1. 數據類型
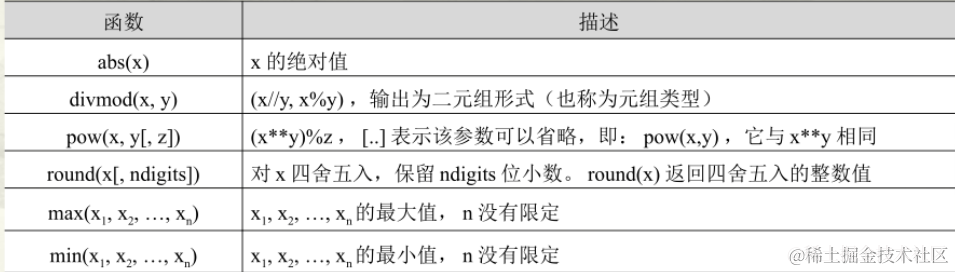
pow(a, b, c) # a^b % c
print("happy {}".format(name))
數字類型包括整數,浮點數,復數
0x9a表示十六進制數(0x,0X開頭表示十六進制)
0b1010,-0B101表示二進制數(0b,0B開頭表示二進制)
0o123,-0O334(0o,0O開頭表示八進制)
執行 print(0xA+0xB) 將會輸出結果 21。在這里,0xA 和 0xB 分別代表十六進制的值,0xA 等于十進制的 10,0xB 等于十進制的 11。所以,0xA + 0xB 相當于 10 + 11,結果為 21。
類型判斷:type()
divmod(5, 2)函數將5除以2,并返回結果的商和余數。(2,1)
round(2345.67892, 3)函數將2345.67892四舍五入到小數點后3位。
// 和 / 的區別:
//是整數除法運算符,也稱為“地板除”。它執行兩個操作數的除法并返回一個整數結果,結果是向下取整的商。例如:
7 // 2 ?# 返回結果為3,因為 7 除以 2 的商是 3
/是浮點除法運算符,它執行兩個操作數的除法并返回一個浮點數結果,結果可以是一個小數。例如:
7 / 2 ?# 返回結果為3.5,因為 7 除以 2 的結果是 3.5
所以,//和/的區別在于返回的結果類型和處理小數的方式。//得到的結果是整數類型(向下取整),而/得到的結果是浮點數類型(精確計算)。
max中比較字符串時按照字典序比較:
按字典序比較是一種字符串之間的比較方法,也稱為字母順序比較。
在按字典序比較中,字符串的每個字符按照它們在字母表中的順序進行比較。比較是從左到右進行的,直到找到兩個字符串中的第一個不同字符為止。
比較的規則如下:
- 首先比較字符串中的第一個字符,如果其中一個字符串的第一個字符在字母表中的位置更靠前,則該字符串被認為是更小的。
- 如果兩個字符串的第一個字符相同,則繼續比較下一個字符,直到找到第一個不同字符為止。
- 如果一個字符串的所有字符都與另一個字符串相同,則較短的字符串被認為是更小的。
例如,按字典序比較字符串’apple’和’banana’,首先比較第一個字符’a’和’b’,因為’a’在字母表中的位置更靠前,所以’apple’被認為是更小的。
not :取反
1 == 1.0 true
Python 輸入默認字符串
執行 print(1, 2, 3, sep=':') 將會輸出結果 1:2:3。在這里,print() 函數接受多個參數,并在輸出它們時默認使用空格作為分隔符。但是,你可以使用 sep 參數來指定自定義的分隔符。在這個例子中,我們將分隔符設置為 :。因此,輸出會將參數之間的分隔符替換為 :,結果為 1:2:3。
執行 int("123.45") 將會引發異常。int() 函數用于將一個字符串或數字轉換為整數類型。然而,在這個例子中,字符串 “123.45” 包含一個小數點,無法直接轉換為整數。因此,調用 int("123.45") 會引發 ValueError 異常。如果你想將字符串 “123.45” 轉換為浮點數,你可以使用 float() 函數來實現,如 float("123.45")。這將返回浮點數值 123.45。
執行 path="C:\Windows\\notepad.exe" 會得到字符串 C:\Windows\notepad.exe 。然后執行 print(path) 將輸出 C:\Windows\notepad.exe 。
然而,如果要在字符串中顯示一個反斜杠本身,需要使用兩個連續的反斜杠 \\ 來表示。因此,定義 path 為字符串 C:\Windows\\notepad.exe,實際上表示路徑為 C:\Windows\notepad.exe,其中兩個連續的反斜杠 \ 被解釋為一個普通的反斜杠 \。當使用 print() 函數打印字符串時,Python會正確地顯示轉義字符和反斜杠,以顯示字符串的實際內容。
在Python中,當你執行 a = b = c = 18 這樣的賦值語句時,實際上是將這三個變量 a、b 和 c 都指向同一個整數對象 18。
這種情況下,Python解釋器會在內存中創建一個名為 18 的整數對象,并讓 a、b 和 c 這三個變量都指向該對象。
a=b=c=18,三個變量被分配到相同的內存空間上。由于整數對象是不可變的,因此沒有必要為每個變量分配獨立的內存空間來存儲相同的整數對象。相反,將它們引用同一個對象是更高效的做法。因此,當你對其中一個變量進行更改時,例如 a = 20,實際上是將 a 變量重新指向一個新的整數對象 20,而 b 和 c 仍然指向原先的整數對象 18。
a = b = c = 10
print(id(a)) # 3108924031504
print(id(b)) # 3108924031504
print(id(c)) # 3108924031504
elif 0.9 > score >= 0.8: 這種寫法是對的。
列表元素最大值 max(list)
2. 切片操作
當我們使用切片操作時,我們可以從一個序列(如字符串、列表或元組)中獲取一個片段(子序列)。
切片操作的語法是sequence[start:end:step]:
sequence是要進行切片操作的序列(如字符串、列表或元組)。start是切片的起始索引,表示要截取的子序列的起始位置。end是切片的結束索引,表示要截取的子序列的結束位置(但不包括該位置的元素)。step是步長(可選參數),用于指定切片時的間隔,默認值為1。
切片操作返回一個新的序列,包含所選范圍內的元素。
下面是切片操作的一些示例:
sequence = 'Hello, World!'
print(sequence[7:]) ?# 從索引7開始到末尾:'World!'
print(sequence[:5]) ?# 從開頭到索引5之前:'Hello'
print(sequence[::2]) ?# 每隔一個字符取一個:'Hlo ol!'
print(sequence[3:9:2]) ?# 從索引3到索引9之間,每隔一個字符取一個:'l,W'
print(sequence[-6:]) ?# 從倒數第6個字符到末尾:'World!'
print(sequence[:-7]) ?# 從開頭到倒數第7個字符之前:'Hello'
print(sequence[::-1]) ?# 反轉整個序列:'!dlroW ,olleH'
print(sequence[:-5:-1]) ?# 從倒數第5個字符到開頭,每隔一個字符取一個:'!roW'
切片操作是根據索引來截取序列的子序列,其中起始索引是包含的,而結束索引是不包含的。











)
)
)



![[操作系統]進程和線程](http://pic.xiahunao.cn/[操作系統]進程和線程)
)
