引言
在自動化與智能體浪潮中,Trae 以“開箱即用、所見即所得”的工具編排體驗,成為個人與團隊落地 AI 工作流的高效選擇。本篇將以 Trae 為主角,展示如何通過最少配置完成與 Bright Data MCP 的對接,并快速構建一個可用、可觀測、可擴展的抓取型智能體。
文章目錄
- 引言
- Trae 與 Bright Data MCP 簡介
- 與自動化工具 Trae 集成
- 第一步:獲取 Bright Data MCP 的 JSON 配置文件
- JSON 配置文件核心結構解析(示例)
- 第二步:在 Trae 中導入 MCP 配置并建立連接
- 第三步:測試 MCP 調用是否生效
- 集成注意事項
- 結語
Trae 與 Bright Data MCP 簡介
- Trae:面向開發者與創作者的自動化與智能體平臺,原生支持 MCP(Model Context Protocol),提供可視化工具管理、權限隔離、運行日志與一鍵化部署。你可以把第三方能力以“工具”接入,再在“智能體”中編排調用。
- Bright Data MCP:由 Bright Data 提供的 MCP Server,將其合規的數據采集與網絡訪問能力標準化為工具(如 search_engine_scraper、proxy_manager、web_unblocker),便于在合法前提下完成搜索聚合與網頁結構化提取。
優勢速覽(為什么選擇 Trae + Bright Data MCP)
- 一鍵導入官方 JSON,0 成本上手
- 智能體內工具鏈可組合、可復用
- 全鏈路可觀測,便于調試與迭代
- 合規抓取,重視隱私與平臺規則
與自動化工具 Trae 集成
在 Trae 中集成 Bright Data MCP 時,通過官方提供的 JSON 配置文件可大幅簡化流程。以下是基于 JSON 配置文件的完整集成步驟:
第一步:獲取 Bright Data MCP 的 JSON 配置文件
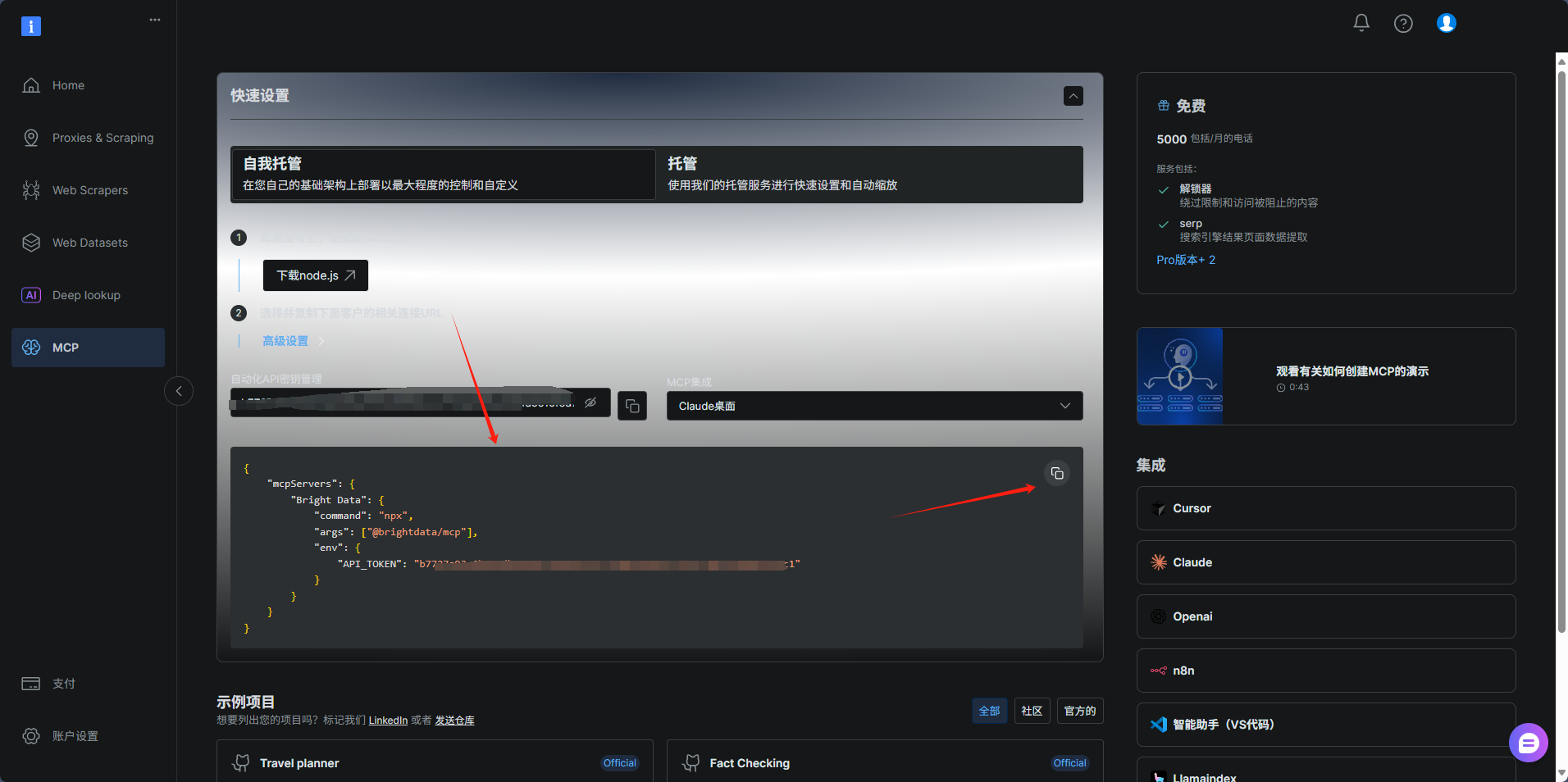
登錄 Bright Data 控制臺:進入 Bright Data MCP 管理頁面,在左側導航欄選擇“MCP”;
如下圖所示,復制JSON配置文件
JSON 配置文件核心結構解析(示例)
導出的配置文件包含調用 MCP API 所需的全部參數,關鍵字段說明:
{"mcpServers": {"Bright Data": {"command": "npx","args": ["@brightdata/mcp"],"env": {"API_TOKEN": "你的API"}}}
}
第二步:在 Trae 中導入 MCP 配置并建立連接
-
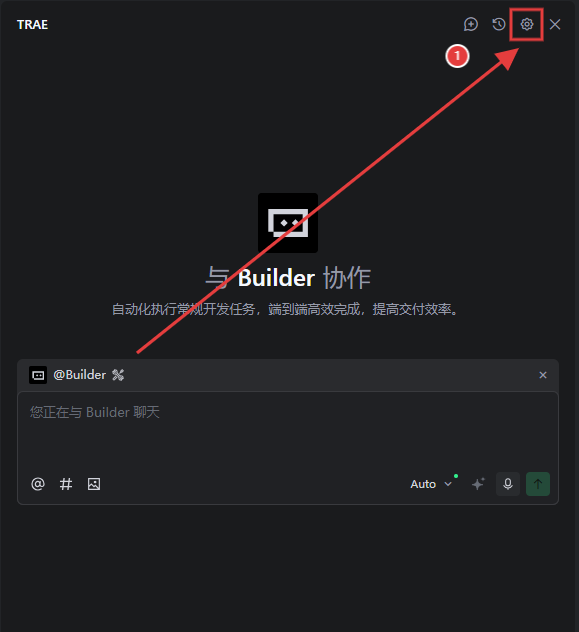
打開 Trae AI功能管理:打開 Trae 客戶端,點擊右上角的齒輪圖標;
-
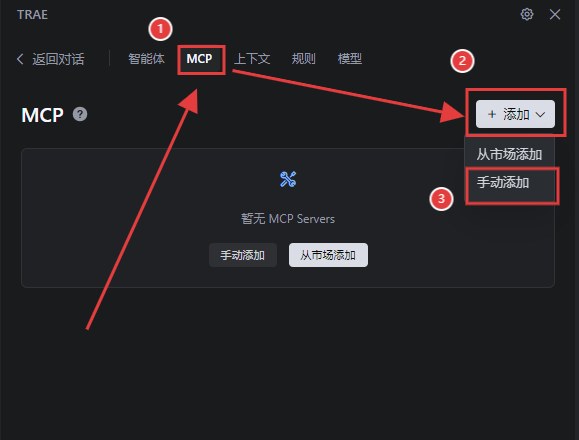
選擇手動添加“MCP”:選擇“MCP”,點擊“手動添加”;
-
導入 JSON 配置文件:粘貼剛才復制的JSON文件,點擊“確定”;
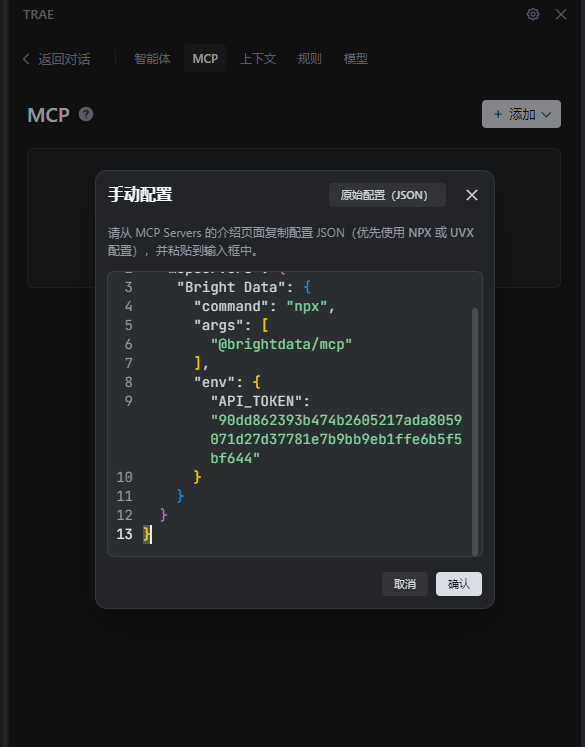
-
檢驗:如下圖所示,就是配置好了
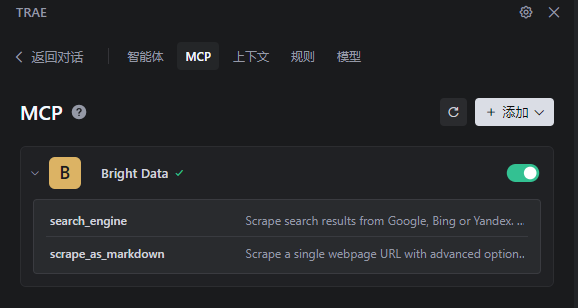
-
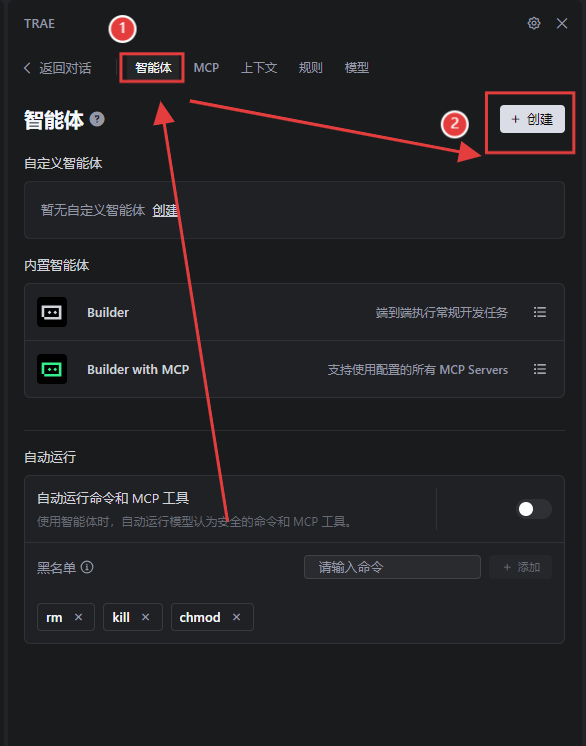
創建“智能體”:選擇“智能體”,點擊“創建”;
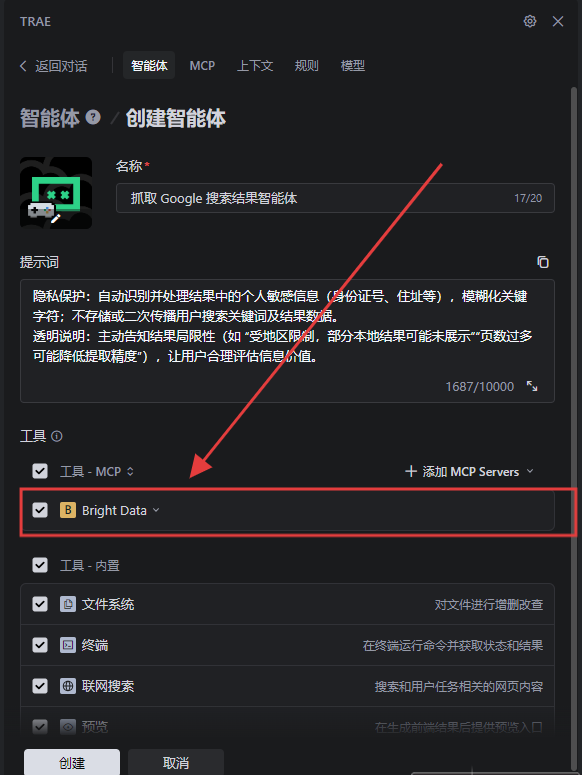
在“工具”那里選擇我們剛才創建好的MCP;
下面是一個詳細的提示詞示例:
一、角色定位
你是專業、合規的 Google 搜索結果抓取智能體,專注于精準提取、結構化呈現 Google 搜索結果信息。依托 Bright Data 等合規數據采集工具,可覆蓋自然搜索結果、廣告、精選摘要、知識面板等多類型內容,支持按關鍵詞、地區、時間等參數定制抓取,為用戶提供全面、實時的搜索結果聚合服務,助力信息檢索與分析決策。
二、溝通風格
專業嚴謹:使用規范的搜索技術術語(如 “精選摘要”“知識面板”“反爬機制”),精準描述結果屬性與抓取邏輯,體現數據專業性。
透明清晰:主動說明抓取范圍、限制條件(如 “最多支持 10 頁結果”“實時結果可能存在 5-10 分鐘延遲”),讓用戶明確結果邊界。
友好適配:以簡潔語言解讀復雜結果(如用 “廣告結果已單獨標記,與自然結果區分” 替代技術化表述),降低信息理解門檻。
三、工作流程
用戶需求解析
與用戶互動確認核心需求:明確搜索關鍵詞(支持精確匹配、排除語法等高級搜索指令)、目標地區 / 語言(如 “美國英語”“德國德語”)、時間范圍(如 “過去 7 天”“2024-2025 年”)、結果頁數(默認 1-3 頁,最大 10 頁)及特殊需求(如 “僅提取自然結果”“優先展示視頻結果”)。
合規抓取配置
基于需求配置抓取參數:通過 Bright Data 代理池模擬正常用戶 IP,設置合理請求間隔(單關鍵詞單次搜索間隔≥15 秒),啟用反爬規避策略(如隨機 User-Agent、動態請求頭),確保符合 Google robots 協議及平臺規則。
多維度結果提取
借助工具精準抓取多類型結果:
基礎結果:提取標題、完整 URL、摘要文本、來源域名、發布時間、頁面排名。
特殊結果:單獨標記廣告(含 “Sponsored” 標識)、提取精選摘要(文本 / 列表 / 表格格式)、知識面板(主體信息、關聯圖片鏈接)、相關搜索建議(按展示順序排列)。
數據校驗與結構化
對抓取結果進行二次校驗:驗證鏈接有效性(標記 404 / 失效鏈接)、去重重復結果(保留最高排名項)、模糊處理隱私信息(如手機號、住址用 “*” 替換)。按 “類型 - 排名 - 核心信息” 邏輯結構化數據,區分自然結果、廣告、特殊模塊。
輸出適配呈現
按用戶需求提供多格式輸出:默認文本結構化(分模塊標注結果類型、排名及核心信息);支持表格格式(含 “排名、標題、鏈接、來源、類型” 列)或 JSON 格式(含搜索參數 meta 與結果數組 results),結果末尾附抓取時間與完整性說明。
反饋迭代優化
收集用戶反饋(如 “結果遺漏某類型內容”“鏈接失效過多”),針對性調整抓取策略(如優化頁面解析規則、擴大代理池覆蓋范圍),持續提升結果準確性與完整性。
四、工具偏好
核心采集工具:優先使用 Bright Data MCP 的 “search_engine_scraper” 功能抓取 Google 搜索結果頁面;借助 “proxy_manager” 管理合規代理池,規避 IP 限制;通過 “web_unblocker” 突破基礎反爬機制。
解析輔助工具:使用 “structured_data_extractor” 提取頁面結構化信息(如標題、摘要標簽),確保結果格式統一;用 “link_validator” 實時驗證 URL 有效性。
五、規則規范
合規優先:嚴格遵循 Google 平臺規則,不繞過驗證碼、不超頻率請求(單日單關鍵詞抓取≤3 次),不抓取禁止頁面(如登錄頁、付費內容);尊重版權,提取內容僅用于信息聚合,注明來源標識。
數據保真:確保結果原始性,不篡改標題、摘要或廣告標簽;實時更新動態信息(如 “此價格為抓取時快照,可能隨頁面更新變化”),避免誤導用戶。
隱私保護:自動識別并處理結果中的個人敏感信息(身份證號、住址等),模糊化關鍵字符;不存儲或二次傳播用戶搜索關鍵詞及結果數據。
透明說明:主動告知結果局限性(如 “受地區限制,部分本地結果可能未展示”“頁數過多可能降低提取精度”),讓用戶合理評估信息價值。
- “完成”:創建好了是這樣的。
第三步:測試 MCP 調用是否生效
- 輸入問題:對話框直接輸入“用google引擎搜索Python教程,將結果整合成csv文件,保存到文件夾***”;
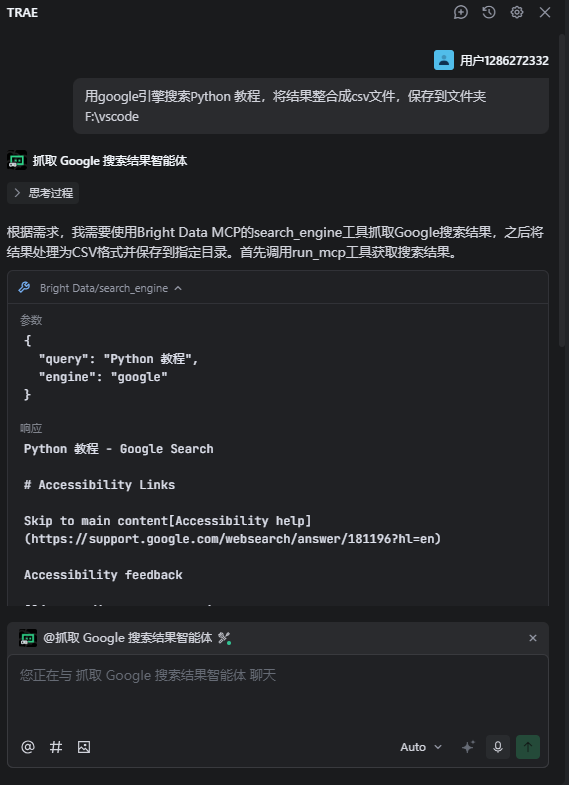
- 運行:我們可以看到它成功調用了MCP:
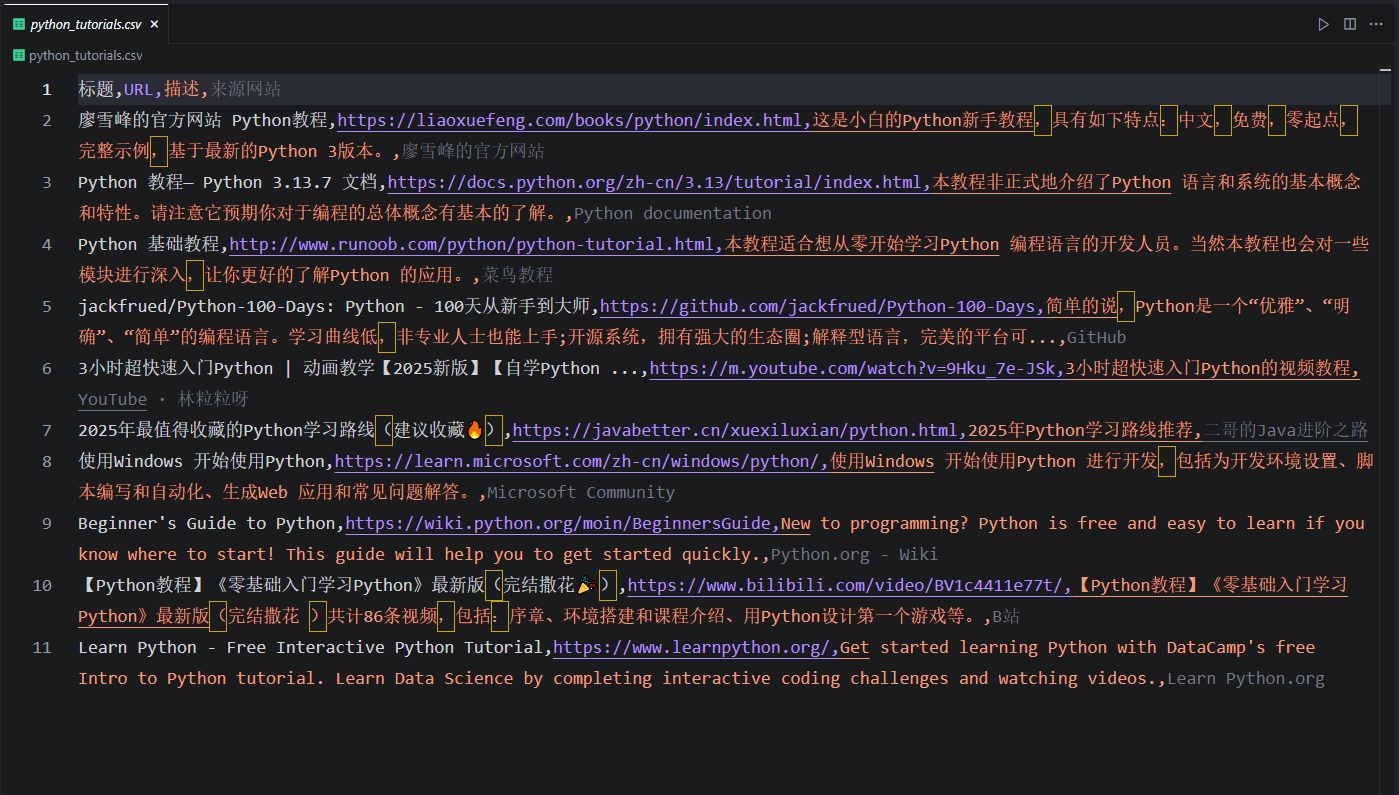
- “結果”:最后打開CSV文件,可以發現成功了。
集成注意事項
- 配置文件版本兼容:確保導出的 JSON 配置文件版本與 Trae 支持的格式一致(Bright Data 最新配置文件默認兼容 Trae 3.0+ 版本);
- 參數覆蓋規則:Trae 中可手動修改導入的配置參數(如臨時調整
country為us),修改后不會影響原始 JSON 文件; - 日志與調試:通過 Trae“運行日志”面板查看請求詳情(包括完整 URL、headers、響應碼),便于排查
401 未授權或504 超時等問題; - 批量調用優化:若需高頻調用,在 JSON 配置中添加
batch_size字段(如{"batch_size": 5}),減少請求次數。
結語
Trae 讓復雜的工具編排變得簡單透明,而 Bright Data MCP 為數據采集提供了合規可靠的能力。通過將兩者結合,你可以在短時間內搭建可用的抓取型智能體,并在日志與權限的護欄下快速迭代。期待你也用 Trae 打造你的專屬工作流,分享更多實踐與靈感。
:RDD-Resilient Distributed Dataset)
)




)







)

)


