一、項目概述
本項目致力于構建一個結合 n8n 工作流引擎 與 通義千問大模型 的智能體,旨在對龐大的業務數據庫進行自動化分析、語義建模及自然語言問答。通過不同工作流的迭代構建,實現了表結構解析、業務含義提取、關系可視化、問答服務等能力,推動企業數據資產可視化與智能化升級。
二、工作流開發進度
| 日期 | 工作流名稱 | 功能簡介 |
|---|---|---|
| 2025/4/24 | A1分析數據庫表作用_V1.0_示例數據庫Demo | 使用示例數據庫驗證分析流程 |
| 2025/5/12 | A1針對數據庫表問答V0.1 | 初步實現結構化問答功能 |
| 2025/5/13 | A1分析數據庫表作用_V1.0_全量數據庫 | 支持 333 張真實業務表的全量分析 |
| 2025/5/15 | A1針對數據庫表問答V0.2_引入知識庫 | 引入知識庫加速問答分析 |
三、操作步驟記錄
? 1. 示例數據庫分析
-
運行
A1分析數據庫表作用_V1.0_示例數據庫Demo -
驗證數據合并、分析、文件保存節點功能是否正常
? 2. 全量數據庫處理
-
運行
A1分析數據庫表作用_V1.0_全量數據庫 -
加載 333 張業務表,處理字段、關系、樣例數據等結構信息
-
合并后送入通義千問模型進行作用分析
? 3. 數據合并與輸出
-
使用數據合并節點,整合結構與樣例數據為統一格式
-
智能體節點對合并數據進行作用分析,輸出語義結果
-
保存輸出至
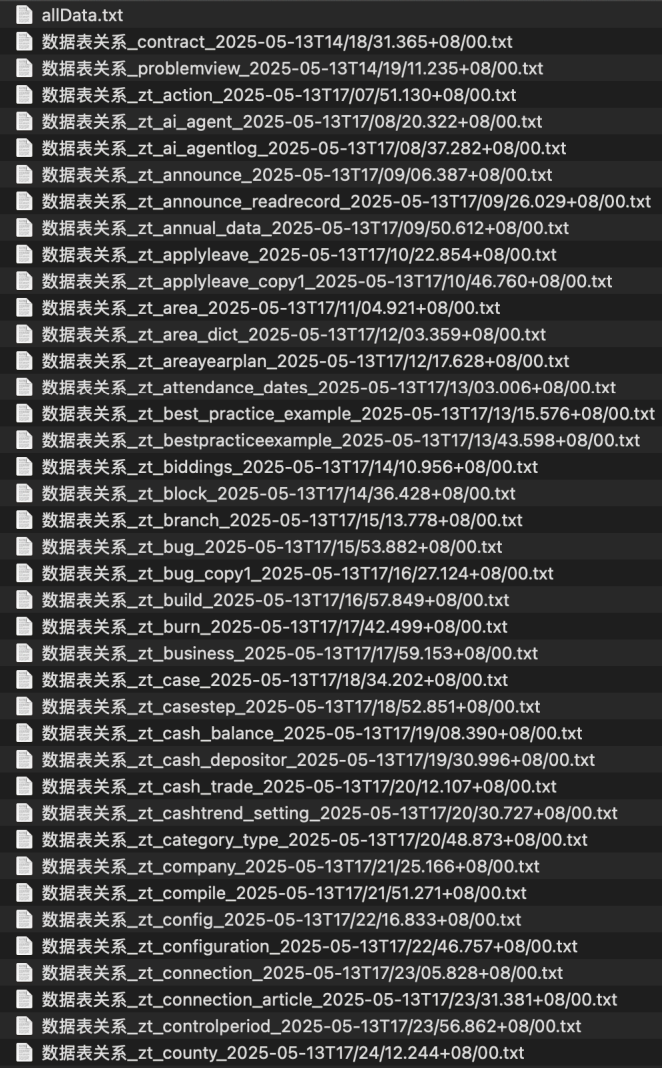
allData.txt及多個教程表關系_*.txt文件中,示例路徑:/documents/AIBrain_test/now.txt
? 4. 自然語言問答功能
-
V0.1版本:直接將所有表格分析結果輸入模型,響應慢
-
V0.2版本:引入知識庫,先檢索相關表,再送入模型分析,大幅提升效率
四、關鍵技術要點
-
模型上下文管理:V0.1 中上下文過長,導致 token 消耗大,V0.2 引入知識庫緩存顯著優化響應速度;
-
節點模塊配置:智能體節點配置部分存在疑似 OCR 識別錯誤,如“elim”,可能為某內部模塊或配置點;
-
文件輸出規范化:自動生成的關系文件命名不一致,存在
zt_action、zt_al agent等重復或錯誤命名,后續需清洗合并; -
視覺輸出待補充:表關系圖譜與結構語義圖仍在測試階段,尚未形成完整可視化組件。
五、當前問題與待優化項
| 問題/風險 | 優化方向 |
|---|---|
| 工作流 inactive,尚未上線 | 模型接口打通后激活主流程 |
| 表結構合并邏輯未完全驗證 | 增加異常數據兼容測試 |
| 文件命名混亂 | 引入命名規則和清洗腳本 |
| 智能體節點配置未明 | 明確“elim”等關鍵詞實際作用 |
| 結果 token 消耗大 | 精簡表分析結果內容,控制上下文長度 |
六、下一步計劃
-
? 2025/5/27:完成
A1分析數據庫表作用_V1.0_全量數據庫流程測試 -
🔄 集成阿里百煉平臺的應用發布能力,發布開放應用
-
🔄 整理輸出文件結構,建立統一命名與歸檔機制
-
🔄 推出基于結構化+非結構化內容的資產分析 Beta 服務
七、補充備注
-
當前版本為開發迭代日志記錄,用于后續項目總結與團隊協作參考;
-
所有流程運行截圖與輸出文件保存在
/documents/AIBrain_test/; -
項目命名統一使用
A1_前綴便于管理與溯源。
八、操作步驟
工作流
主要搭建了4個工作流
操作步驟
- 運行『AI分析數據庫表作用_V1.0_示例數據庫Demo』,調試流程
運行效果見全量運行的截圖。
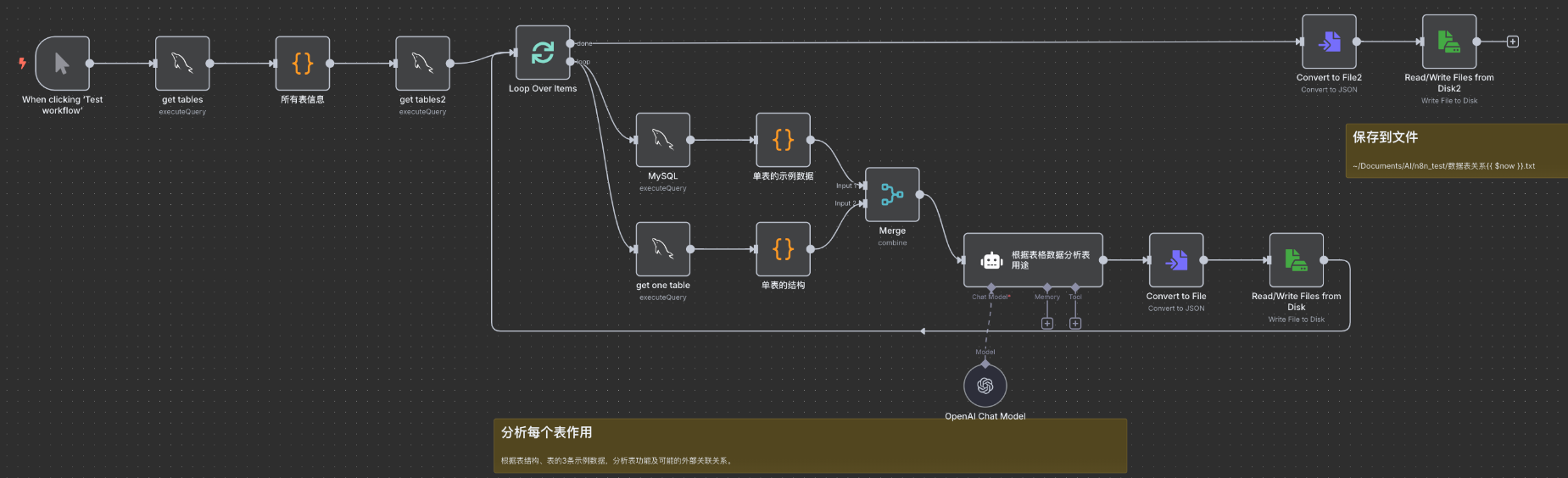
- 運行『AI分析數據庫表作用_V1.0_全量數據庫』,分析真實的業務數據庫,包含333張表。
運行效果圖
-
數據合并節點,將表的結構和數據合并到一起
-
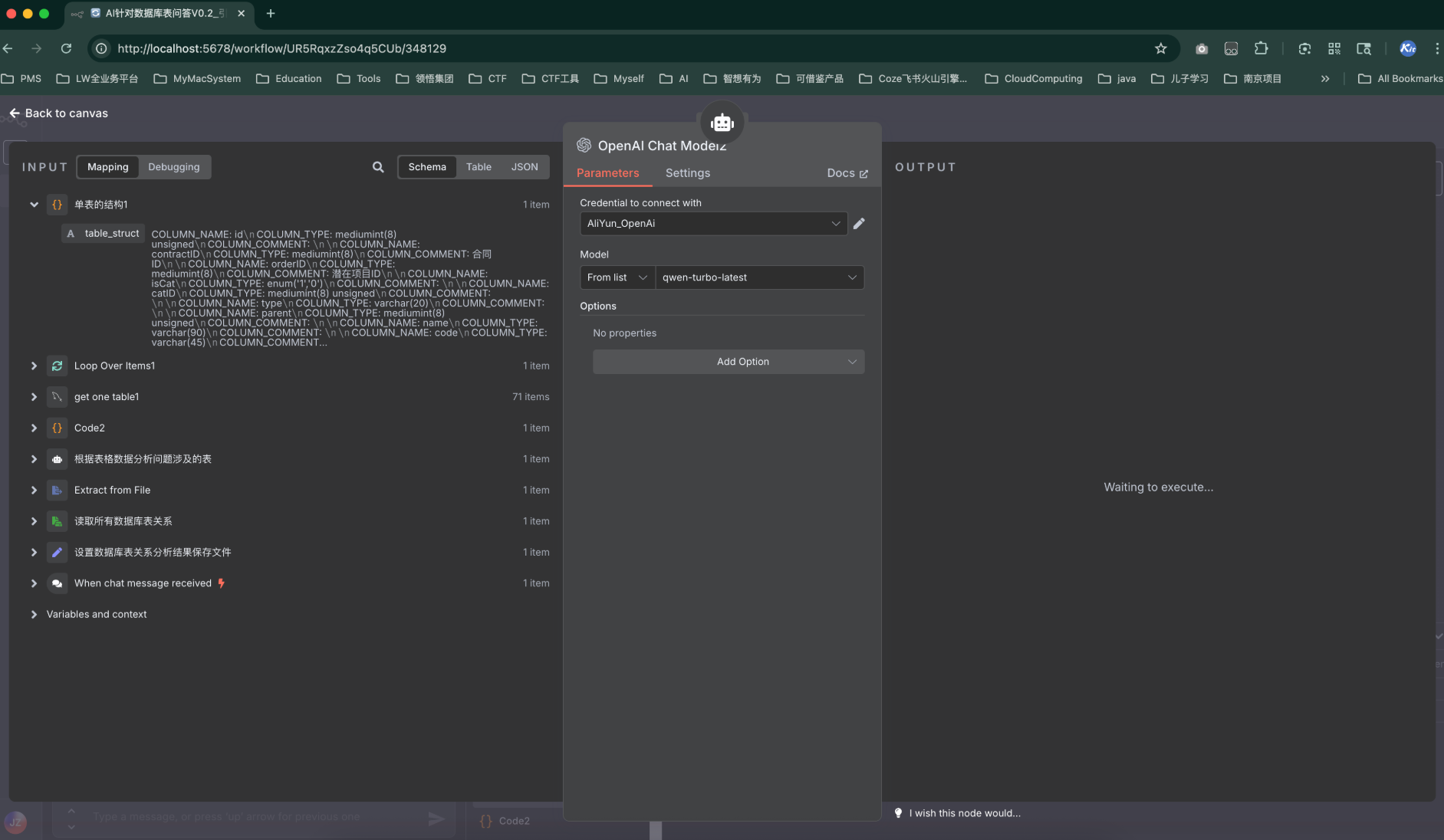
模型配置
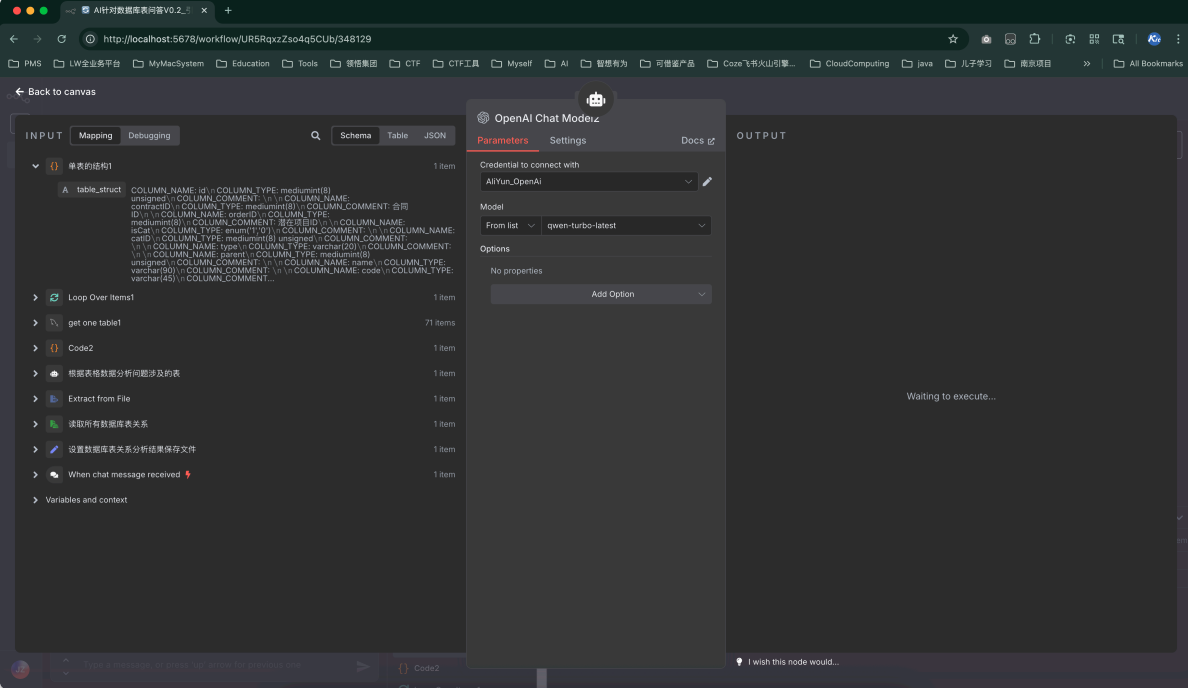
-
智能體節點對上一步合并的數據進行分析
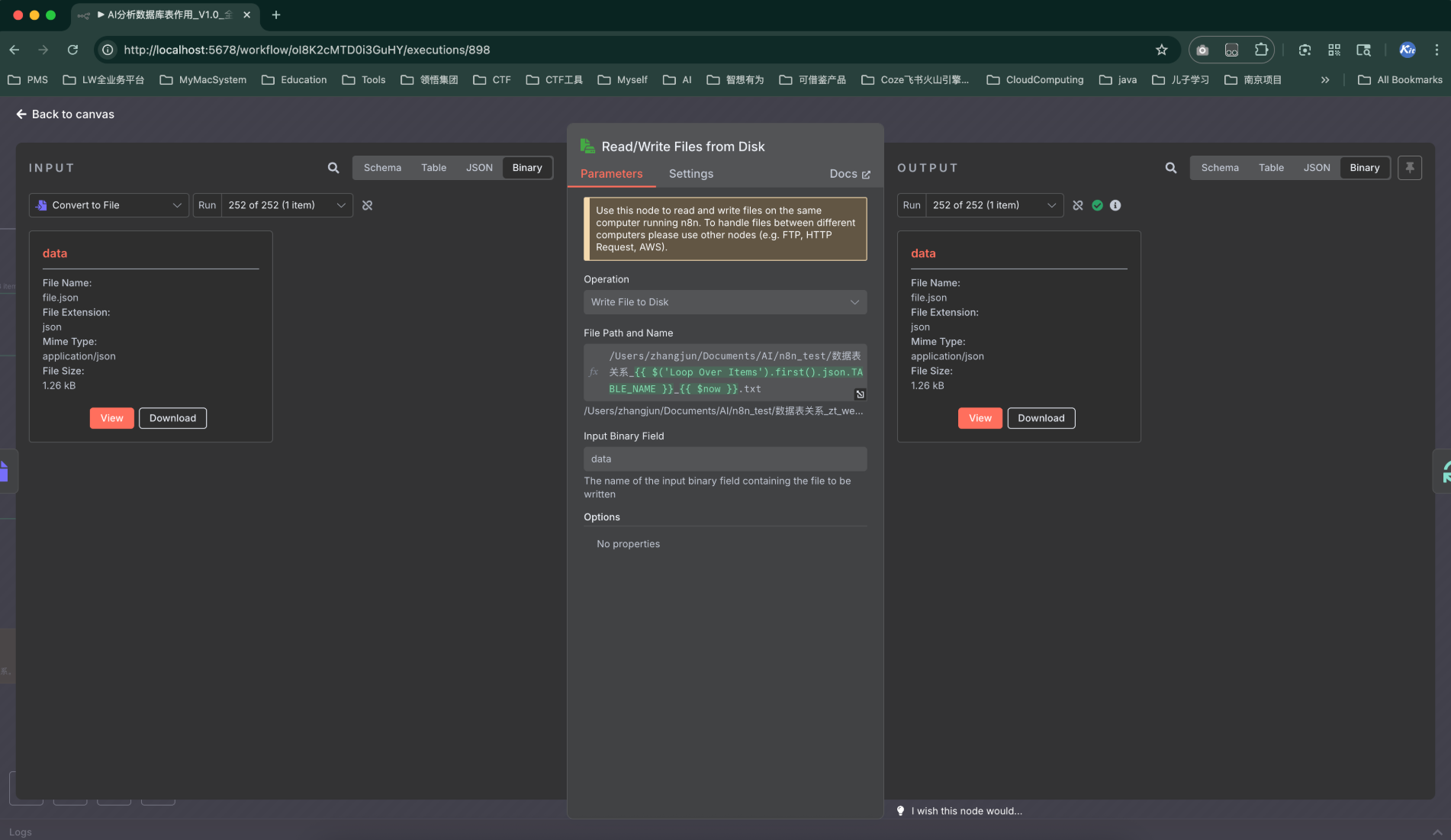
-
將結果保存到文件
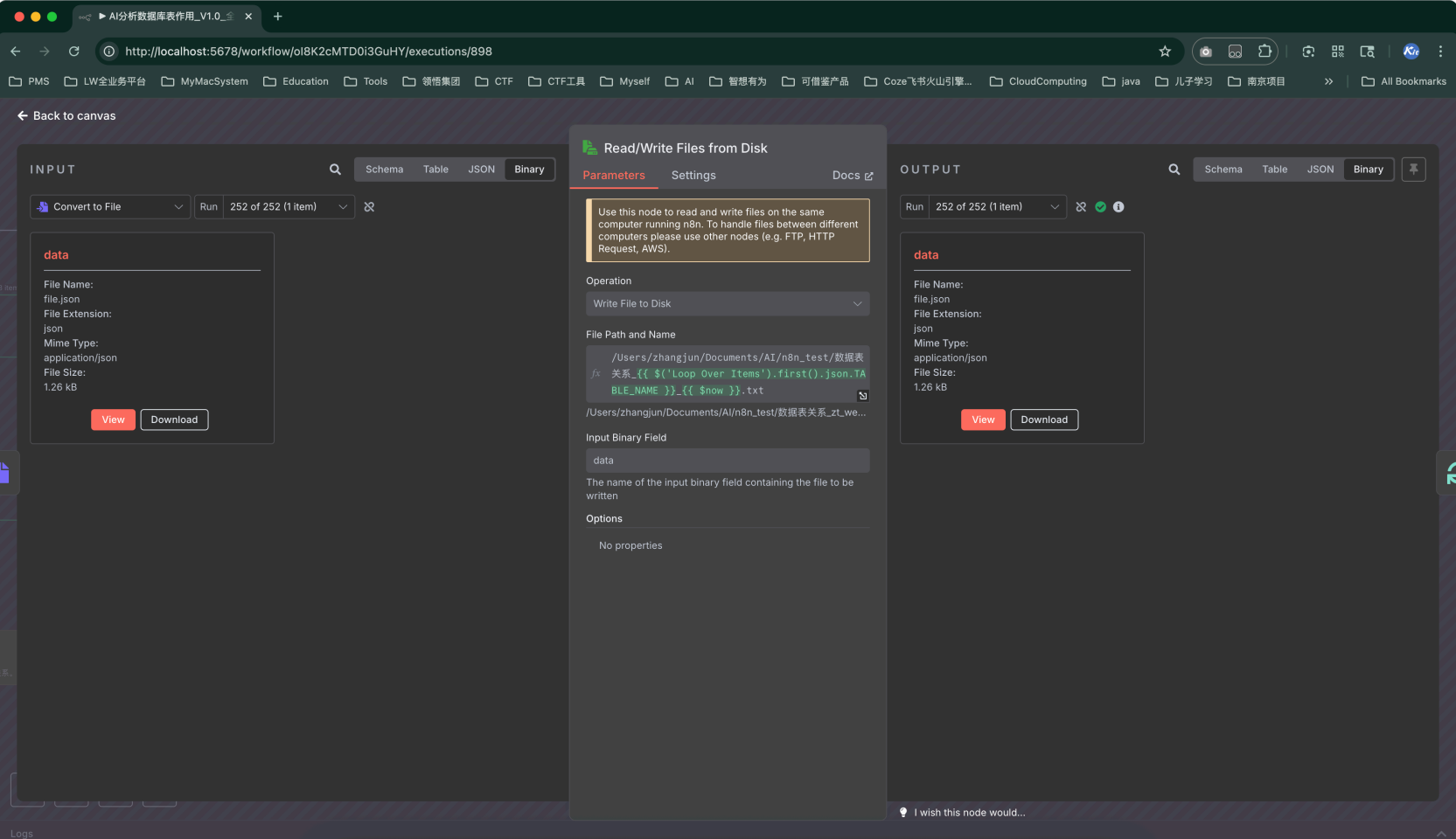
-
表關系分析結果
- 運行『AI針對數據庫表問答V0.1』,測試問答效果。
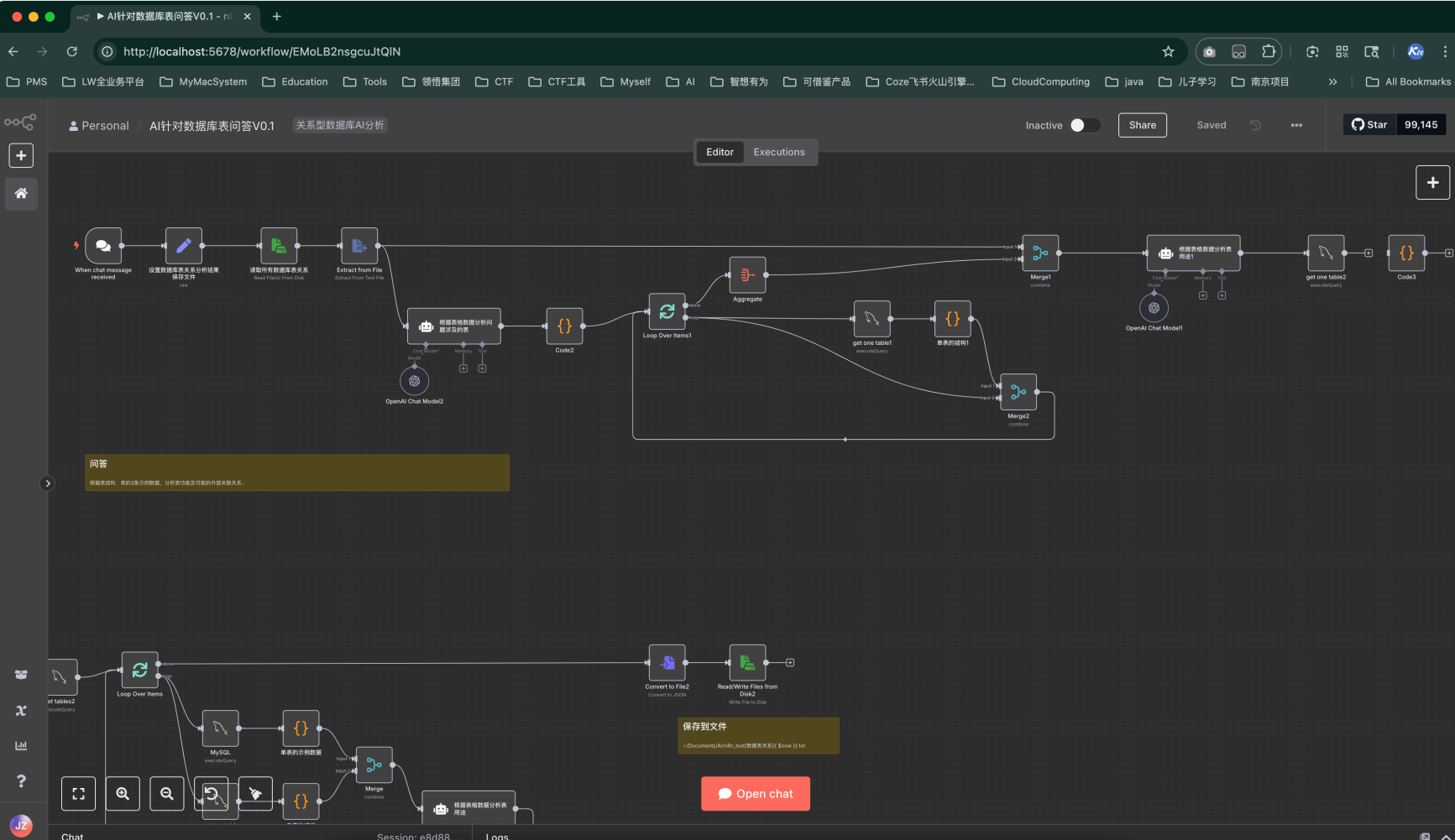
-
模型配置為max,上下文比較長
-
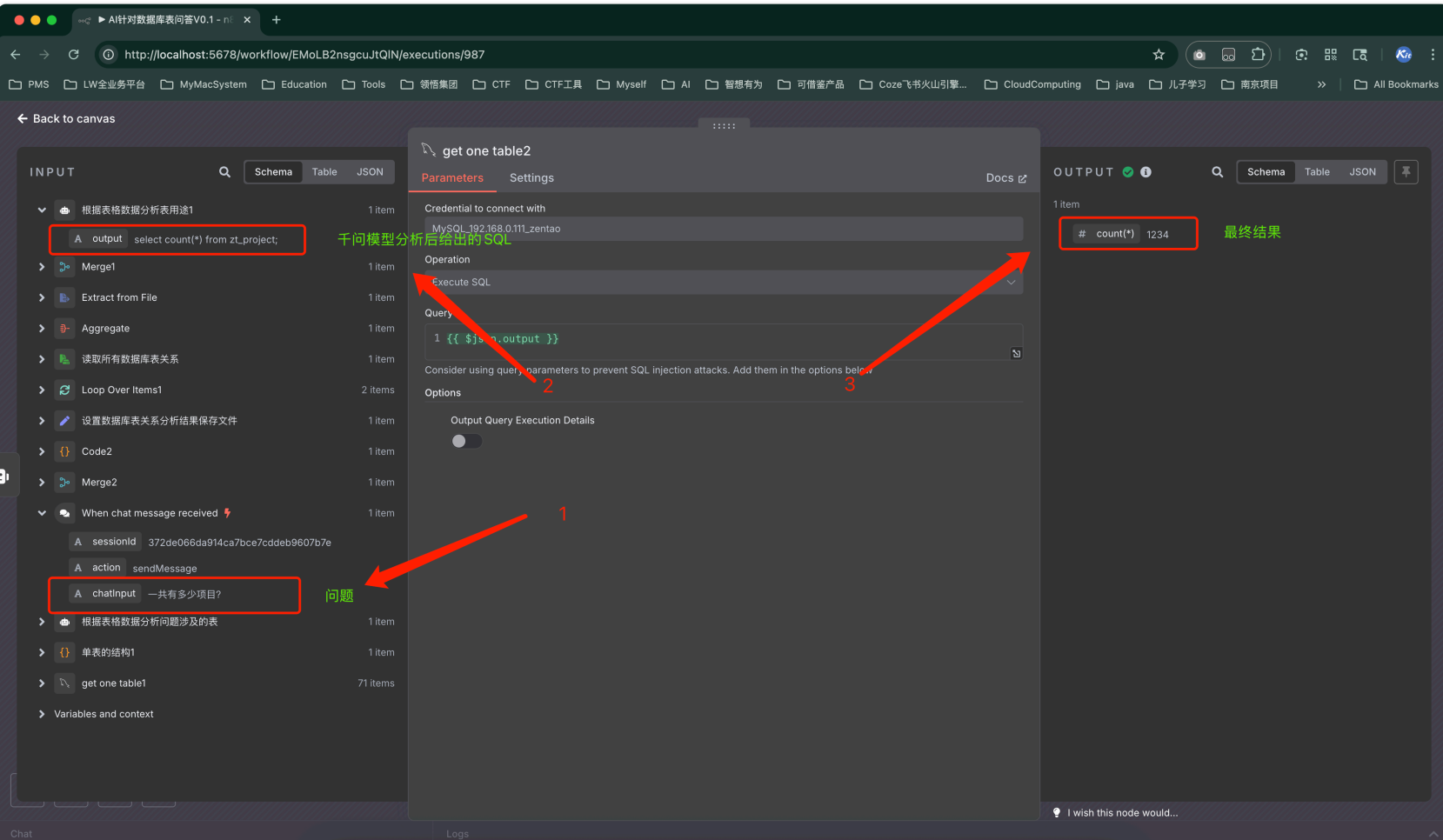
測驗問題:一共有多少項目?
-
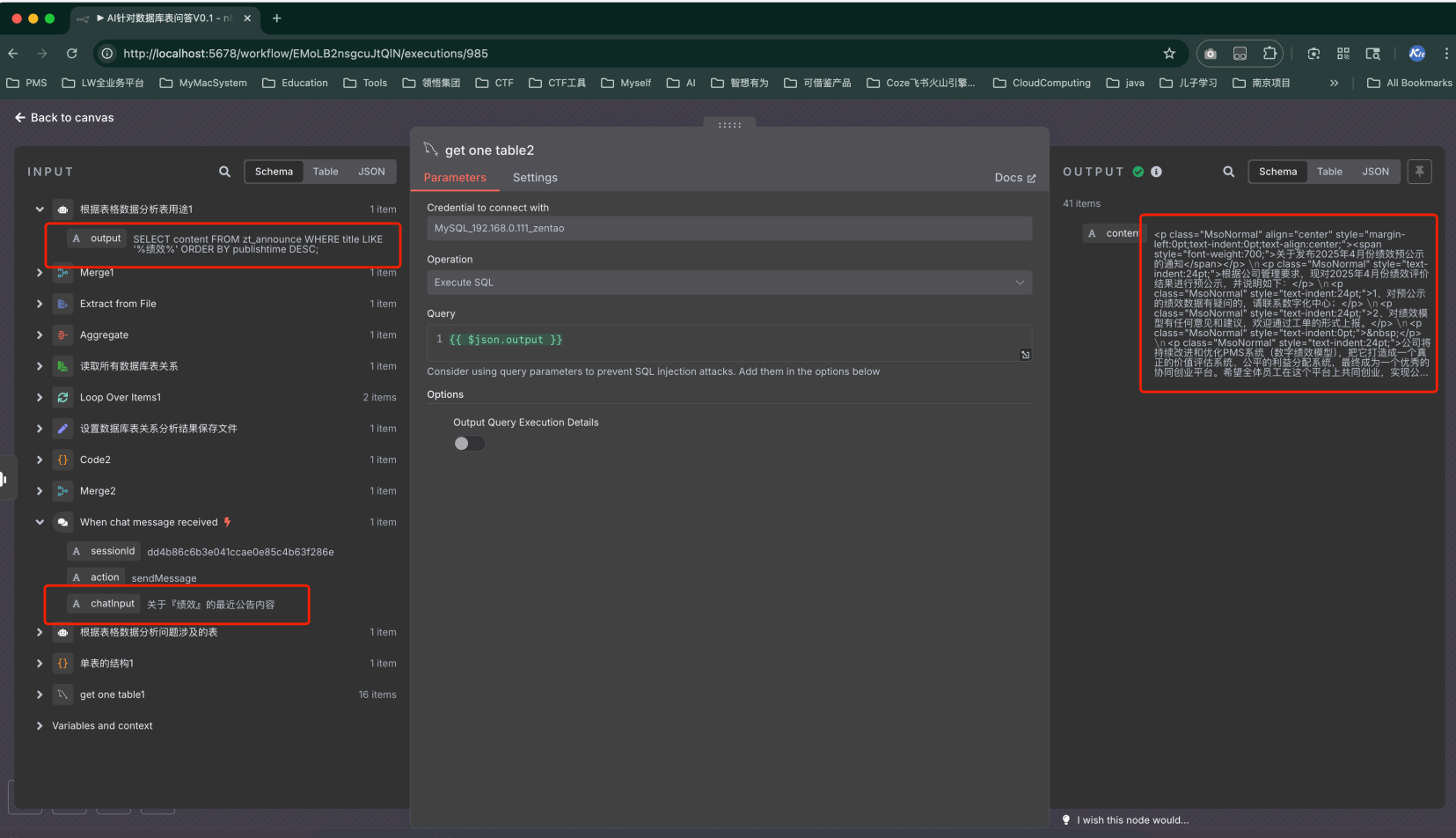
測驗問題:關于『績效』的最新公告內容
-
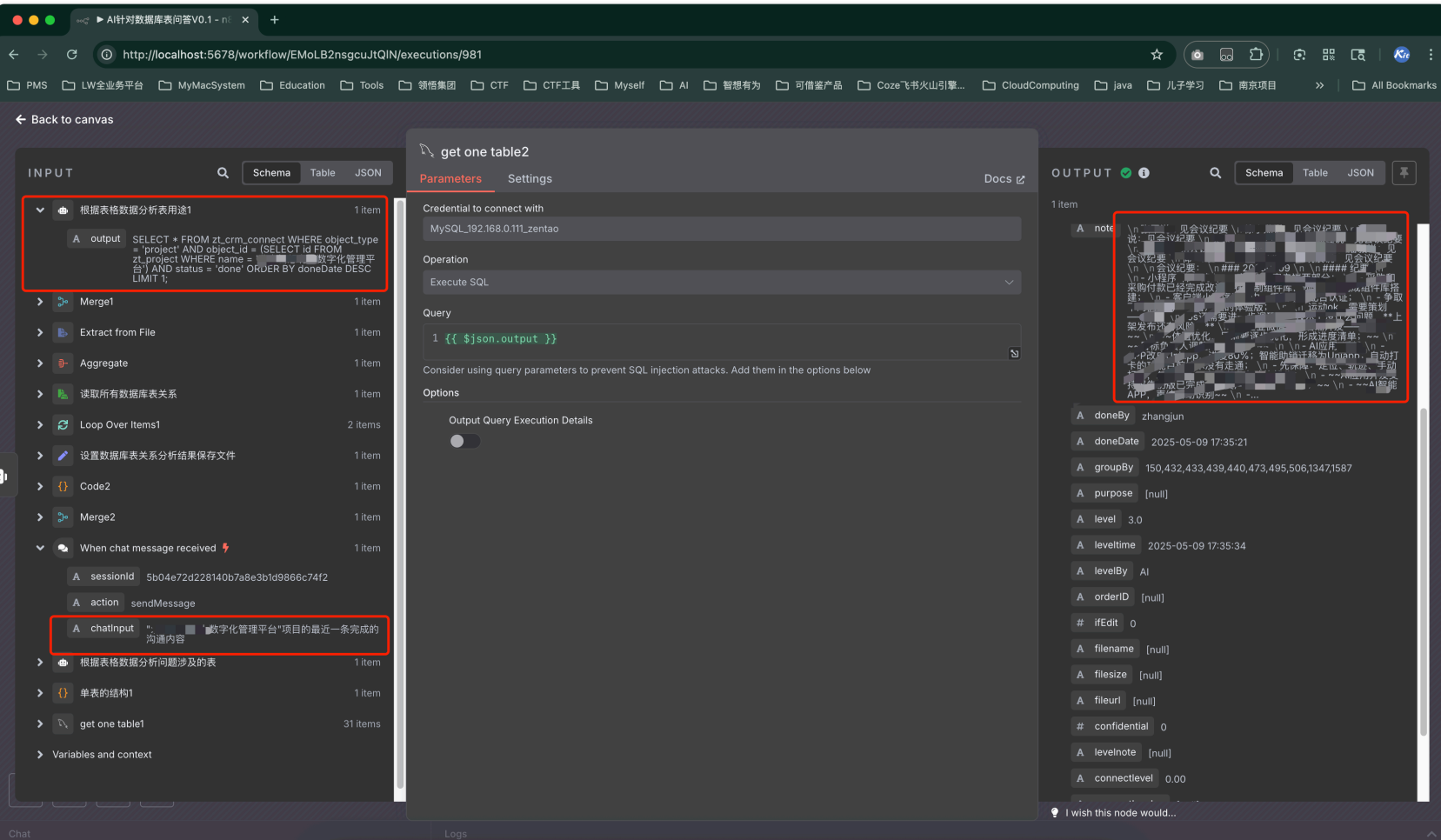
測驗問題:** 項目最近一條完成的溝通內容
- 運行『AI針對數據庫表問答V0.2_引入知識庫』
- 前面流程直接把所有333張表的分析結果都給了通義,結果token很長,模型分析就比較慢,后面把表格分析結果保存到知識庫,然后根據問題分析關聯表,接下來從知識庫檢索相關表結構,把結果給到模型進行分析,效率高了很多。
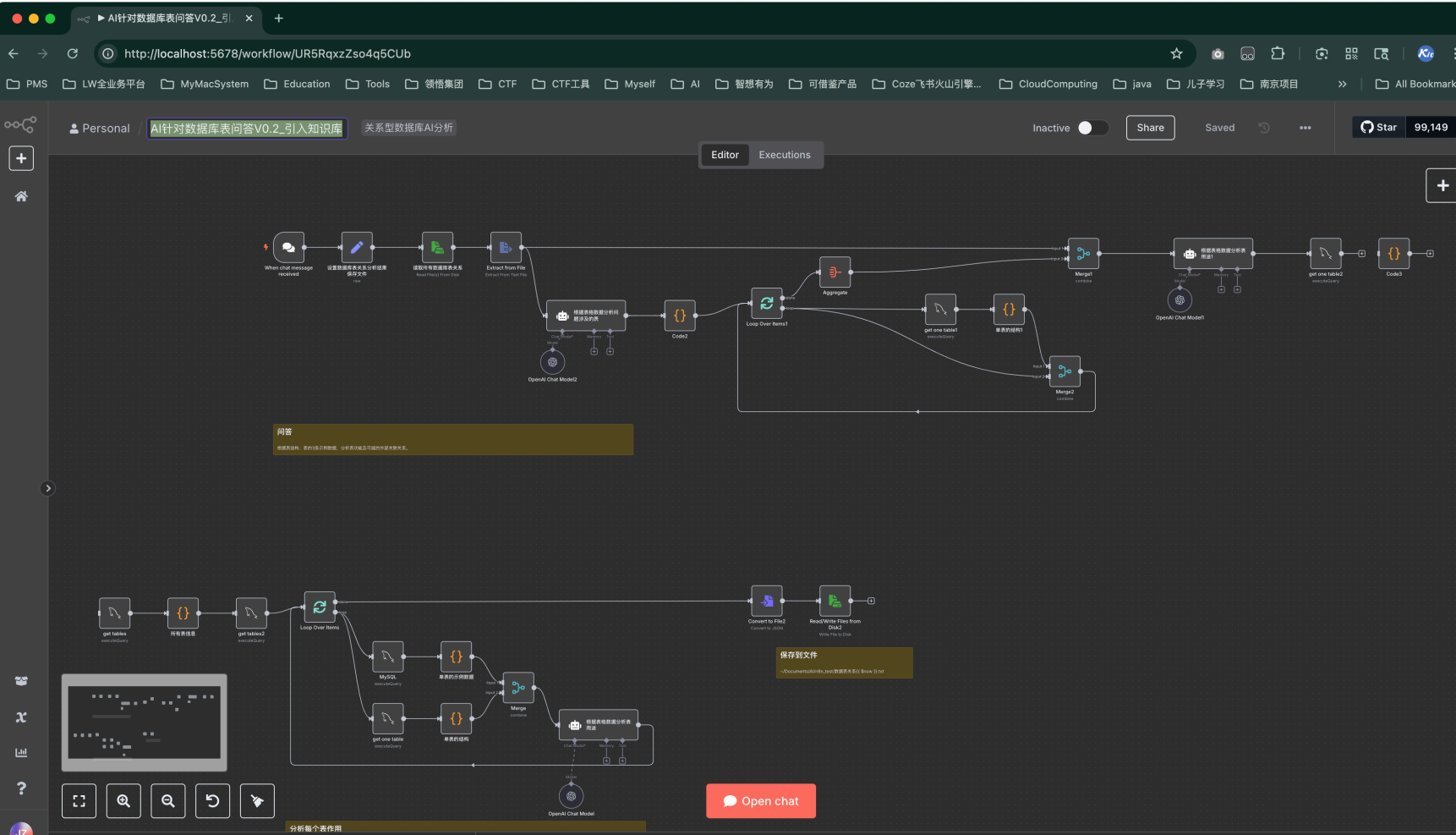
后續優化點:
對相似問題可以緩存
對業務數據的分析結果可以再精簡,降低token消耗
發布流程,與阿里百煉的應用結合,發布公開應用
結合非結構化數據的分析,可以提供數據資產梳理服務





(含中國電力年鑒))












)
