳解的介紹了動態表、時間屬性配置(如何處理更新結果)、時態表、流上的join、流上的確定性以及查詢配置
16、Flink 的table api與sql之連接外部系統: 讀寫外部系統的連接器和格式以及FileSystem示例(1)
16、Flink 的table api與sql之連接外部系統: 讀寫外部系統的連接器和格式以及Elasticsearch示例(2)
16、Flink 的table api與sql之連接外部系統: 讀寫外部系統的連接器和格式以及Apache Kafka示例(3)
16、Flink 的table api與sql之連接外部系統: 讀寫外部系統的連接器和格式以及JDBC示例(4)
16、Flink 的table api與sql之連接外部系統: 讀寫外部系統的連接器和格式以及Apache Hive示例(6)
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
18、Flink的SQL 支持的操作和語法
19、Flink 的Table API 和 SQL 中的內置函數及示例(1)
19、Flink 的Table API 和 SQL 中的自定義函數及示例(2)
19、Flink 的Table API 和 SQL 中的自定義函數及示例(3)
19、Flink 的Table API 和 SQL 中的自定義函數及示例(4)
20、Flink SQL之SQL Client: 不用編寫代碼就可以嘗試 Flink SQL,可以直接提交 SQL 任務到集群上
21、Flink 的table API與DataStream API 集成(1)- 介紹及入門示例、集成說明
21、Flink 的table API與DataStream API 集成(2)- 批處理模式和inser-only流處理
21、Flink 的table API與DataStream API 集成(3)- changelog流處理、管道示例、類型轉換和老版本轉換示例
21、Flink 的table API與DataStream API 集成(完整版)
22、Flink 的table api與sql之創建表的DDL
24、Flink 的table api與sql之Catalogs(介紹、類型、java api和sql實現ddl、java api和sql操作catalog)-1
24、Flink 的table api與sql之Catalogs(java api操作數據庫、表)-2
24、Flink 的table api與sql之Catalogs(java api操作視圖)-3
24、Flink 的table api與sql之Catalogs(java api操作分區與函數)-4
25、Flink 的table api與sql之函數(自定義函數示例)
26、Flink 的SQL之概覽與入門示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介紹及詳細示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介紹及詳細示例(2)
27、Flink 的SQL之SELECT (窗口函數)介紹及詳細示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介紹及詳細示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分組聚合、Over Aggregation Over聚合 和 Window Join 窗口關聯)介紹及詳細示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介紹及詳細示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式檢測)介紹及詳細示例(7)
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 語句
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客戶端(通過kafka和filesystem的例子介紹了配置文件使用-表、視圖等)
31、Flink的SQL Gateway介紹及示例
32、Flink table api和SQL 之用戶自定義 Sources & Sinks實現及詳細示例
33、Flink 的Table API 和 SQL 中的時區
35、Flink 的 Formats 之CSV 和 JSON Format
36、Flink 的 Formats 之Parquet 和 Orc Format
41、Flink之Hive 方言介紹及詳細示例
40、Flink 的Apache Kafka connector(kafka source的介紹及使用示例)-1
40、Flink 的Apache Kafka connector(kafka sink的介紹及使用示例)-2
40、Flink 的Apache Kafka connector(kafka source 和sink 說明及使用示例) 完整版
42、Flink 的table api與sql之Hive Catalog
43、Flink之Hive 讀寫及詳細驗證示例
44、Flink之module模塊介紹及使用示例和Flink SQL使用hive內置函數及自定義函數詳細示例–網上有些說法好像是錯誤的
文章目錄
- Flink 系列文章
- 一、Apache Kafka 連接器
- 3、kafka sourcefunction
- 4、kafka sink
- 1)、使用示例
- 1、Flink 1.13版本實現
- 2、Flink 1.17版本實現
- 3、說明
- 2)、序列化器
- 3)、容錯
- 4)、監控
- 5、kafka producer
- 6、kafka 連接器指標
- 7、啟用 Kerberos 身份驗證
- 8、升級到最近的連接器版本
- 9、問題排查
- 1)、數據丟失
- 2)、UnknownTopicOrPartitionException
- 3)、ProducerFencedException
本文介紹了kafka的版本功能更能換、作為sink的使用、連接器的指標、身份認證、版本升級和問題排查幾個主要 方面,關于常用的功能均以可運行的示例進行展示并提供完整的驗證步驟。
本專題為了便于閱讀以及整體查閱分為三個部分:
40、Flink 的Apache Kafka connector(kafka source的介紹及使用示例)-1
40、Flink 的Apache Kafka connector(kafka sink的介紹及使用示例)-2
40、Flink 的Apache Kafka connector(kafka source 和sink 說明及使用示例) 完整版
本文依賴kafka集群能正常使用。
本文分為9個部分,即sink、producer/source(Flink版本升級)、連接器指標、身份認證、版本升級及問題排查。
本文的示例是在Flink 1.17版本中運行。
一、Apache Kafka 連接器
Flink 提供了 Apache Kafka 連接器使用精確一次(Exactly-once)的語義在 Kafka topic 中讀取和寫入數據。
3、kafka sourcefunction
FlinkKafkaConsumer 已被棄用并將在 Flink 1.17 中移除,請改用 KafkaSource。
1.13版本的實現參考本文開頭的示例。
4、kafka sink
KafkaSink 可將數據流寫入一個或多個 Kafka topic。
1)、使用示例
Kafka sink 提供了構建類來創建 KafkaSink 的實例。
以下代碼片段展示了如何將字符串數據按照至少一次(at lease once)的語義保證寫入 Kafka topic:
1、Flink 1.13版本實現
- 實現代碼
import java.util.Properties;
import java.util.Random;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;/*** @author alanchan**/
public class TestKafkaSinkDemo {public static void test1() throws Exception {// 1、envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2、source-主題:alan_source// 準備kafka連接參數Properties propSource = new Properties();propSource.setProperty("bootstrap.servers", "192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092");// 集群地址propSource.setProperty("group.id", "flink_kafka");propSource.setProperty("auto.offset.reset", "latest");propSource.setProperty("flink.partition-discovery.interval-millis", "5000");propSource.setProperty("enable.auto.commit", "true");// 自動提交的時間間隔propSource.setProperty("auto.commit.interval.ms", "2000");FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("alan_source", new SimpleStringSchema(), propSource);// 使用kafkaSourceDataStream<String> kafkaDS = env.addSource(kafkaSource);// 3、transformation-統計單詞個數SingleOutputStreamOperator<String> result = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {private Random ran = new Random();@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {String[] arr = value.split(",");for (String word : arr) {out.collect(Tuple2.of(word, 1));}}}).keyBy(t -> t.f0).sum(1).map(new MapFunction<Tuple2<String, Integer>, String>() {@Overridepublic String map(Tuple2<String, Integer> value) throws Exception {System.out.println("輸出:" + value.f0 + "->" + value.f1);return value.f0 + "->" + value.f1;}});// 4、sink-主題alan_sinkProperties propSink = new Properties();propSink.setProperty("bootstrap.servers", "192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092");propSink.setProperty("transaction.timeout.ms", "5000");FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("alan_sink", new KeyedSerializationSchemaWrapper(new SimpleStringSchema()), propSink,FlinkKafkaProducer.Semantic.EXACTLY_ONCE); // fault-toleranceresult.addSink(kafkaSink);// 5、executeenv.execute();}public static void main(String[] args) throws Exception {test1();}}
- 驗證
1、創建kafka 主題 alan_source 和 alan_sink
2、驅動程序,觀察運行控制臺
3、通過命令往alan_source 寫入數據,同時消費 alan_sink 主題的數據
## kafka生產數據
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_source
>alan,alach,alanchan,hello
>alan_chan,hi,flink
>alan,flink,good
>alan,alach,alanchan,hello
>hello,123
>## kafka消費數據
[alanchan@server2 bin]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic alan_sink --from-beginning
alanchan->1
hello->1
alan->1
alach->1
flink->1
alan_chan->1
hi->1
alan->2
flink->2
good->1
alanchan->2
hello->2
alan->3
alach->2
hello->3
123->14、應用程序控制臺輸出
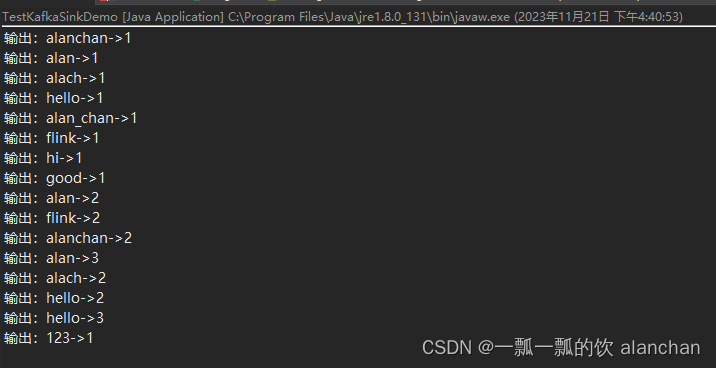
2、Flink 1.17版本實現
- 代碼實現
import java.util.Properties;
import java.util.Random;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;/*** @author alanchan**/
public class TestKafkaSinkDemo {public static void test2() throws Exception {// 1、envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2、 sourceKafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092").setTopics("alan_nsource").setGroupId("flink_kafka").setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStream<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");// 3、 transformationDataStream<String> result = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {String[] arr = value.split(",");for (String word : arr) {out.collect(Tuple2.of(word, 1));}}}).keyBy(t -> t.f0).sum(1).map(new MapFunction<Tuple2<String, Integer>, String>() {@Overridepublic String map(Tuple2<String, Integer> value) throws Exception {System.out.println("輸出:" + value.f0 + "->" + value.f1);return value.f0 + "->" + value.f1;}});// 4、 sinkKafkaSink<String> kafkaSink = KafkaSink.<String>builder().setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092").setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic("alan_nsink").setValueSerializationSchema(new SimpleStringSchema()).build()).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();result.sinkTo(kafkaSink);// 5、executeenv.execute();}public static void main(String[] args) throws Exception {
// test1();test2();}}- 驗證
1、創建kafka 主題 alan_nsource 和 alan_nsink
2、驅動程序,觀察運行控制臺
3、通過命令往alan_nsource 寫入數據,同時消費 alan_nsink 主題的數據
## kafka生產數據
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_nsource
>alan,alach,alanchan,hello
>alan_chan,hi,flink
>alan,flink,good
>alan,alach,alanchan,hello
>hello,123
>## kafka消費數據
[alanchan@server2 bin]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic alan_nsink --from-beginning
alanchan->1
hello->1
alan->1
alach->1
flink->1
alan_chan->1
hi->1
alan->2
flink->2
good->1
alanchan->2
alach->2
alan->3
hello->2
hello->3
123->14、應用程序控制臺輸出
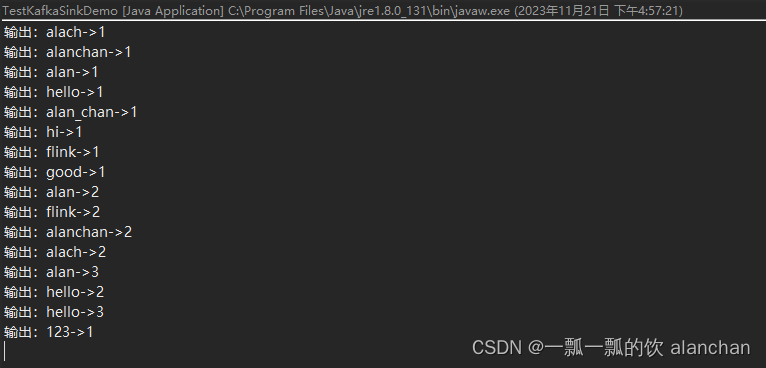
3、說明
以下屬性在構建 KafkaSink 時是必須指定的:
- Bootstrap servers, setBootstrapServers(String)
- 消息序列化器(Serializer), setRecordSerializer(KafkaRecordSerializationSchema)
- 如果使用DeliveryGuarantee.EXACTLY_ONCE 的語義保證,則需要使用 setTransactionalIdPrefix(String)
2)、序列化器
構建時需要提供 KafkaRecordSerializationSchema 來將輸入數據轉換為 Kafka 的 ProducerRecord。Flink 提供了 schema 構建器 以提供一些通用的組件,例如消息鍵(key)/消息體(value)序列化、topic 選擇、消息分區,同樣也可以通過實現對應的接口來進行更豐富的控制。
KafkaRecordSerializationSchema.builder().setTopicSelector(new TopicSelector() {@Overridepublic String apply(Object t) {//設置選擇的 topic return "alan_nsink";}}).setValueSerializationSchema(new SimpleStringSchema()).setKeySerializationSchema(new SimpleStringSchema()).setPartitioner(new FlinkFixedPartitioner()).build()
- 示例代碼
import java.util.Properties;
import java.util.Random;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.sink.TopicSelector;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;/*** @author alanchan**/
public class TestKafkaSinkDemo {public static void test3() throws Exception {// 1、envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2、 sourceKafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092").setTopics("alan_nsource").setGroupId("flink_kafka").setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStream<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");// 3、 transformationDataStream<String> result = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {String[] arr = value.split(",");for (String word : arr) {out.collect(Tuple2.of(word, 1));}}}).keyBy(t -> t.f0).sum(1).map(new MapFunction<Tuple2<String, Integer>, String>() {@Overridepublic String map(Tuple2<String, Integer> value) throws Exception {System.out.println("輸出:" + value.f0 + "->" + value.f1);return value.f0 + "->" + value.f1;}});// 4、 sinkKafkaSink<String> kafkaSink = KafkaSink.<String>builder().setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092").setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopicSelector(new TopicSelector() {@Overridepublic String apply(Object t) {//設置選擇的 topic return "alan_nsink";}}).setValueSerializationSchema(new SimpleStringSchema()).setKeySerializationSchema(new SimpleStringSchema()).setPartitioner(new FlinkFixedPartitioner()).build()).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();result.sinkTo(kafkaSink);// 5、executeenv.execute();}public static void main(String[] args) throws Exception {test3();}}- 驗證
1、創建kafka 主題 alan_nsource 和 alan_nsink
2、驅動程序,觀察運行控制臺
3、通過命令往alan_nsource 寫入數據,同時消費 alan_nsink 主題的數據
## kafka生產數據
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_nsource
>alan,alach,alanchan,hello
>alan_chan,hi,flink
>alan,flink,good
>alan,alach,alanchan,hello
>hello,123
>## kafka消費數據
[alanchan@server2 bin]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic alan_nsink --from-beginning
alanchan->1
hello->1
alan->1
alach->1
flink->1
alan_chan->1
hi->1
alan->2
flink->2
good->1
alanchan->2
alach->2
alan->3
hello->2
hello->3
123->14、應用程序控制臺輸出
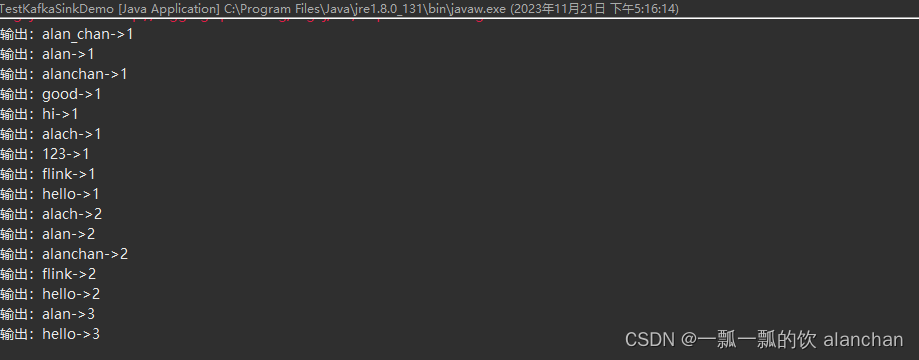
其中消息體(value)序列化方法和 topic 的選擇方法是必須指定的,此外也可以通過 setKafkaKeySerializer(Serializer) 或 setKafkaValueSerializer(Serializer) 來使用 Kafka 提供而非 Flink 提供的序列化器。
3)、容錯
KafkaSink 總共支持三種不同的語義保證(DeliveryGuarantee)。對于 DeliveryGuarantee.AT_LEAST_ONCE 和 DeliveryGuarantee.EXACTLY_ONCE,Flink checkpoint 必須啟用。
默認情況下 KafkaSink 使用 DeliveryGuarantee.NONE。
以下是對不同語義保證的解釋:
- DeliveryGuarantee.NONE 不提供任何保證:消息有可能會因 Kafka broker 的原因發生丟失或因 Flink 的故障發生重復。
- DeliveryGuarantee.AT_LEAST_ONCE: sink 在 checkpoint 時會等待 Kafka 緩沖區中的數據全部被 Kafka producer 確認。消息不會因 Kafka broker 端發生的事件而丟失,但可能會在 Flink 重啟時重復,因為 Flink 會重新處理舊數據。
- DeliveryGuarantee.EXACTLY_ONCE: 該模式下,Kafka sink 會將所有數據通過在 checkpoint 時提交的事務寫入。因此,如果 consumer 只讀取已提交的數據(參見 Kafka consumer 配置 isolation.level),在 Flink 發生重啟時不會發生數據重復。然而這會使數據在 checkpoint 完成時才會可見,因此請按需調整 checkpoint 的間隔。請確認事務 ID 的前綴(transactionIdPrefix)對不同的應用是唯一的,以保證不同作業的事務 不會互相影響!此外,強烈建議將 Kafka 的事務超時時間調整至遠大于 checkpoint 最大間隔 + 最大重啟時間,否則 Kafka 對未提交事務的過期處理會導致數據丟失。
關于容錯,請參考文章:9、Flink四大基石之Checkpoint容錯機制詳解及示例(checkpoint配置、重啟策略、手動恢復checkpoint和savepoint)
4)、監控
Kafka sink 會在不同的范圍(Scope)中匯報下列指標。

5、kafka producer
FlinkKafkaProducer 已被棄用并將在 Flink 1.15 中移除,請改用 KafkaSink。
關于Flink 1.13版本的實現,請參考上文中的示例。
6、kafka 連接器指標
Flink 的 Kafka 連接器通過 Flink 的指標系統提供一些指標來幫助分析 connector 的行為。 各個版本的 Kafka producer 和 consumer 會通過 Flink 的指標系統匯報 Kafka 內部的指標。 該 Kafka 文檔列出了所有匯報的指標。
同樣也可通過將 Kafka source 在該章節描述的 register.consumer.metrics,或 Kafka sink 的 register.producer.metrics 配置設置為 false 來關閉 Kafka 指標的注冊。
7、啟用 Kerberos 身份驗證
Flink 通過 Kafka 連接器提供了一流的支持,可以對 Kerberos 配置的 Kafka 安裝進行身份驗證。只需在 flink-conf.yaml 中配置 Flink。
像這樣為 Kafka 啟用 Kerberos 身份驗證:
1、通過設置以下內容配置 Kerberos 票據
- security.kerberos.login.use-ticket-cache:默認情況下,這個值是 true,Flink 將嘗試在 kinit 管理的票據緩存中使用 Kerberos 票據。注意!在 YARN 上部署的 Flink jobs 中使用 Kafka 連接器時,使用票據緩存的 Kerberos 授權將不起作用。
- security.kerberos.login.keytab 和 security.kerberos.login.principal:要使用 Kerberos keytabs,需為這兩個屬性設置值。
2、將 KafkaClient 追加到 security.kerberos.login.contexts:這告訴 Flink 將配置的 Kerberos 票據提供給 Kafka 登錄上下文以用于 Kafka 身份驗證。
一旦啟用了基于 Kerberos 的 Flink 安全性后,只需在提供的屬性配置中包含以下兩個設置(通過傳遞給內部 Kafka 客戶端),即可使用 Flink Kafka Consumer 或 Producer 向 Kafk a進行身份驗證:
- 將 security.protocol 設置為 SASL_PLAINTEXT(默認為 NONE):用于與 Kafka broker 進行通信的協議。使用獨立 Flink 部署時,也可以使用 SASL_SSL;請在此處查看如何為 SSL 配置 Kafka 客戶端。
- 將 sasl.kerberos.service.name 設置為 kafka(默認為 kafka):此值應與用于 Kafka broker 配置的 sasl.kerberos.service.name 相匹配。客戶端和服務器配置之間的服務名稱不匹配將導致身份驗證失敗。
有關 Kerberos 安全性 Flink 配置的更多信息,請參見這里。你也可以在這里進一步了解 Flink 如何在內部設置基于 kerberos 的安全性。
該部分由于沒有環境,未做驗證,內容來至于官網。將來擬計劃以專欄的形式介紹該部分內容。
8、升級到最近的連接器版本
通用的升級步驟概述見 升級 Jobs 和 Flink 版本指南。對于 Kafka,你還需要遵循這些步驟:
- 不要同時升級 Flink 和 Kafka 連接器
- 確保你對 Consumer 設置了 group.id
- 在 Consumer 上設置 setCommitOffsetsOnCheckpoints(true),以便讀 offset 提交到 Kafka。務必在停止和恢復 savepoint 前執行此操作。你可能需要在舊的連接器版本上進行停止/重啟循環來啟用此設置。
- 在 Consumer 上設置 setStartFromGroupOffsets(true),以便我們從 Kafka 獲取讀 offset。這只會在 Flink 狀態中沒有讀 offset 時生效,這也是為什么下一步非要重要的原因。
- 修改 source/sink 分配到的 uid。這會確保新的 source/sink 不會從舊的 sink/source 算子中讀取狀態。
- 使用 --allow-non-restored-state 參數啟動新 job,因為我們在 savepoint 中仍然有先前連接器版本的狀態。
9、問題排查
如果在使用 Flink 時對 Kafka 有問題,Flink 只封裝 KafkaConsumer 或 KafkaProducer,你的問題可能獨立于 Flink,有時可以通過升級 Kafka broker 程序、重新配置 Kafka broker 程序或在 Flink 中重新配置 KafkaConsumer 或 KafkaProducer 來解決。
一句話,大概是kafka的問題或配置的kafka的問題,和flink關系不大。
下面列出了一些常見問題的示例。
1)、數據丟失
根據你的 Kafka 配置,即使在 Kafka 確認寫入后,你仍然可能會遇到數據丟失。特別要記住在 Kafka 的配置中設置以下屬性:
- acks
- log.flush.interval.messages
- log.flush.interval.ms
- log.flush.*
上述選項的默認值是很容易導致數據丟失的。請參考 Kafka 文檔以獲得更多的解釋。
2)、UnknownTopicOrPartitionException
導致此錯誤的一個可能原因是正在進行新的 leader 選舉,例如在重新啟動 Kafka broker 之后或期間。這是一個可重試的異常,因此 Flink job 應該能夠重啟并恢復正常運行。也可以通過更改 producer 設置中的 retries 屬性來規避。但是,這可能會導致重新排序消息,反過來可以通過將 max.in.flight.requests.per.connection 設置為 1 來避免不需要的消息。
3)、ProducerFencedException
這個錯誤是由于 FlinkKafkaProducer 所生成的 transactional.id 與其他應用所使用的的產生了沖突。多數情況下,由于 FlinkKafkaProducer 產生的 ID 都是以 taskName + “-” + operatorUid 為前綴的,這些產生沖突的應用也是使用了相同 Job Graph 的 Flink Job。 我們可以使用 setTransactionalIdPrefix() 方法來覆蓋默認的行為,為每個不同的 Job 分配不同的 transactional.id 前綴來解決這個問題。
以上,本文介紹了kafka的版本功能更能換、作為sink的使用、連接器的指標、身份認證、版本升級和問題排查幾個主要 方面,關于常用的功能均以可運行的示例進行展示并提供完整的驗證步驟。
本專題為了便于閱讀以及整體查閱分為三個部分:
40、Flink 的Apache Kafka connector(kafka source的介紹及使用示例)-1
40、Flink 的Apache Kafka connector(kafka sink的介紹及使用示例)-2
40、Flink 的Apache Kafka connector(kafka source 和sink 說明及使用示例) 完整版


)


】紅黑樹深度剖析--手撕紅黑樹!)








)


...)

