關系數據庫管理系統( RDBMS ) 代表了最先進的技術,這在一定程度上要歸功于其由周邊技術、工具和廣泛的專業技能組成的完善的生態系統。
在這個涵蓋信息技術(IT) 和運營技術(OT) 的技術革命時代,人們普遍認識到性能方面出現了重大挑戰,特別是在NoSQL 解決方案優于傳統方法的特定用例中。事實上,市場提供了許多解釋和利用各種不同數據模型的NoSQL DBMS解決方案:
-
鍵值存儲(例如,最簡單的存儲,其中對持久數據的訪問必須是即時的,并且通過像哈希映射或字典這樣的鍵進行檢索);
-
面向文檔(例如,在無服務器解決方案和 lambda 函數架構中廣泛采用,其中客戶端需要直接從數據庫獲取結構良好的 DTO);
-
面向圖的(例如,對于知識管理、語義網或社交網絡有用);
-
面向列(例如,在查詢驅動的建模方法中提供高度優化的“即用型”數據投影);
-
時間序列(例如,用于處理物聯網場景中的傳感器和樣本數據);
-
多模型存儲(例如,組合不同類型的數據模型以實現混合功能目的)。
“與那些完全不使用數據的人相比,使用不充分的數據時出現錯誤要少得多。”?
一個較少被研究的問題是依賴于關系解決方案的軟件架構能夠靈活地適應軟件領域和功能需求快速而頻繁的變化。類似敏捷的軟件開發方法加劇了這一挑戰,這些方法旨在滿足客戶處理由其業務市場主導的不斷出現的需求。
特別是,RDBMS 就其本質而言,當軟件需求隨著時間的推移而變化時,可能會受到影響,通過引入新的關聯表(也替換預先存在的外鍵)并在 SQL 查詢中生成新的 JOIN 子句,對數據庫表格模式產生快速影響,從而導致更復雜且更難維護的解決方案。
根據我們的企業經驗,我們已經成功實施并試驗了基于Neo4j 圖形數據庫的面向圖形的 DBMS 解決方案,以便在具有不同用戶和角色的數字社交社區的典型操作環境中減輕需求變更的架構后果。
在這篇文章中,我們:
-
舉例說明面向圖形的 DBMS 如何更能滿足功能需求;
-
討論在經典的N層(分層)架構中采用面向圖的DBMS的可行性,提出一些克服主要困難的方法;
-
強調在各種環境和用例中采用它們的優點和缺點以及威脅。
Neo4j 圖形數據庫
面向圖的數據模型背后的思想是采用原生方法來處理實體(即節點)及其背后的關系(即邊),以便通過導航實體之間的關系來查詢知識庫(即知識 圖)。
Neo4j 圖形數據庫適用 于面向屬性圖,其中節點和邊都擁有不同類型的屬性屬性。
我們選擇它作為 DBMS,主要是為了:
-
它的“本機”實現是通過數字圖元模型具體建模的,其運行時實例由節點(包含具有域屬性的實體)和邊(表示互連概念之間的可導航關系)組成。這樣,關系的遍歷時間為O(1);
-
Cypher查詢語言被采用為圖形中持久知識的非常強大且直觀的查詢系統。
此外,Neo4j 圖形數據庫還提供用于對象圖形映射(OGM) 的Java 庫,可幫助開發人員實現映射、持久化和管理模型實體、節點和關系的自動化過程。實際上,OGM 對于面向圖形的 DBMS 的解釋與對象關系映射( ORM )模式對于關系持久層的作用相同。
與為 RDBMS 設計的 ORM 模式相比,OGM 模式用于簡化數據訪問對象( DAO )的實現。它的主要功能是在源代碼中正確配置和注釋的持久域模型實體中啟用半自動細化。
相對于被廣泛認為是領先的 ORM 技術的Java Persistence API ( JPA )/Hibernate,Neo4j的 OGM 庫以獨特的方式運行:
寫操作
-
OGM 在托管實體的所有關系中傳播持久性更改(從托管對象開始分析整個對象關系樹);
-
JPA從托管實體開始逐表執行更新,并基于級聯配置處理關系。
讀操作
-
OGM通過查詢檢索一整棵具有固定深度的“關系樹”,從指定節點開始,充當“樹的根”;
-
JPA允許配置EAGER和LAZY加載方法之間的關系。
示例性案例研究的解決方案優勢
為了舉例說明我們分析的意義,我們引入一個簡單的操作場景:圖 1.1 中的 UML 類圖描述了一個與實體 Auth(授權的縮寫)具有 1 對 N 關系的 User 實體,該實體定義了應用程序內的權限和授權。這種領域模型可以通過類似于表 1.1 和表 1.2 的架構在關系型數據庫管理系統(RDBMS)中支持,或者在面向圖形的數據庫管理系統中,如圖 1.2 中的知識圖所示。
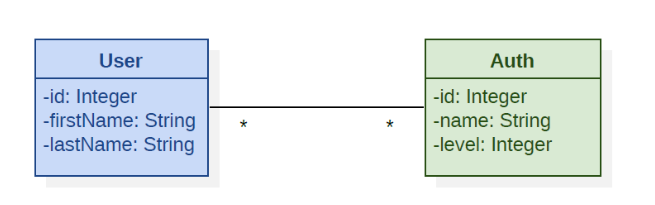
圖 1.1:領域模型的 UML 類圖。
| USERS TABLE | ||
|---|---|---|
| id | firstName | lastName |
| ... | ... | ... |
表 1.1:在 RDBMS 架構中為 User 實體映射的表格。
| AUTHS TABLE | |||
|---|---|---|---|
| id | name | level | user_fk |
| ... | ... | ... | ... |
表 1.2:在 RDBMS 架構中為 Auth 實體映射的表格。
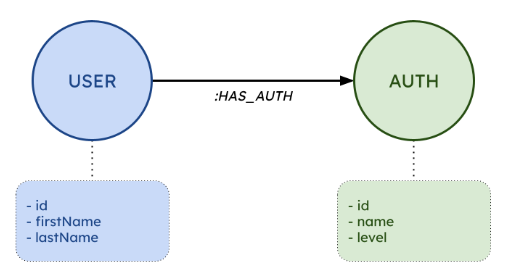
圖1.2:與圖1.1 的領域模型相關的知識圖 。
現在,想象一下,在應用程序的生產生命周期期間出現了一個新的需求:出于管理原因,客戶需要將授權限定在特定時間段內(即有效期的開始和結束日期),如圖 2.1 所示,將 User 和 Auth 之間的關系轉變為 N 對 N。這種領域模型可以通過類似于表 2.1 的架構在關系型數據庫管理系統(RDBMS)中支持,或者在面向圖形的數據庫管理系統中,如圖 2.2 中的知識圖所示。

圖 2.1:在定義新要求后的領域模型 UML 類圖。
| USERS TABLE | ||
|---|---|---|
| id | firstName | lastName |
| ... | ... | ... |
表 2.1:在 RDBMS 架構中為 User 實體映射的表格。
| USERS_AUTHS TABLE | |||
|---|---|---|---|
| user_fk | auth_fk | from | until |
| ... | ... | ... | ... |
表 2.2:在 RDBMS 架構中用于存儲 User 和 Auth 實體之間關聯的表格。
| AUTHS TABLE | ||
|---|---|---|
| id | name | level |
| ... | ... | ... |
表 2.3:在 RDBMS 架構中為 Auth 實體映射的表格。

圖 2.2:與圖 2.1 領域模型相關的知識圖。
在架構層面上的優勢已經很明顯:實際上,面向圖形的方法沒有改變架構,只是在邊緣(建模關系)上定義了兩個新屬性,而 RDBMS 方法則創建了新的關聯表 users_auths,替代了 auths 表中引用用戶表的外鍵。
進一步深入分析,我們可以嘗試分析 SQL 查詢和用 Cypher 查詢語言語法編寫的查詢在這兩種方法下的區別:我們想要識別名為“Paul”的用戶,他們擁有名為“admin”的 Auth,并且級別大于或等于 3。
一方面,在 SQL 中,所需的查詢(分別是第一個查詢用于從表 1.1 和表 1.2 檢索數據,第二個查詢用于表 2.1、表 2.2 和表 2.3)是:
SELECT users.*FROM usersINNER JOIN auths ON users.id = auths.user_fkWHERE users.firstName = 'Paul' AND auths.name = 'admin' AND auths.level >= 3
SELECT users.*FROM usersINNER JOIN users_auths ON users.id = users_auths.user_fkINNER JOIN auths ON auths.id = users_auths.auth_fkWHERE users.firstName = 'Paul' AND auths.name = 'admin' AND auths.level >= 3
另一方面,在Cypher 查詢語言中,所需的查詢(對于這兩種情況) 是:
MATCH (u:User)-[:HAS_AUTH]->(auth:Auth)WHERE u.firstName = 'Paul' AND auth.name = 'admin' AND auth.level >= 3RETURN u
雖然 SQL 查詢需要多一個 JOIN 子句,但值得注意的是,在這種特定情況下,不僅用 Cypher 查詢語言編寫的查詢沒有額外的子句或 MATCH 路徑的變化,而且它也保持不變。后端的“查詢系統”上沒有必要進行任何更改!
結論?
楔形工程作為國際項目中的技術合作伙伴,設計了一個協作社交平臺,作為一個解耦的 Web 應用程序,在 3 層架構中由以下部分組成:
-
后端模塊,一個分層的 RESTful 架構,利用 JakartaEE 框架;?
-
知識圖,由 Neo4j 圖形數據庫提供的 NoSQL;?
-
前端模塊,一個基于 HTML、CSS 和 JavaScript 的單頁應用程序,利用 Angular 框架。?
我們面臨的最具挑戰性的設計選擇是使用原生利用 Cypher 查詢語言的驅動程序還是利用 OGM 庫簡化 DAO 實現:我們發現使用 Cypher 查詢語言編寫的自定義查詢構建整個應用程序既不可行也不可擴展,而 OGM 在處理涉及大量涉及引用外部實體的關系的大型數據層次結構時可能不夠高效。
我們最終選擇了一種自定義方法,利用 OGM 作為映射節點和邊緣的參考解決方案,以 ORM 類型的視角,并支持特定 DAO 的實現,因此通過無法表現良好的自定義查詢方法優化了時間上的優化。
總之,我們可以說采用的軟件架構很好地響應了知識圖模式的變化,并完全滿足了客戶需求,同時減輕了楔形工程開發團隊的努力。
然而,在采用這種架構之前,必須考慮一些威脅:
-
SQL 比 Cypher 查詢語言更為常見 → 因此,更容易找到(并因此納入開發團隊)能夠維護 RDBMS 而不是 Neo4j 圖形數據庫的代碼的專家;?
-
?Neo4j 的本地生產系統要求很高(即對于基于服務器的環境,至少推薦 8 GB)→ 這種解決方案可能不適合資源有限的場景和低成本實施;?
-
在我們的最大努力下,我們沒有找到任何“隨時可以使用且易于使用”的開源編輯器來瀏覽 Neo4j 圖形數據庫的數據結構(Neo4j 的官方數據瀏覽器不允許通過 GUI 進行數據修改,除非自定義 MERGE/CREATE 查詢),就像 RDBMS 有很多一樣 → 這可能是由于特定的數據模型本身導致的,使得實現數據的表格視圖變得困難。

作者:Cosimo Giani
更多技術干貨請關注公號【云原生數據庫】
squids.cn,云數據庫RDS,遷移工具DBMotion,云備份DBTwin等數據庫生態工具。

,解開JVM神秘的面紗)



)

)




)


![[SIGGRAPH-23] 3D Gaussian Splatting for Real-Time Radiance Field Rendering](http://pic.xiahunao.cn/[SIGGRAPH-23] 3D Gaussian Splatting for Real-Time Radiance Field Rendering)



![[ 云計算 | AWS 實踐 ] 基于 Amazon S3 協議搭建個人云存儲服務](http://pic.xiahunao.cn/[ 云計算 | AWS 實踐 ] 基于 Amazon S3 協議搭建個人云存儲服務)