函數式編程-Stream流
1. 概述
1.1 為什么學?
-
能夠看懂公司里的代碼
-
大數量下處理集合效率高
-
代碼可讀性高
-
消滅嵌套地獄
//查詢未成年作家的評分在70以上的書籍 由于數據中作家和書籍可能出現重復,需要進行去重
List<Book> bookList = new ArrayList<>();
Set<Book> uniqueBookValues = new HashSet<>();
Set<Author> uniqueAuthorValues = new HashSet<>();
for (Author author : authors) {if (uniqueAuthorValues.add(author)) {if (author.getAge() < 18) {List<Book> books = author.getBooks();for (Book book : books) {if (book.getScore() > 70) {if (uniqueBookValues.add(book)) {bookList.add(book);}}}}}
}
System.out.println(bookList);List<Book> collect = authors.stream().distinct().filter(author -> author.getAge() < 18).map(author -> author.getBooks()).flatMap(Collection::stream).filter(book -> book.getScore() > 70).distinct().collect(Collectors.toList());
System.out.println(collect);1.2 函數式編程思想
1.2.1 概念
面向對象思想需要關注用什么對象完成什么事情。而函數式編程思想就類似于我們數學中的函數。它主要關注的是對數據進行了什么操作。
1.2.2 優點
-
代碼簡潔,開發快速
-
接近自然語言,易于理解
-
易于"并發編程"
2. Lambda表達式
2.1 概述
Lambda是JDK8中一個語法糖。他可以對某些匿名內部類的寫法進行簡化。它是函數式編程思想的一個重要體現。讓我們不用關注是什么對象。而是更關注我們對數據進行了什么操作
2.2 核心原則
可推導可省略
2. 3 基本格式
?(參數列表)->{代碼}
例一
我們在創建線程并啟動時可以使用匿名內部類的寫法
new Thread(new Runnable() {@Overridepublic void run() {System.out.println("你知道嗎 我比你想象的 更想在你身邊");}
}).start();可以使用Lambda的格式對其進行修改。修改后如下
new Thread(()->{System.out.println("你知道嗎 我比你想象的 更想在你身邊");
}).start();例二:
現有方法定義如下,其中IntBinaryOperator是一個接口。先使用匿名內部類的寫法調用該方法。
public static int calculateNum(IntBinaryOperator operator){int a = 10;int b = 20;return operator.applyAsInt(a, b);}public static void main(String[] args) {int i = calculateNum(new IntBinaryOperator() {@Overridepublic int applyAsInt(int left, int right) {return left + right;}});System.out.println(i);}?Lambda寫法:
public static void main(String[] args) {int i = calculateNum((int left, int right)->{return left + right;});System.out.println(i);}例三:
現有方法定義如下,其中IntPredicate是一個接口。先使用匿名內部類的寫法調用該方法
public static void printNum(IntPredicate predicate){int[] arr = {1,2,3,4,5,6,7,8,9,10};for (int i : arr) {if(predicate.test(i)){System.out.println(i);}}}public static void main(String[] args) {printNum(new IntPredicate() {@Overridepublic boolean test(int value) {return value%2==0;}});}?Lambda寫法:
public static void main(String[] args) {printNum((int value)-> {return value%2==0;});}public static void printNum(IntPredicate predicate){int[] arr = {1,2,3,4,5,6,7,8,9,10};for (int i : arr) {if(predicate.test(i)){System.out.println(i);}}}例四:
現有方法定義如下,其中Function是一個接口。先使用匿名內部類的寫法調用該方法。
public static <R> R typeConver(Function<String,R> function){String str = "1235";R result = function.apply(str);return result;}public static void main(String[] args) {Integer result = typeConver(new Function<String, Integer>() {@Overridepublic Integer apply(String s) {return Integer.valueOf(s);}});System.out.println(result);}Lambda寫法:
Integer result = typeConver((String s)->{return Integer.valueOf(s);});System.out.println(result);例五:
現有方法定義如下,其中IntConsumer是一個接口。先使用匿名內部類的寫法調用該方法。
public static void foreachArr(IntConsumer consumer){int[] arr = {1,2,3,4,5,6,7,8,9,10};for (int i : arr) {consumer.accept(i);}}public static void main(String[] args) {foreachArr(new IntConsumer() {@Overridepublic void accept(int value) {System.out.println(value);}});}?Lambda寫法:
public static void main(String[] args) {foreachArr((int value)->{System.out.println(value);});}2.4 省略規則
-
參數類型可以省略
-
方法體只有一句代碼時大括號return和唯一一句代碼的分號可以省略
-
方法只有一個參數時小括號可以省略(無參必須要寫小括號)
-
以上這些規則都記不住也可以省略不記
3. Stream流
3.1 概述
Java8的Stream使用的是函數式編程模式,如同它的名字一樣,它可以被用來對集合或數組進行鏈狀流式的操作。可以更方便的讓我們對集合或數組操作。
3.2 案例數據準備
<dependencies><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.10</version></dependency></dependencies>@Data
//等效于 @Getter @Setter @RequiredArgsConstructor @ToString @EqualsAndHashCode。
//get方法、set方法、final修改或者@Notnull修飾字段的構造函數、toString方法、重寫equals和hashCode方法
@AllArgsConstructor
@NoArgsConstructor
public class Author {//idprivate Long id;//姓名private String name;//年齡private Integer age;//簡介private String intro;//作品private List<Book> books;
}@Data
//等效于 @Getter @Setter @RequiredArgsConstructor @ToString @EqualsAndHashCode。
//get方法、set方法、final修改或者@Notnull修飾字段的構造函數、toString方法、重寫equals和hashCode方法
@AllArgsConstructor
@NoArgsConstructor
public class Book {//idprivate Long id;//書名private String name;//分類private String category;//評分private Integer score;//簡介private String intro;}private static List<Author> getAuthors() {//數據初始化Author author = new Author(1L,"蒙多",33,"一個從菜刀中明悟哲理的祖安人",null);Author author2 = new Author(2L,"亞拉索",15,"狂風也追逐不上他的思考速度",null);Author author3 = new Author(3L,"易",14,"是這個世界在限制他的思維",null);Author author4 = new Author(3L,"易",14,"是這個世界在限制他的思維",null);//書籍列表List<Book> books1 = new ArrayList<>();List<Book> books2 = new ArrayList<>();List<Book> books3 = new ArrayList<>();books1.add(new Book(1L,"刀的兩側是光明與黑暗","哲學,愛情",88,"用一把刀劃分了愛恨"));books1.add(new Book(2L,"一個人不能死在同一把刀下","個人成長,愛情",99,"講述如何從失敗中明悟真理"));books2.add(new Book(3L,"那風吹不到的地方","哲學",85,"帶你用思維去領略世界的盡頭"));books2.add(new Book(3L,"那風吹不到的地方","哲學",85,"帶你用思維去領略世界的盡頭"));books2.add(new Book(4L,"吹或不吹","愛情,個人傳記",56,"一個哲學家的戀愛觀注定很難把他所在的時代理解"));books3.add(new Book(5L,"你的劍就是我的劍","愛情",56,"無法想象一個武者能對他的伴侶這么的寬容"));books3.add(new Book(6L,"風與劍","個人傳記",100,"兩個哲學家靈魂和肉體的碰撞會激起怎么樣的火花呢?"));books3.add(new Book(6L,"風與劍","個人傳記",100,"兩個哲學家靈魂和肉體的碰撞會激起怎么樣的火花呢?"));author.setBooks(books1);author2.setBooks(books2);author3.setBooks(books3);author4.setBooks(books3);List<Author> authorList = new ArrayList<>(Arrays.asList(author,author2,author3,author4));return authorList;}3.3 快速入門
3.3.1 需求
我們可以調用getAuthors方法獲取到作家的集合。現在需要打印所有年齡小于18的作家的名字,并且要注意去重。
3.3.2 實現
//打印所有年齡小于18的作家的名字,并且要注意去重List<Author> authors = getAuthors();authors.stream()//把集合轉換成流.distinct()//先去除重復的作家.filter(author -> author.getAge()<18)//篩選年齡小于18的.forEach(author -> System.out.println(author.getName()));//遍歷打印名字3.4 常用操作
3.4.1 創建流
單列集合: 集合對象.stream()
List<Author> authors = getAuthors();Stream<Author> authorStream = authors.stream();數組:Arrays.stream(數組)或者使用Stream.of來創建
Integer[] arr = {1,2,3,4,5};Stream<Integer> stream = Arrays.stream(arr);//參數是可變數組 Stream<Integer> arr1 = Stream.of(arr);雙列集合:轉換成單列集合后再創建
Map<String,Integer> map = new HashMap<>();map.put("蠟筆小新",19);map.put("黑子",17);map.put("日向翔陽",16);Stream<Map.Entry<String, Integer>> stream = map.entrySet().stream();3.4.2 中間操作
filter
可以對流中的元素進行條件過濾,符合過濾條件的才能繼續留在流中。
例如:
打印所有姓名長度大于1的作家的姓名
List<Author> authors = getAuthors();authors.stream().distinct().filter(author -> author.getName().length() > 1).forEach(author -> System.out.println(author.getName()));map
可以把對流中的元素進行計算或轉換。
例如:
打印所有作家的姓名
List<Author> authors = getAuthors();authors.stream().map(author -> author.getName()).forEach(name -> System.out.println(name));distinct
可以去除流中的重復元素。
例如:
打印所有作家的姓名,并且要求其中不能有重復元素。
List<Author> authors = getAuthors();authors.stream().distinct().map(author -> author.getName())
// .forEach(name -> System.out.println(name)); .forEach(System.out::println);?注意:distinct方法是依賴Object的equals方法來判斷是否是相同對象的。所以需要注意重寫equals方法。
sorted
可以對流中的元素進行排序。
例如:
對流中的元素按照年齡進行降序排序,并且要求不能有重復的元素。
List<Author> authors = getAuthors();
// 對流中的元素按照年齡進行降序排序,并且要求不能有重復的元素。authors.stream().distinct().sorted().forEach(author -> System.out.println(author.getAge()));注意:如果調用空參的sorted()方法,需要流中的元素是實現了Comparable。
@Data
public class Author implements Comparable<Author> {//idprivate Long id;//姓名private String name;//年齡private Integer age;//簡介private String intro;//作品private List<Book> books;@Overridepublic int compareTo(Author author) {return author.getAge() - this.age;} getAuthors().stream().distinct().sorted((o1,o2) -> o2.getAge() - o1.getAge()).forEach(author -> System.out.println(author));limit
可以設置流的最大長度,超出的部分將被拋棄。
例如:
對流中的元素按照年齡進行降序排序,并且要求不能有重復的元素,然后打印其中年齡最大的兩個作家的姓名。
getAuthors().stream().distinct().sorted((o1,o2) -> o2.getAge() - o1.getAge()).limit(2).forEach(author -> System.out.println(author.getName()));skip
跳過流中的前n個元素,返回剩下的元素
例如:
打印除了年齡最大的作家外的其他作家,要求不能有重復元素,并且按照年齡降序排序。
getAuthors().stream().distinct().sorted().skip(1).forEach(author -> System.out.println(author));flatMap
map只能把一個對象轉換成另一個對象來作為流中的元素。而flatMap可以把一個對象轉換成多個對象作為流中的元素。
例一:
打印所有書籍的名字。要求對重復的元素進行去重。
getAuthors().stream().distinct().flatMap(author -> author.getBooks().stream()).distinct().forEach(book -> System.out.println(book.getName()));例二:
打印現有數據的所有分類。要求對分類進行去重。不能出現這種格式:哲學,愛情
getAuthors().stream().distinct().flatMap(author -> author.getBooks().stream()).distinct().flatMap(book ->Stream.of(book.getCategory().split(","))).distinct().forEach(category -> System.out.println(category));3.4.3 終結操作
forEach
對流中的元素進行遍歷操作,我們通過傳入的參數去指定對遍歷到的元素進行什么具體操作。
例子:
輸出所有作家的名字
// 輸出所有作家的名字List<Author> authors = getAuthors();authors.stream().map(author -> author.getName()).distinct().forEach(name-> System.out.println(name));count
可以用來獲取當前流中元素的個數。
例子:
打印這些作家的所出書籍的數目,注意刪除重復元素。
// 打印這些作家的所出書籍的數目,注意刪除重復元素。List<Author> authors = getAuthors();long count = authors.stream().flatMap(author -> author.getBooks().stream()).distinct().count();System.out.println(count);max&min
可以用來或者流中的最值。
例子:
分別獲取這些作家的所出書籍的最高分和最低分并打印。
// 分別獲取這些作家的所出書籍的最高分和最低分并打印Optional<Integer> max = getAuthors().stream().distinct().flatMap(author -> author.getBooks().stream()).distinct().map(book -> book.getScore()).max((o1, o2) -> o1- o2);Optional<Integer> min = getAuthors().stream().distinct().flatMap(author -> author.getBooks().stream()).distinct().map(book -> book.getScore()).min((o1, o2) -> o1- o2);System.out.println(max.orElse(-1));System.out.println(min.orElse(-1));collect
把當前流轉換成一個集合。
例子:
獲取一個存放所有作者名字的List集合。
// 獲取一個存放所有作者名字的List集合。List<String> collect = getAuthors().stream().distinct().map(author -> author.getName()).collect(Collectors.toList());System.out.println(collect);獲取一個所有書名的Set集合。
Set<String> collect = getAuthors().stream().flatMap(author -> author.getBooks().stream()).map(book -> book.getName()).collect(Collectors.toSet());System.out.println(collect);獲取一個Map集合,map的key為作者名,value為List<Book>
List<Author> authors = getAuthors();Map<String, List<Book>> map = authors.stream().distinct().collect(Collectors.toMap(author -> author.getName(), author -> author.getBooks()));System.out.println(map);查找與匹配
anyMatch
可以用來判斷是否有任意符合匹配條件的元素,結果為boolean類型。
例子:
判斷是否有年齡在29以上的作家
boolean flag = getAuthors().stream().distinct().anyMatch(author -> author.getAge() > 29);System.out.println(flag);allMatch
可以用來判斷是否都符合匹配條件,結果為boolean類型。如果都符合結果為true,否則結果為false。
例子:
判斷是否所有的作家都是成年人
boolean flag = getAuthors().stream().distinct().allMatch(author -> author.getAge() >= 18);System.out.println(flag);noneMatch
可以判斷流中的元素是否都不符合匹配條件。如果都不符合結果為true,否則結果為false
例子:
判斷作家是否都沒有超過100歲的。
boolean flag = getAuthors().stream().distinct().noneMatch(author -> author.getAge() > 100);System.out.println(flag);findAny
獲取流中的任意一個元素。該方法沒有辦法保證獲取的一定是流中的第一個元素。
例子:
獲取任意一個年齡大于18的作家,如果存在就輸出他的名字
Optional<Author> any = getAuthors().stream().findAny();System.out.println(any.get());findFirst
獲取流中的第一個元素。
例子:
獲取一個年齡最小的作家,并輸出他的姓名。
Optional<Author> first = getAuthors().stream().findFirst();first.ifPresent(System.out::println);reduce歸并
對流中的數據按照你指定的計算方式計算出一個結果。(縮減操作)
reduce的作用是把stream中的元素給組合起來,我們可以傳入一個初始值,它會按照我們的計算方式依次拿流中的元素和初始化值進行計算,計算結果再和后面的元素計算。
reduce兩個參數的重載形式內部的計算方式如下:
T result = identity;
for (T element : this stream)
?? ?result = accumulator.apply(result, element)
return result;
其中identity就是我們可以通過方法參數傳入的初始值,accumulator的apply具體進行什么計算也是我們通過方法參數來確定的。
例子:
使用reduce求所有作者年齡的和
Integer sum = getAuthors().stream().map(author -> author.getAge()).reduce(0, (integer, element) -> integer + element);System.out.println(sum);? 使用reduce求所有作者中年齡的最大值
Integer max = getAuthors().stream().map(author -> author.getAge()).reduce(Integer.MIN_VALUE, (result, element) -> element > result ? element : result);System.out.println(max);使用reduce求所有作者中年齡的最小值
Integer min = getAuthors().stream().map(author -> author.getAge()).distinct().reduce(Integer.MAX_VALUE, (result, element) -> element < result ? element : result);System.out.println(min);reduce一個參數的重載形式內部的計算
?boolean foundAny = false;
? ? ?T result = null;
? ? ?for (T element : this stream) {
? ? ? ? ?if (!foundAny) {
? ? ? ? ? ? ?foundAny = true;
? ? ? ? ? ? ?result = element;
? ? ? ? ?}
? ? ? ? ?else
? ? ? ? ? ? ?result = accumulator.apply(result, element);
? ? ?}
? ? ?return foundAny ? Optional.of(result) : Optional.empty();
就相當于把流中第一個作為初始值?
如果用一個參數的重載方法去求最小值代碼如下:
Optional<Integer> reduce = getAuthors().stream().map(author -> author.getAge()).distinct().reduce((result, element) -> element < result ? element : result);reduce.ifPresent(System.out::println);3.5 注意事項
-
惰性求值(如果沒有終結操作,沒有中間操作是不會得到執行的)
-
流是一次性的(一旦一個流對象經過一個終結操作后。這個流就不能再被使用)
-
不會影響原數據(我們在流中可以多數據做很多處理。但是正常情況下是不會影響原來集合中的元素的。這往往也是我們期望的)
4. Optional
4.1 概述
我們在編寫代碼的時候出現最多的就是空指針異常。所以在很多情況下我們需要做各種非空的判斷。
例如:
Author author = getAuthor();if(author!=null){System.out.println(author.getName());}?
尤其是對象中的屬性還是一個對象的情況下。這種判斷會更多。
而過多的判斷語句會讓我們的代碼顯得臃腫不堪。
所以在JDK8中引入了Optional,養成使用Optional的習慣后你可以寫出更優雅的代碼來避免空指針異常。
并且在很多函數式編程相關的API中也都用到了Optional,如果不會使用Optional也會對函數式編程的學習造成影響。
4.2 使用
4.2.1 創建對象
Optional就好像是包裝類,可以把我們的具體數據封裝Optional對象內部。然后我們去使用Optional中封裝好的方法操作封裝進去的數據就可以非常優雅的避免空指針異常。
我們一般使用Optional的靜態方法ofNullable來把數據封裝成一個Optional對象。無論傳入的參數是否為null都不會出現問題。
Author author = getAuthor();Optional<Author> authorOptional = Optional.ofNullable(author);你可能會覺得還要加一行代碼來封裝數據比較麻煩。但是如果改造下getAuthor方法,讓其的返回值就是封裝好的Optional的話,我們在使用時就會方便很多。
而且在實際開發中我們的數據很多是從數據庫獲取的。Mybatis從3.5版本可以也已經支持Optional了。我們可以直接把dao方法的返回值類型定義成Optional類型,MyBastis會自己把數據封裝成Optional對象返回。封裝的過程也不需要我們自己操作。
如果你確定一個對象不是空的則可以使用Optional的靜態方法of來把數據封裝成Optional對象。
Author author = new Author();Optional<Author> authorOptional = Optional.of(author);?
但是一定要注意,如果使用of的時候傳入的參數必須不為null。(嘗試下傳入null會出現什么結果)
Optional.ofNullable(null); //不會報錯Optional.of(null); //會報錯如果一個方法的返回值類型是Optional類型。而如果我們經判斷發現某次計算得到的返回值為null,這個時候就需要把null封裝成Optional對象返回。這時則可以使用Optional的靜態方法empty來進行封裝。
Optional.empty()所以最后你覺得哪種方式會更方便呢?ofNullable
4.2.2 安全消費值
我們獲取到一個Optional對象后肯定需要對其中的數據進行使用。這時候我們可以使用其ifPresent方法對來消費其中的值。
這個方法會判斷其內封裝的數據是否為空,不為空時才會執行具體的消費代碼。這樣使用起來就更加安全了。
例如,以下寫法就優雅的避免了空指針異常。
Optional<Author> authorOptional = Optional.ofNullable(getAuthor());authorOptional.ifPresent(author -> System.out.println(author.getName()));?
4.2.3 獲取值
如果我們想獲取值自己進行處理可以使用get方法獲取,但是不推薦。因為當Optional內部的數據為空的時候會出現異常。
4.2.4 安全獲取值
如果我們期望安全的獲取值。我們不推薦使用get方法,而是使用Optional提供的以下方法。
-
orElseGet
獲取數據并且設置數據為空時的默認值。如果數據不為空就能獲取到該數據。如果為空則根據你傳入的參數來創建對象作為默認值返回。
Optional<Author> authorOptional = Optional.ofNullable(getAuthors().get(0));Author author1 = authorOptional.orElseGet(() -> new Author());Author author2= authorOptional.orElse(new Author());或者使用orElse
兩者的明顯(也是唯一)區別是,前者傳遞的是一個函數?,后者需要傳遞的參數是一個值(通常是為空時的默認值)
- orElseThrow
獲取數據,如果數據不為空就能獲取到該數據。如果為空則根據你傳入的參數來創建異常拋出。
Optional<Author> authorOptional = Optional.ofNullable(getAuthor());try {Author author = authorOptional.orElseThrow((Supplier<Throwable>) () -> new RuntimeException("author為空"));System.out.println(author.getName());} catch (Throwable throwable) {throwable.printStackTrace();}4.2.5 過濾
我們可以使用filter方法對數據進行過濾。如果原本是有數據的,但是不符合判斷,也會變成一個無數據的Optional對象。
Optional<Author> authorOptional = Optional.ofNullable(getAuthor());authorOptional.filter(author -> author.getAge()>100).ifPresent(author -> System.out.println(author.getName()));?
4.2.6 判斷
我們可以使用isPresent方法進行是否存在數據的判斷。如果為空返回值為false,如果不為空,返回值為true。但是這種方式并不能體現Optional的好處,更推薦使用ifPresent方法。
Optional<Author> authorOptional = Optional.ofNullable(getAuthor());if (authorOptional.isPresent()) {System.out.println(authorOptional.get().getName());}4.2.7 數據轉換
Optional還提供了map可以讓我們的對數據進行轉換,并且轉換得到的數據也還是被Optional包裝好的,保證了我們的使用安全。
例如我們想獲取作家的書籍集合。
private static void testMap() {Optional<Author> authorOptional = getAuthorOptional();Optional<List<Book>> optionalBooks = authorOptional.map(author -> author.getBooks());optionalBooks.ifPresent(books -> System.out.println(books));}?
5. 函數式接口
5.1 概述
只有一個抽象方法的接口我們稱之為函數接口。
JDK的函數式接口都加上了@FunctionalInterface 注解進行標識。但是無論是否加上該注解只要接口中只有一個抽象方法,都是函數式接口。
5.2 常見函數式接口
-
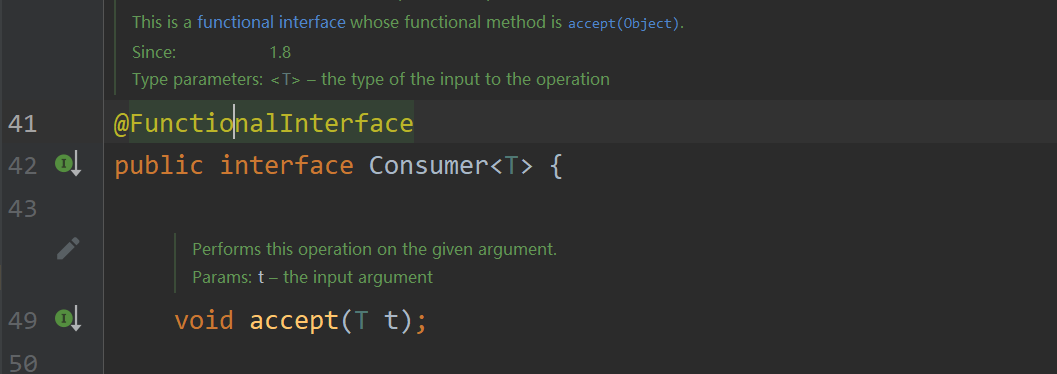
Consumer 消費接口
根據其中抽象方法的參數列表和返回值類型知道,我們可以在方法中對傳入的參數進行消費。
 ?
?
- Function 計算轉換接口
根據其中抽象方法的參數列表和返回值類型知道,我們可以在方法中對傳入的參數計算或轉換,把結果返回
 ?
?
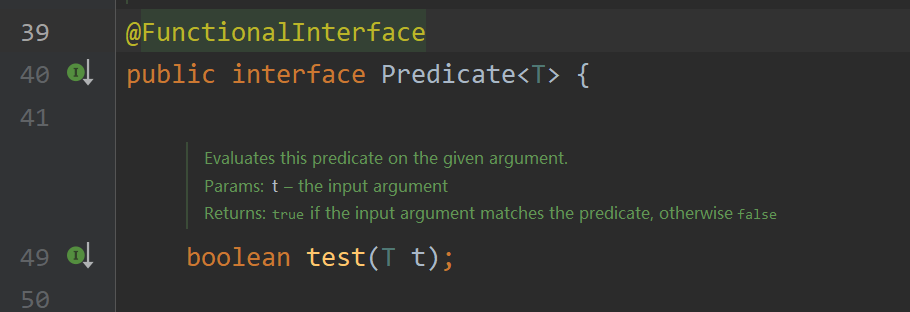
- Predicate 判斷接口
根據其中抽象方法的參數列表和返回值類型知道,我們可以在方法中對傳入的參數條件判斷,返回判斷結果
 ?
?
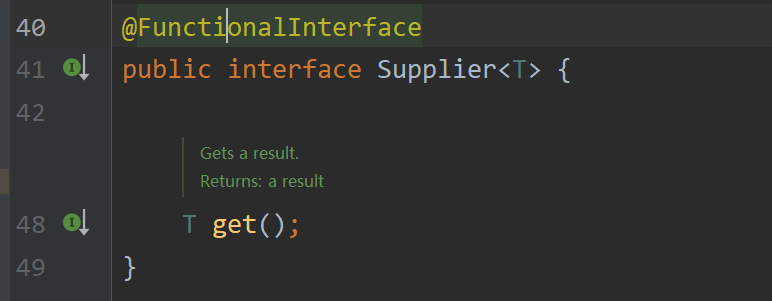
- Supplier 生產型接口
根據其中抽象方法的參數列表和返回值類型知道,我們可以在方法中創建對象,把創建好的對象返回
 ?
?
5.3 常用的默認方法
-
and
我們在使用Predicate接口時候可能需要進行判斷條件的拼接。而and方法相當于是使用&&來拼接兩個判斷條件
例如:
打印作家中年齡大于17并且姓名的長度大于1的作家。
List<Author> authors = getAuthors();Stream<Author> authorStream = authors.stream();authorStream.filter(new Predicate<Author>() {@Overridepublic boolean test(Author author) {return author.getAge()>17;}}.and(new Predicate<Author>() {@Overridepublic boolean test(Author author) {return author.getName().length()>1;}})).forEach(author -> System.out.println(author));?
- or
我們在使用Predicate接口時候可能需要進行判斷條件的拼接。而or方法相當于是使用||來拼接兩個判斷條件。
例如:
打印作家中年齡大于17或者姓名的長度小于2的作家。
// 打印作家中年齡大于17或者姓名的長度小于2的作家。List<Author> authors = getAuthors();authors.stream().filter(new Predicate<Author>() {@Overridepublic boolean test(Author author) {return author.getAge()>17;}}.or(new Predicate<Author>() {@Overridepublic boolean test(Author author) {return author.getName().length()<2;}})).forEach(author -> System.out.println(author.getName()));?
- negate
Predicate接口中的方法。negate方法相當于是在判斷添加前面加了個! 表示取反
例如:
打印作家中年齡不大于17的作家。
// 打印作家中年齡不大于17的作家。List<Author> authors = getAuthors();authors.stream().filter(new Predicate<Author>() {@Overridepublic boolean test(Author author) {return author.getAge()>17;}}.negate()).forEach(author -> System.out.println(author.getAge()));?
6. 方法引用
我們在使用lambda時,如果方法體中只有一個方法的調用的話(包括構造方法),我們可以用方法引用進一步簡化代碼。
6.1 推薦用法
我們在使用lambda時不需要考慮什么時候用方法引用,用哪種方法引用,方法引用的格式是什么。我們只需要在寫完lambda方法發現方法體只有一行代碼,并且是方法的調用時使用快捷鍵嘗試是否能夠轉換成方法引用即可。
當我們方法引用使用的多了慢慢的也可以直接寫出方法引用。
6.2 基本格式
類名或者對象名::方法名
6.3 語法詳解(了解)
6.3.1 引用類的靜態方法
其實就是引用類的靜態方法
格式
類名::方法名
使用前提
如果我們在重寫方法的時候,方法體中只有一行代碼,并且這行代碼是調用了某個類的靜態方法,并且我們把要重寫的抽象方法中所有的參數都按照順序傳入了這個靜態方法中,這個時候我們就可以引用類的靜態方法。
例如:
如下代碼就可以用方法引用進行簡化
List<Author> authors = getAuthors();Stream<Author> authorStream = authors.stream();authorStream.map(author -> author.getAge()).map(age->String.valueOf(age));?
注意,如果我們所重寫的方法是沒有參數的,調用的方法也是沒有參數的也相當于符合以上規則。
優化后如下:
List<Author> authors = getAuthors();Stream<Author> authorStream = authors.stream();authorStream.map(author -> author.getAge()).map(String::valueOf);?
6.3.2 引用對象的實例方法
格式
對象名::方法名
使用前提
如果我們在重寫方法的時候,方法體中只有一行代碼,并且這行代碼是調用了某個對象的成員方法,并且我們把要重寫的抽象方法中所有的參數都按照順序傳入了這個成員方法中,這個時候我們就可以引用對象的實例方法
例如:
List<Author> authors = getAuthors();Stream<Author> authorStream = authors.stream();StringBuilder sb = new StringBuilder();authorStream.map(author -> author.getName()).forEach(name->sb.append(name));?優化后:
List<Author> authors = getAuthors();Stream<Author> authorStream = authors.stream();StringBuilder sb = new StringBuilder();authorStream.map(author -> author.getName()).forEach(sb::append);6.3.4 引用類的實例方法
格式
類名::方法名
使用前提
如果我們在重寫方法的時候,方法體中只有一行代碼,并且這行代碼是調用了第一個參數的成員方法,并且我們把要重寫的抽象方法中剩余的所有的參數都按照順序傳入了這個成員方法中,這個時候我們就可以引用類的實例方法。
例如:
interface UseString{String use(String str,int start,int length);}public static String subAuthorName(String str, UseString useString){int start = 0;int length = 1;return useString.use(str,start,length);}public static void main(String[] args) {subAuthorName("三更草堂", new UseString() {@Overridepublic String use(String str, int start, int length) {return str.substring(start,length);}});}?優化后如下:
public static void main(String[] args) {subAuthorName("三更草堂", String::substring);}6.3.5 構造器引用
如果方法體中的一行代碼是構造器的話就可以使用構造器引用。
格式
類名::new
使用前提
如果我們在重寫方法的時候,方法體中只有一行代碼,并且這行代碼是調用了某個類的構造方法,并且我們把要重寫的抽象方法中的所有的參數都按照順序傳入了這個構造方法中,這個時候我們就可以引用構造器。
例如:
List<Author> authors = getAuthors();authors.stream().map(author -> author.getName()).map(name->new StringBuilder(name)).map(sb->sb.append("-三更").toString()).forEach(str-> System.out.println(str));優化后:
List<Author> authors = getAuthors();authors.stream().map(author -> author.getName()).map(StringBuilder::new).map(sb->sb.append("-三更").toString()).forEach(str-> System.out.println(str));7. 高級用法
基本數據類型優化
我們之前用到的很多Stream的方法由于都使用了泛型。所以涉及到的參數和返回值都是引用數據類型。
即使我們操作的是整數小數,但是實際用的都是他們的包裝類。JDK5中引入的自動裝箱和自動拆箱讓我們在使用對應的包裝類時就好像使用基本數據類型一樣方便。但是你一定要知道裝箱和拆箱肯定是要消耗時間的。雖然這個時間消耗很下。但是在大量的數據不斷的重復裝箱拆箱的時候,你就不能無視這個時間損耗了。
所以為了讓我們能夠對這部分的時間消耗進行優化。Stream還提供了很多專門針對基本數據類型的方法。
例如:mapToInt,mapToLong,mapToDouble,flatMapToInt,flatMapToDouble等。
private static void test27() {List<Author> authors = getAuthors();authors.stream().map(author -> author.getAge()).map(age -> age + 10).filter(age->age>18).map(age->age+2).forEach(System.out::println);authors.stream().mapToInt(author -> author.getAge()).map(age -> age + 10).filter(age->age>18).map(age->age+2).forEach(System.out::println);}并行流
當流中有大量元素時,我們可以使用并行流去提高操作的效率。其實并行流就是把任務分配給多個線程去完全。如果我們自己去用代碼實現的話其實會非常的復雜,并且要求你對并發編程有足夠的理解和認識。而如果我們使用Stream的話,我們只需要修改一個方法的調用就可以使用并行流來幫我們實現,從而提高效率。
parallel方法可以把串行流轉換成并行流。
private static void test28() {Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);Integer sum = stream.parallel() //peek是調試.peek(new Consumer<Integer>() {@Overridepublic void accept(Integer num) {System.out.println(num+Thread.currentThread().getName());}}).filter(num -> num > 5).reduce((result, ele) -> result + ele).get();System.out.println(sum);}也可以通過parallelStream直接獲取并行流對象。
List<Author> authors = getAuthors();authors.parallelStream().map(author -> author.getAge()).map(age -> age + 10).filter(age->age>18).map(age->age+2).forEach(System.out::println);代碼放在資源中,小伙伴可以自己下載



目前對數據庫解決)















