深入 Linux 文件系統:從數據存儲到萬物皆文件
Linux 文件系統是一個精妙而復雜的工程,它像一座圖書館,不僅存放著書籍(數據),還有一套高效的卡片索引系統(元數據)來管理它們。本文將帶你深入探索,從最簡模型到現代實現,全面理解 Linux 文件系統的工作機制。
一、 核心思想:最小模型
任何文件系統都可以抽象為兩個核心區域:
- 元數據存儲區 (Metadata Region):用于管理文件的信息系統。
- 數據存儲區 (Data Region):用于存儲文件的實際內容。
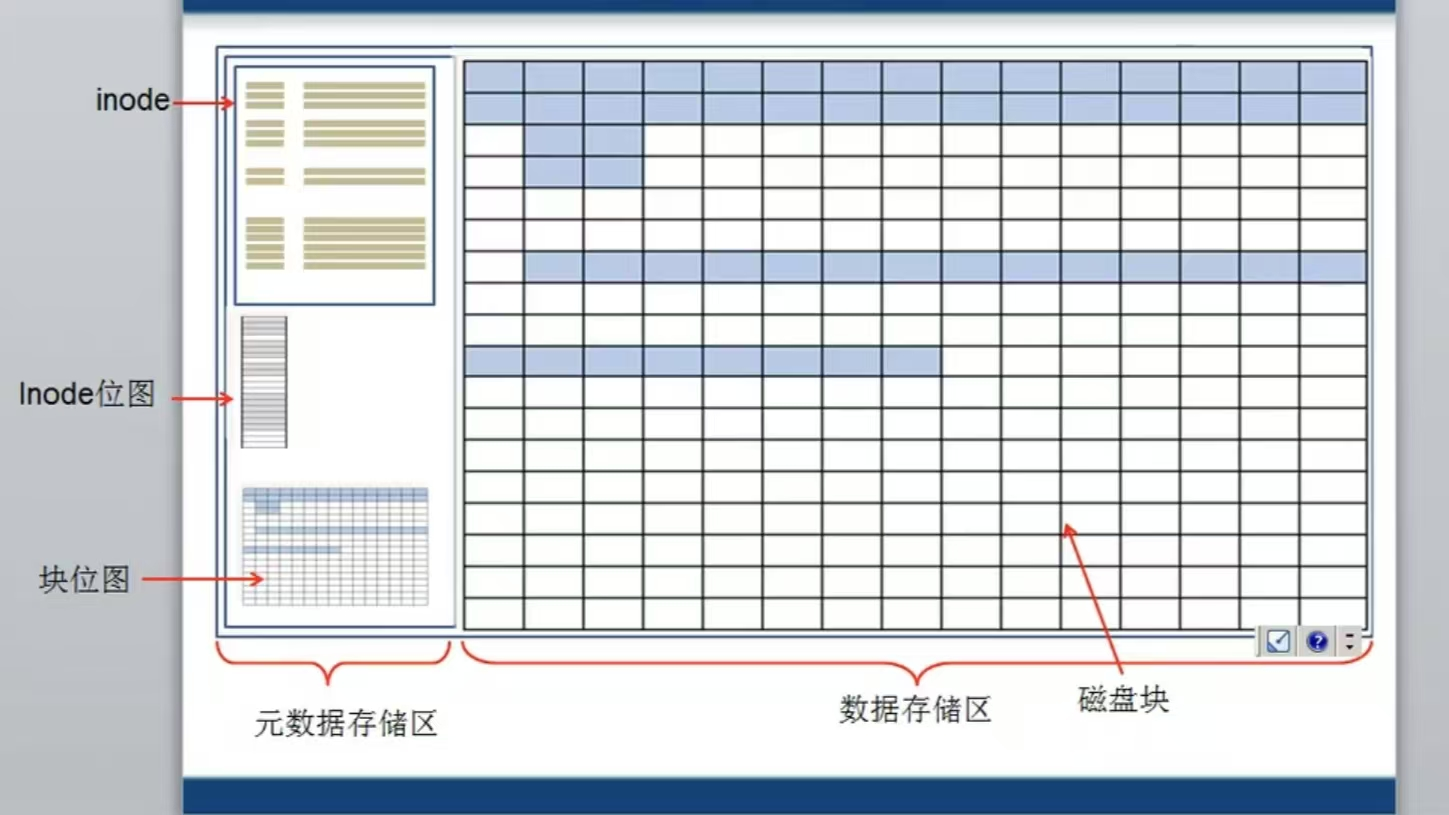
1. 元數據區的三大支柱
- inode 表 (inode Table):
- 每個文件或目錄都對應一個 inode(索引節點),它是文件的“身份證”。
- inode 記錄了文件的元信息:權限、所有者、大小、時間戳,以及最關鍵的——指向文件數據塊的指針。
- 文件名不存儲在 inode 中。
- inode 位圖 (inode Bitmap):
- 一個簡單的二進制位圖,用于快速追蹤哪些 inode 已被使用,哪些是空閑的。
- 系統創建新文件時,通過掃描此位圖來快速分配空閑 inode。
- 塊位圖 (Block Bitmap):
- 與 inode 位圖類似,用于追蹤數據存儲區中哪些數據塊已被使用,哪些是空閑的。
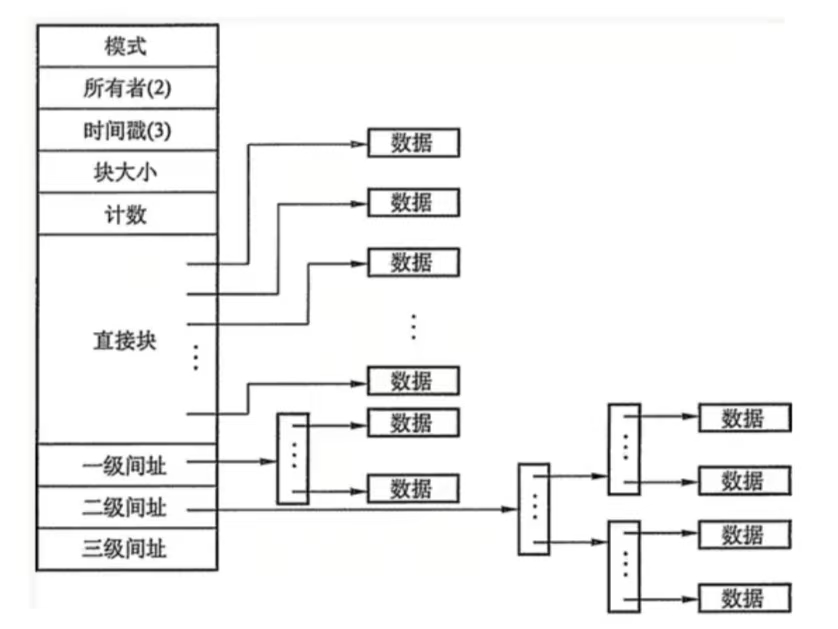
2. 目錄是什么?
目錄本身也是一種特殊的文件。它的內容不是普通數據,而是一張“表格”,記錄了其包含的文件和子目錄的名字到 inode 的映射關系。
- 例如:訪問 /test/123.mp3
| 文件名 | inode 號 |
|---|---|
| a.txt | 1001 |
| b.log | 1002 |
| test | 1003 |
| 文件名 | inode 號 |
|---|---|
| 123.mp3 | 5555 |
| music | 5556 |
結論:文件名是目錄的內容,而文件的實際信息由 inode 管理。這使得“重命名”文件在同一個目錄下幾乎瞬間完成,只需修改目錄文件中的一個條目即可。
3. 文件操作揭秘
- 新建文件:
- 在目錄文件中添加一個新條目(文件名 -> inode號)。
- 在 inode 位圖中找到一個空閑 inode 并標記為已用。
- 將文件元信息寫入該 inode。
- 在塊位圖中找到空閑數據塊并標記為已用。
- 將文件數據寫入數據塊,并將數據塊地址記錄在 inode 的指針中。
- 刪除文件:
- 在目錄中刪除文件名到 inode 的映射條目。
- 在 inode 位圖中將該文件對應的 inode 標記為空閑。
- 在塊位圖中將該文件占用的所有數據塊標記為空閑。
- 注意:數據并沒有被立即擦除,只是被“遺忘”了,直到被新數據覆蓋。這就是數據恢復的原理。
- 移動/重命名文件:
- 同一分區內:僅在原始目錄中刪除條目,并在目標目錄中創建一個新條目(指向同一個 inode)。速度快,因為數據無需移動。
- 跨分區:相當于在新位置“創建”一個新文件,然后刪除舊文件。速度慢,因為數據需要被復制。
4. 軟連接 vs. 硬鏈接
| 特性 | 硬鏈接 (Hard Link) | 軟連接 (Symbolic Link) |
|---|---|---|
| 本質 | 是同一個文件的多個目錄入口(別名) | 是一個獨立文件,內容存儲目標文件的路徑 |
| inode | 共享目標文件的 inode | 擁有自己的 inode |
| 跨分區/FS | 不支持 | 支持 |
| 刪除原文件 | 不影響硬鏈接訪問 | 軟連接失效(“懸空鏈接”) |
ln 命令 | ln <源文件> <鏈接名> | ln -s <源文件> <鏈接名> |
二、 日志文件系統 (Journaling FS)
1. 非日志文件系統的問題
在傳統文件系統(如 ext2)中,如果發生意外斷電或系統崩潰,一個正在進行的寫操作可能只完成了一半(例如,數據塊已寫入,但 inode 未更新)。這會導致文件系統處于不一致狀態,需要運行漫長的 fsck 工具來檢查和修復,耗時極長。
2. 日志的解決方案
日志文件系統(如 ext3, ext4, XFS, Btrfs)引入了“預寫日志 (Write-Ahead Logging)”機制。
- 記錄日志:在真正修改元數據之前,先將即將要執行的操作概要寫入磁盤的一個特定區域(日志)。
- 提交操作:只有日志成功寫入后,才真正執行文件系統的元數據和數據寫入。
- 檢查點:操作完成后,在日志中標記該事務已完成。
好處:如果系統崩潰,恢復時只需讀取日志,重做(Redo)或撤銷(Undo)未完成的操作即可, recovery 速度極快,保證了數據一致性。
三、 實際文件系統模型:Ext4 的塊組
現代文件系統(如 ext4)將整個分區劃分為多個塊組 (Block Groups),每個塊組都擁有自己的元數據區和數據區,這是一種卓越的優化設計。
- 超級塊 (Superblock):存儲整個文件系統的全局信息(如大小、塊數量、空閑 inode 計數等)。通常會在多個塊組中進行備份,防止單點故障。
- 塊組描述符表 (Group Descriptor Table):描述每個塊組的詳細信息(如塊位圖和 inode 位圖的位置、空閑 inode 數等)。
- 每個塊組包含:
- 一份備份的超級塊和塊組描述符(可選)。
- 該塊組專用的 inode 位圖 和 塊位圖。
- 該塊組專用的 inode 表。
- 該塊組專用的數據塊。
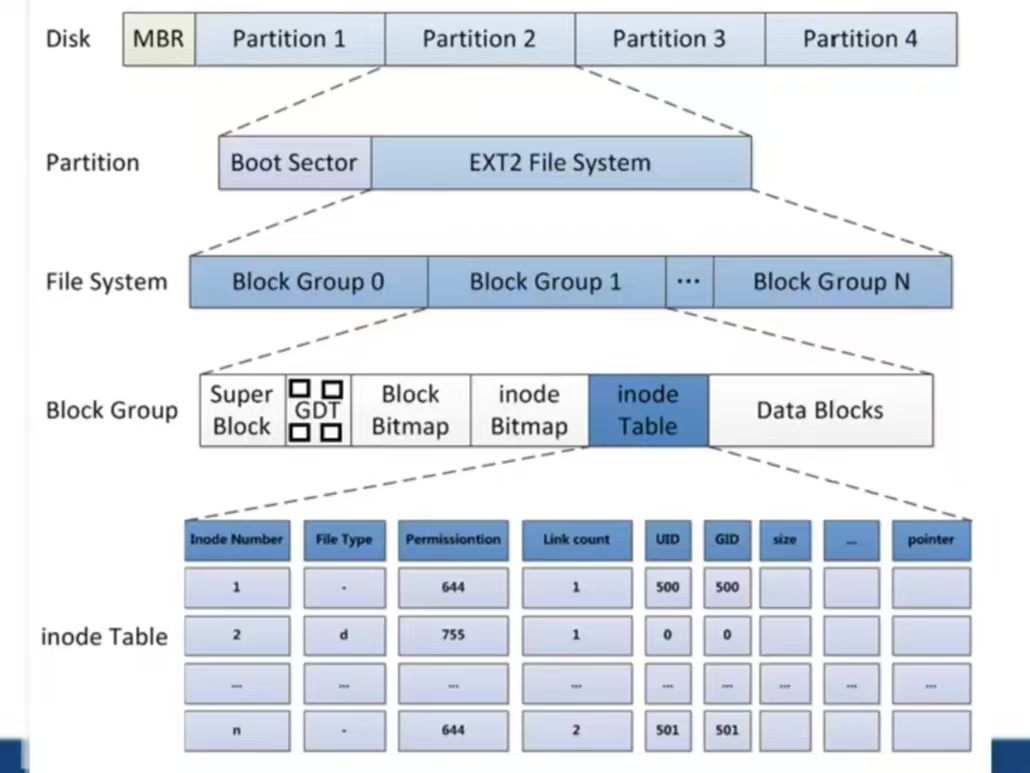
現代文件系統的優勢:
- 性能:將 inode 和數據塊靠近存放,減少磁頭尋道時間(磁盤 fragmentation 的影響降低)。
- 可靠性:元數據分散備份,部分損壞不會導致整個文件系統癱瘓。
- 并行性:內核可以同時處理多個塊組,提高吞吐量。
四、 虛擬文件系統 (VFS):一切皆文件
Linux 支持數十種文件系統(ext4, XFS, NTFS, FAT32…),應用程序如何用統一的 open(), read(), write() 接口與它們交互?答案是 VFS。
- VFS 是什么?:它是內核中的一個抽象層,為上層的應用程序提供一套統一的文件操作接口。
- 如何工作?:當應用程序調用
read()時,VFS 會根據文件路徑找到其所在的具體文件系統(如 ext4),然后調用該文件系統驅動提供的read()方法。對應用程序來說,這個過程是透明的。 - 一切皆文件:VFS 的強大之處在于它將許多資源都抽象成了文件。
- 普通文件、目錄 -> 文件
- 塊設備 (
/dev/sda1) -> 文件 - 字符設備 (
/dev/tty,/dev/null) -> 文件 - 網絡套接字 (Sockets) -> 文件
- 管道 (Pipes) -> 文件
這使得我們可以使用相同的read/write命令與各種資源交互。
- 掛載 (Mount):將某個設備(如
/dev/sda1)關聯到當前目錄樹中的一個目錄(如/home)。這個目錄稱為掛載點 (Mount Point)。通過mount命令,VFS 將不同的文件系統整合成一棵單一的、統一的目錄樹。
五、 文件系統的運行機制:從系統調用到硬件寫入
當你在應用程序中調用 write(fd, buf, count) 這樣一行簡單的代碼時,Linux 內核中會觸發一場精妙的協作。數據需要穿越多個軟件層次,最終才能安全地抵達磁盤。這個過程體現了 Linux 系統設計的模塊化和層次化思想。
其核心層次結構如下圖所示,數據請求自上而下流動:
1. 虛擬文件系統 (VFS - Virtual File System)
VFS 是所有文件系統操作的總入口和調度中心。它的主要職責是:
- 抽象與統一:為上層應用程序提供統一的系統調用接口(如
open,read,write,close),無論底層是哪種文件系統。 - 查找與路由:當應用程序請求操作某個路徑(如
/home/user/file.txt)的文件時,VFS 負責解析路徑,找到目標文件對應的 inode。 - 多文件系統支持:VFS 定義了一套所有文件系統驅動都必須實現的通用操作接口(
file_operations,inode_operations等)。找到文件后,VFS 會根據該文件所在的具體文件系統類型(如 ext4),調用該文件系統驅動提供的具體方法。這就是為什么 Linux 可以同時掛載和使用多種文件系統的原因。
簡單來說,VFS 是一個“經理”,它接收客戶(應用程序)的請求,然后派發給對應的“專員”(具體文件系統)去處理。
2. 具體文件系統 (如 ext4, XFS, Btrfs)
這一層是處理文件系統特定邏輯的“專員”。它接收來自 VFS 的請求,并轉換為對磁盤布局的具體操作:
- 邏輯到物理的映射:它的核心任務是管理 inode、目錄、數據塊等結構。當收到寫請求時,它需要:
- 為數據分配空閑的數據塊(通過查詢塊位圖)。
- 更新文件的 inode,將新的數據塊地址添加到指針列表中。
- 可能還需要更新目錄文件(如文件大小改變)、日志等。
- 事務管理:對于日志文件系統,它會將此次寫操作作為一個事務(Transaction)寫入日志區域,確保一致性。
- 提交 IO 請求:處理完元數據后,它將本次寫請求轉換為一個或多個IO請求。每個請求描述了要寫入的邏輯塊號 (Logical Block Number) 和數據。這些請求被提交到下一層:通用塊層。
3. 通用塊層 (Generic Block Layer)
通用塊層是 Linux 存儲子系統中的交通指揮官,負責所有塊設備(硬盤、SSD)的IO管理。它的核心任務是優化和調度IO請求:
- IO調度 (IO Scheduler):
- 合并 (Merging):將多個連續的、小的IO請求合并成一個大的請求,減少IO次數。
- 排序 (Sorting):對請求按磁盤扇區號進行排序(類似于電梯算法),將無序的請求變為順序請求,極大減少機械硬盤的磁頭尋道時間,提升吞吐量。
- 公平性調度:在多個進程競爭IO資源時,保證系統的響應性。
- 創建
bio結構:調度完成后,通用塊層會創建一個或多個bio(Block IO)結構,這是內核中描述塊IO請求的通用數據結構。bio包含了要寫入的物理設備、起始扇區、數據在內存中的位置等信息。
4. 設備驅動層 (Device Driver Layer)
這是最后一步,bio 請求被發送到具體的塊設備驅動(如 SATA, NVMe, Virtio-BLK 驅動)。
- 驅動將
bio請求轉換為硬件控制器能夠理解的指令(如 NVMe 的 SQ/CQ 命令)。 - 它通常會配置 DMA (Direct Memory Access),讓設備控制器直接從內存中取數據并寫入磁盤,無需CPU參與,解放了CPU。
- 寫入完成后,設備會發出一個中斷,通知CPU寫入操作已經完成。然后這個完成信號會自底向上地一層層返回,最終告知應用程序寫入操作成功。
六、 繞過文件系統:設備訪問
在 /dev/ 目錄下的文件是設備文件,是應用程序與硬件設備驅動的接口。
- 塊設備 (Block Devices):
- 特性:數據存儲在以固定大小(如 4KiB)的“塊”中,支持隨機訪問(如硬盤、SSD)。
- 讀寫:通常涉及緩存,讀寫操作先經過內核的頁緩存 (Page Cache),然后由內核擇時寫入設備,以提高性能。
- 示例:
/dev/sda(硬盤),/dev/vda1(虛擬磁盤分區)。
- 字符設備 (Character Devices):
- 特性:數據以字節流的形式處理,不支持隨機尋址(如鍵盤、鼠標、打印機)。
- 讀寫:通常沒有緩存,數據直接與驅動交互。
- 示例:
/dev/tty(終端),/dev/random(隨機數生成器)。
設備訪問只需要經過虛擬文件系統,不需要經過文件系統。
總結
Linux 文件系統是一個層次化的杰作:
- 底層:
數據塊 + inode的最小模型保證基礎功能。 - 中層:
日志 + 塊組的設計保證了性能、可靠性和可擴展性。 - 頂層:
VFS抽象統一了所有差異,實現了“一切皆文件”的哲學,并通過掛載將其組織成統一的視圖。





)




科大訊飛)







![P4342 [IOI 1998] Polygon -普及+/提高](http://pic.xiahunao.cn/P4342 [IOI 1998] Polygon -普及+/提高)
