編碼的發展歷史
ASCII:
ASCII編碼使用7位二進制數表示一個字符,范圍從0到127。每個字符都有一個唯一的ASCII碼值與之對應。例如,大寫字母"A"的ASCII碼是65,小寫字母"a"的ASCII碼是97。
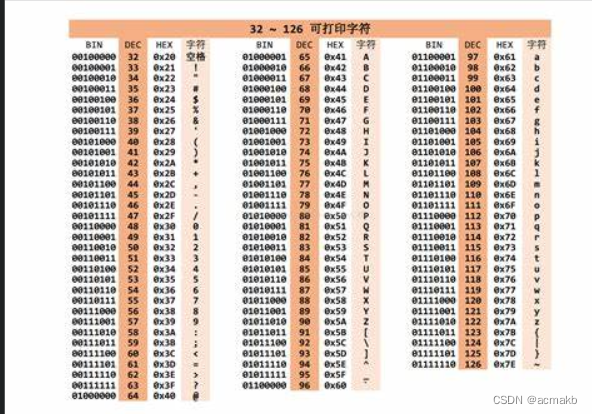
ASCII字符集包括英文字母,數字,標點符號,控制字符(回車,換行等等),128個,最初來源于美國。
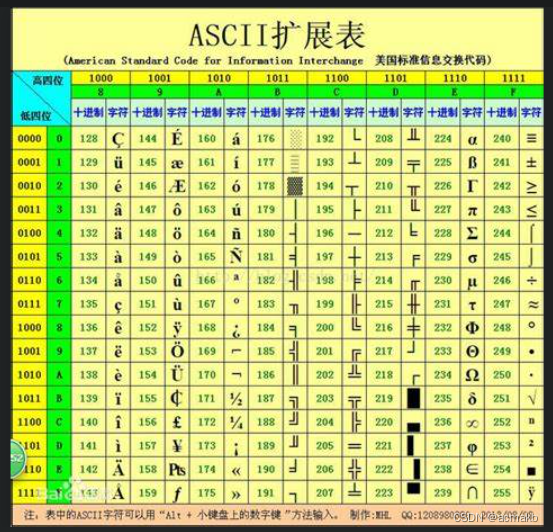
ASCII擴充表:
解決歐洲一些國家字符編碼問題,擴充為256個字符。
但是在中國無法使用,英文漢字太多了,后來就出現了GB2312字符集.
GB2312字符集:
GB2312是中國國家標準局于1980年發布的一種字符集,它是對漢字進行編碼的標準。GB2312字符集主要包括漢字、英文字母、數字和一些常用符號。
GB2312使用兩個字節表示一個漢字字符,(一個字節是8個二進制位的數據單元),其中第一個字節的范圍是0xB0-0xF7,第二個字節的范圍是0xA1-0xFE。這樣的編碼方式可以表示7445個漢字字符。
GB2312主要用于簡體中文的字符編碼,它是早期中國計算機系統中最常用的字符集之一。
print("你".encode("gb2312"))# b'\xc4\xe3'
GBK:
GBK(Guojia Biaozhun Kuozhan)是中國國家標準局于1995年發布的一種字符集,它是對漢字進行編碼的擴展字符集。GBK字符集是在GB2312的基礎上進行擴展而來,可以表示更多的漢字字符。
GBK使用雙字節編碼,與GB2312相同,每個字符使用兩個字節來表示。GBK字符集包括GB2312中的所有字符,并添加了大量的繁體中文字符、生僻字和其它語種的字符。通過這種方式,GBK可以表示超過21000個漢字和符號。
GBK字符集被廣泛應用于簡體中文和繁體中文環境中,特別是在早期的計算機系統和中文操作系統中。然而,隨著時間的推移和技術的發展,GBK也逐漸被更先進的字符集如GB18030和Unicode所取代,這些字符集能夠更好地支持更廣泛的字符和語言。
需要注意的是,GBK和GB2312之間的編碼兼容性非常高,大多數GB2312編碼的字符在GBK中仍然可以正確解析和顯示。
print("你".encode('gbk')) # # b'\xc4\xe3'
問題出現:
問題:不能每一個國家都創建一個字符集吧,在進行信息交流的時候就出現了亂碼的問題.
Unicode:
Unicode是一種國際標準字符集,旨在為世界上所有的字符提供唯一的標識符。它定義了字符的編碼方式,使不同國家和地區的計算機能夠交換和處理多語言文本。
Unicode字符集包含了幾乎所有的已知字符,包括不同語言的字符、標點符號、數學符號、技術符號、貨幣符號等。其編碼空間非常大,總共可以表示超過1.1百萬個字符。
Unicode采用統一的編碼方案,即每個字符分配一個唯一的數字標識符,稱為碼點(code point)。常用的表示方式是使用十六進制表示碼點,例如字母"A"的碼點是U+0041,漢字"中"的碼點是U+4E2D。
為了表示Unicode字符,需要使用不同的編碼方案,其中最常見的是UTF-8、UTF-16和UTF-32。這些編碼方案根據字符的碼點將其轉換為不同長度的字節序列,以便在計算機系統中存儲和傳輸。
Unicode的出現解決了以往字符編碼標準的局限性,使得不同語言和文化之間的文本處理更加方便和統一。它被廣泛應用于現代計算機系統、操作系統、編程語言和互聯網標準中,成為國際化文本處理的基礎。
UTF-8:
UTF-8(Unicode Transformation Format-8)是一種常用的Unicode字符編碼方案之一。它是一種可變長度的字符編碼,能夠表示Unicode字符集中的所有字符。
UTF-8使用8位(1個字節)作為基本的編碼單元,采用了一種變長的編碼方式。具體地說,UTF-8根據字符的碼點范圍將其轉換為1至4個字節的字節序列。
UTF-8的優勢在于它既能夠完全兼容ASCII字符,又能夠表示任意Unicode字符,同時保持了文本數據的緊湊性和兼容性。因此,UTF-8成為了互聯網上最常用的字符編碼方案之一,被廣泛應用于網頁、電子郵件、數據庫存儲以及各種文本文件的處理中。
print('你'.encode('utf-8')) #b'\xe4\xbd\xa0'





)





(D前綴和+貪心加血量))







