文章目錄
- 自然語言處理(NLP)
- 一、什么是自然語言處理(NLP)?
- 二、NLP 的核心目標
- 三、NLP 的主要應用方向(應用場景)
- 四、NLP 的基本概念
- 五、NLP 的基本處理流程
- 1. 文本預處理
- 2. 特征表示
- 3. 模型選擇與訓練
- 4. 模型評估
- 5. 部署與應用
- 六、NLP 的關鍵技術演進
- NLP 特征工程詳解
- 一、傳統 NLP 中的特征工程
- 1. 獨熱編碼(One-Hot Encoding)
- 2. TF-IDF
- 3. N-Grams 特征
- 二、詞向量
- 三、深度學習中的 NLP 特征輸入
- 1. 詞嵌入與分布式表示
- 1.1 傳統編碼的局限性
- 1.2 分布式表示
- 2. 稠密編碼(特征嵌入)
- 3. 詞嵌入算法
- 3.1 EmbeddingLayer
- 實現步驟
- 3.2 word2vec
- CBOW 連續詞袋模型
- Skip-gram
- Gensim 中 Word2Vec 使用
自然語言處理(NLP)
一、什么是自然語言處理(NLP)?
自然語言處理(Natural Language Processing,簡稱 NLP)是人工智能(AI)的一個分支,致力于讓計算機能夠理解、生成、分析和處理人類語言(如中文、英文等)。
簡單說:讓機器“聽懂”和“會說”人話。
二、NLP 的核心目標
| 目標 | 說明 |
|---|---|
| 理解語言 | 從文本中提取語義、情感、意圖等信息 |
| 生成語言 | 讓機器寫出通順、有邏輯的句子或文章 |
| 語言轉換 | 如機器翻譯、語音識別與合成 |
| 交互能力 | 實現人機對話,如智能客服、語音助手 |
三、NLP 的主要應用方向(應用場景)
| 應用 | 說明 | 實例 |
|---|---|---|
| 文本分類 | 判斷文本屬于哪一類 | 垃圾郵件識別、新聞分類 |
| 情感分析 | 分析文本的情感傾向 | 商品評論是好評還是差評 |
| 命名實體識別(NER) | 識別文本中的人名、地名、組織等 | “馬云在杭州創立阿里巴巴” → 馬云(人名)、杭州(地名)、阿里巴巴(組織) |
| 機器翻譯 | 將一種語言自動翻譯成另一種 | 谷歌翻譯、DeepL |
| 問答系統 | 根據問題給出答案 | 智能客服、Siri、ChatGPT |
| 文本生成 | 自動生成文章、摘要、對話 | 寫作助手、AI寫詩、新聞摘要 |
| 語音識別與合成 | 語音轉文字 / 文字轉語音 | 語音輸入法、智能音箱 |
| 信息抽取 | 從文本中提取結構化信息 | 從簡歷中提取姓名、學歷、工作經驗 |
| 文本摘要 | 將長文本壓縮為短摘要 | 新聞摘要、論文摘要 |
| 對話系統 | 實現人機對話 | 智能客服、聊天機器人 |
四、NLP 的基本概念
| 概念 | 解釋 |
|---|---|
| 分詞(Tokenization) | 將句子切分成詞語或子詞(中文需分詞,英文按空格) |
| 詞性標注(POS) | 標注每個詞的詞性(名詞、動詞、形容詞等) |
| 句法分析 | 分析句子的語法結構(主謂賓) |
| 語義分析 | 理解詞語和句子的含義 |
| 停用詞(Stop Words) | 無實際意義的詞(如“的”、“了”、“is”、“the”),常被過濾 |
| 詞向量(Word Embedding) | 將詞語表示為向量,使語義相近的詞向量也相近(如 Word2Vec、GloVe) |
| 上下文表示 | 考慮詞語在句子中的上下文(如 BERT、Transformer) |
| 預訓練模型 | 先在大規模語料上訓練,再在具體任務上微調(如 BERT、RoBERTa、ChatGLM) |
五、NLP 的基本處理流程
一個典型的 NLP 任務處理流程如下:
1. 文本預處理
- 分詞(中文用 jieba、英文用 split/spaCy)
- 去除標點、停用詞、數字等
- 轉小寫(英文)
- 詞干提取 / 詞形還原(英文)
2. 特征表示
- One-Hot 編碼:簡單但稀疏
- 詞袋模型(Bag of Words, BoW)
- TF-IDF:衡量詞的重要性
- 詞向量(Word2Vec、FastText)
- 上下文向量(BERT、Transformer)
3. 模型選擇與訓練
- 傳統方法:樸素貝葉斯、SVM、CRF
- 深度學習:RNN、LSTM、GRU、Transformer、BERT
- 預訓練 + 微調(主流范式)
4. 模型評估
- 分類任務:準確率、精確率、召回率、F1
- 生成任務:BLEU、ROUGE、METEOR
- 語義任務:相似度、人工評估
5. 部署與應用
- 導出模型(ONNX、TorchScript)
- 集成到 Web、App、API 服務中
六、NLP 的關鍵技術演進
| 階段 | 技術 | 特點 |
|---|---|---|
| 1990s | 規則 + 統計方法 | 依賴人工規則和特征工程 |
| 2000s | 機器學習(SVM、CRF) | 使用 TF-IDF 等特征 |
| 2013~2018 | 深度學習(RNN、CNN) | 自動學習特征,但難處理長依賴 |
| 2018~至今 | 預訓練模型(BERT、GPT) | 基于 Transformer,上下文理解強,效果卓越 |
🔥 當前主流:Transformer + 預訓練 + 微調
NLP 特征工程詳解
特征工程是指將原始文本轉換為機器學習模型可理解的數值型輸入的過程。在 NLP 中,特征工程是模型性能的關鍵。
一、傳統 NLP 中的特征工程
1. 獨熱編碼(One-Hot Encoding)
每個詞被映射為一個二進制向量,向量長度等于類別總數,僅有一個位置為1(對應詞的索引),其余為0。
示例
詞表:["我", "愛", "學習", "AI"] → 大小為 4
- “我” →
[1, 0, 0, 0] - “愛” →
[0, 1, 0, 0]
優點:
- 消除順序偏差:避免整數編碼(如 0、1、2)引入的虛假順序關系。
- 簡單直觀:易于實現,適用于線性模型、樹模型等。
缺點:
- 維度爆炸:類別多時會導致高維稀疏向量(如詞匯表有10萬詞時,向量長度為10萬)。
- 稀疏性:大部分位置為0,計算和存儲效率低。
- 忽略語義:無法捕捉詞與詞之間的關聯(如“北京”和“天安門”可能相關)。
2. TF-IDF
改進版詞袋模型,衡量一個詞對文檔的重要性。
-
TF:詞在文檔中出現的頻率
TF(t,d)=詞?t在文檔?d中出現的次數文檔?d的總詞數\text{TF}(t, d) = \frac{\text{詞 } t \text{ 在文檔 } d \text{ 中出現的次數}}{\text{文檔 } d \text{ 的總詞數}} TF(t,d)=文檔?d?的總詞數詞?t?在文檔?d?中出現的次數?
-
IDF:log(總文檔數 / 包含該詞的文檔數),越少見的詞,IDF 越高
IDF(t,D)=log?(N1+包含詞?t的文檔數)\text{IDF}(t, D) = \log \left( \frac{N}{1 + \text{包含詞 } t \text{ 的文檔數}} \right) IDF(t,D)=log(1+包含詞?t?的文檔數N?)
-
權重 = TF × IDF
【示例】
假設我們有一個小型語料庫,包含 3 個文檔(比如 3 篇新聞):
- D1:
the cat sat on the mat - D2:
the dog ran on the road - D3:
the cat and the dog are friends
我們的目標是:計算每個詞在每篇文檔中的 TF-IDF 值,以衡量其重要性。
第一步:構建詞表
將所有文檔中的詞提取出來,去重后得到詞表:
{the, cat, sat, on, mat, dog, ran, road, and, are, friends}
共 11 個詞。
第二步:計算 TF(詞頻)
公式:
TF(t,d)=詞?t在文檔?d中出現的次數文檔?d的總詞數\text{TF}(t, d) = \frac{\text{詞 } t \text{ 在文檔 } d \text{ 中出現的次數}}{\text{文檔 } d \text{ 的總詞數}} TF(t,d)=文檔?d?的總詞數詞?t?在文檔?d?中出現的次數?
我們先統計每個文檔的總詞數:
- D1: 6 個詞
- D2: 6 個詞
- D3: 7 個詞
計算部分詞的 TF(只展示關鍵詞)
| 詞 | D1 | D2 | D3 |
|---|---|---|---|
| the | 2/6 = 0.333 | 2/6 = 0.333 | 2/7 = 0.286 |
| cat | 1/6 = 0.167 | 0 | 1/7 = 0.143 |
| dog | 0 | 1/6 = 0.167 | 1/7 = 0.143 |
| mat | 1/6 = 0.167 | 0 | 0 |
| road | 0 | 1/6 = 0.167 | 0 |
其他詞類似計算(如 sat, ran 等)
第三步:計算 IDF(逆文檔頻率)
公式:
IDF(t,D)=log?(N1+包含詞?t的文檔數)\text{IDF}(t, D) = \log \left( \frac{N}{1 + \text{包含詞 } t \text{ 的文檔數}} \right) IDF(t,D)=log(1+包含詞?t?的文檔數N?)
- N=3(總文檔數)
- 加 1 是為了防止分母為 0(拉普拉斯平滑)
我們計算每個詞的 IDF:
| 詞 | 包含該詞的文檔數 | IDF 計算 | IDF 值(保留3位) |
|---|---|---|---|
| the | 3 | log?(3/(1+3))=log?(0.75)log(3/(1+3))=log(0.75) | -0.288 |
| cat | 2 | log?(3/(1+2))=log?(1.0)log(3/(1+2))=log(1.0) | 0.000 |
| dog | 2 | log?(3/3)=log?(1.0)log(3/3)=log(1.0) | 0.000 |
| sat | 1 | log?(3/2)=log?(1.5)log(3/2)=log(1.5) | 0.405 |
| mat | 1 | log?(3/2)=log?(1.5)log(3/2)=log(1.5) | 0.405 |
| ran | 1 | log?(3/2)log(3/2) | 0.405 |
| road | 1 | log?(3/2)log(3/2) | 0.405 |
| and | 1 | log?(3/2)log(3/2) | 0.405 |
| are | 1 | log?(3/2)log(3/2) | 0.405 |
| friends | 1 | log?(3/2)log(3/2) | 0.405 |
| on | 2 | log?(3/3)=log?(1.0)log(3/3)=log(1.0) | 0.000 |
注意:
the出現在所有文檔中,IDF 為負,說明它不具區分性,反而可能應被降權。簡單說:
- 一個詞出現的文檔越多 → 越常見 → 越不重要 → IDF 值越低
- 一個詞出現的文檔越少 → 越稀有 → 越可能具有區分性 → IDF 值越高
第四步:計算 TF-IDF
公式:
TF-IDF(t,d)=TF(t,d)×IDF(t)
我們以 D1 為例,計算其中幾個詞的 TF-IDF:
文檔 D1: the cat sat on the mat
| 詞 | TF (D1) | IDF | TF-IDF (D1) |
|---|---|---|---|
| the | 0.333 | -0.288 | 0.333 × (-0.288) ≈ -0.096 |
| cat | 0.167 | 0.000 | 0.167 × 0.000 = 0.000 |
| sat | 0.167 | 0.405 | 0.167 × 0.405 ≈ 0.068 |
| on | 0.167 | 0.000 | 0.167 × 0.000 = 0.000 |
| mat | 0.167 | 0.405 | 0.167 × 0.405 ≈ 0.068 |
解讀:
the雖然出現頻繁,但 IDF 為負,整體貢獻為負,說明它不重要。cat出現一次,但出現在 2 篇文檔中,IDF=0,重要性被中和。sat和mat只在 D1 中出現,IDF > 0,因此 TF-IDF 值較高,說明它們是 D1 的“關鍵詞”。
結論:
- 文檔頻率和樣本語義貢獻程度呈反相關
- 文檔頻率和逆文檔頻率呈反相關
- 逆文檔頻率和樣本語義貢獻度呈正相關
3. N-Grams 特征
N-Grams 是指文本中連續出現的 N 個詞(或字符)的組合,是自然語言處理(NLP)中一種重要的特征表示方法。
簡單理解:將句子切分為長度為 N 的“滑動窗口”片段。
【示例】
句子:“我愛機器學習”
根據 N 的取值不同,N-Grams 可分為:
| 類型 | 名稱 | 示例(句子:“我愛機器學習”) |
|---|---|---|
| 1-Gram | Unigram(一元語法) | 我,愛,機器,學習 |
| 2-Gram | Bigram(二元語法) | 我愛,愛機器,機器學習 |
| 3-Gram | Trigram(三元語法) | 我愛機器,愛機器學習 |
| 4-Gram | Four-gram | (更長的組合,依此類推) |
通常 N 不會太大(一般 ≤ 5),否則特征數量爆炸。
N-Grams 的作用:
- 捕捉局部詞序信息
- 傳統詞袋模型(Bag of Words)完全忽略詞序。
- N-Grams 保留了詞語的相鄰關系,能區分:“貓怕狗” vs “狗怕貓”
- 提升模型對語言結構的理解
- Bigram 可以學習“通常哪些詞會連在一起”
- 例如:“深度學習”比“學習深度”更常見
- 用于語言模型(Language Model)
- 預測下一個詞的概率
- 廣泛應用于拼寫糾錯、語音識別、機器翻譯等。
通常情況下,可以將n-grams 與 TF-IDF 相結合,在保留詞語搭配和詞序信息的同時,通過 TF-IDF 權重突出關鍵短語、抑制常見無意義組合。結合的過程基本上是先生成 n-grams,然后對這些 n-grams 計算 TF-IDF 權重。
- n-grams:提供結構信息(詞序、搭配)
- TF-IDF:提供重要性權重(突出關鍵詞,抑制常見組合)
【示例】
文檔1(正面):這部電影真的很棒
文檔2(負面):這部電影并不棒
僅用 unigram + TF-IDF 的問題:
- 兩篇都包含:“這”、“部”、“電影”、“很”、“棒”
- “并不” vs “真的” 差異被忽略 → 模型難區分情感
加入 bigram 后:
| 文檔 | Bigrams |
|---|---|
| 正面 | 這部, 部電, 電影, 影真, 真的, 的很, 很棒 |
| 負面 | 這部, 部電, 電影, 影并, 并不, 不棒 |
→ “真的很棒” vs “并不棒” 被區分開!
再用 TF-IDF 加權后,“很棒”可能在語料中少見 → IDF 高 → 權重高,“的”等常見組合權重低。
傳統特征工程手工成本高、語義表達弱、泛化能力差,難以應對復雜的語言理解任務。
因此現代 NLP 轉向 詞向量 和 深度學習(如 BERT)
二、詞向量
詞向量(Word Embedding)是將自然語言中的詞語映射為一個低維、稠密的實數向量的技術。
它使得語義相近的詞在向量空間中距離也相近。
在自然語言處理(NLP)中,計算機無法直接理解文字。為了讓機器能處理“貓”、“喜歡”、“跑步”這樣的詞,我們需要把它們轉換成數字形式。這就是詞向量)的作用。
簡單說:
詞向量就是把一個詞變成一串數字(向量),讓計算機能進行數學計算,同時保留詞語的語義信息。
單個詞在預定義的向量空間中被表示為實數向量,每個單詞都映射到一個向量。舉個例子,比如在一個文本中包含“貓”“狗”“愛情”等若干單詞,而這若干單詞映射到向量空間中,“貓”對應的向量為(0.1 0.2 0.3),“狗”對應的向量為(0.2 0.2 0.4),“愛情”對應的映射為(-0.4 -0.5 -0.2)(本數據僅為示意)。像這種將文本X{x1,x2,x3,x4,x5……xn}映射到多維向量空間Y{y1,y2,y3,y4,y5……yn },這個映射的過程就叫做詞嵌入。
我們計算“貓”和“狗”的余弦相似度,發現它們很接近;而“貓”和“愛情”距離較遠。
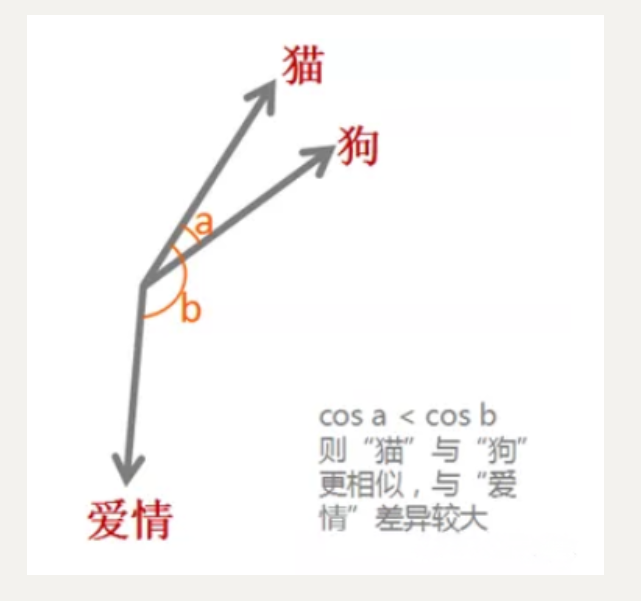
? 此外,詞嵌入還可以做類比,比如:
vec("國王") - vec("男人") + vec("女人") ≈ vec("女王")
這說明詞向量不僅能表示詞義,還能捕捉語法和語義關系!
再比如:
- “北京” - “中國” + “法國” ≈ “巴黎”
- “跑步” - “走” + “飛” ≈ “飛行”
三、深度學習中的 NLP 特征輸入
1. 詞嵌入與分布式表示
1.1 傳統編碼的局限性
- 獨熱編碼(One-Hot)
每個詞表示為高維稀疏向量(如10000維詞表中,每個詞僅一個維度為1,其余為0)。
缺陷:- 維度災難:10000詞表需10000維向量,計算成本高。
- 無法捕捉語義關系(如"king"和"queen"的距離與其他詞無區別)。
- N-gram與TF-IDF
通過統計局部共現詞或詞頻構建特征,但無法解決語義相似性和動態上下文感知問題。
1.2 分布式表示
- 核心思想:
將離散詞映射到低維連續向量空間(如300維),通過上下文學習詞的語義關系。
優勢:- 低維度(如300維 vs 10000維獨熱編碼)。
- 語義相似性(如"king - man + woman ≈ queen")。
- 可微學習(通過反向傳播優化向量表示)。
- 典型應用:
- Word2Vec(CBOW/Skip-gram)捕捉類比關系。
- GloVe 利用全局共現矩陣生成詞向量。
2. 稠密編碼(特征嵌入)
將離散特征(詞、標簽、位置等)映射到低維稠密向量,通過神經網絡參數化學習。
特點:
- 低維度:將高維稀疏表示(如 10,000 維)壓縮到低維(如 100 維)。
- 語義相似性:向量距離反映對象間的語義關系(如 “king” 和 “queen” 的距離較近)。
- 可微學習:通過神經網絡參數化學習,支持反向傳播優化。

3. 詞嵌入算法
計算機無法直接處理文字,比如:
句子:"我 愛 學習"
如果我們用 One-Hot 編碼:
- “我” →
[1, 0, 0] - “愛” →
[0, 1, 0] - “學習” →
[0, 0, 1]
問題來了:
- 向量維度等于詞表大小,高維稀疏
- 所有詞之間“距離相等”,沒有語義信息
- “我” 和 “學習” 完全無關,但模型不知道它們常一起出現
所以我們需要更聰明的方式 —— Embedding Layer。
3.1 EmbeddingLayer
Embedding Layer 是一個可訓練的神經網絡層,它將詞的索引(ID) 映射為一個固定維度的稠密向量。
本質是一個可訓練的矩陣 E∈RV×d,其中 V 是詞表大小,d是嵌入維度。
怎么得到詞向量?
比如我們的目標是希望神經網絡發現如下這樣的規律:已知一句話的前幾個字,預測下一個字是什么,于是有了NNLM 語言模型搭建的網絡結構圖:

具體怎么實施呢?先用最簡單的方法來表示每個詞,one-hot 表示為︰
dog=(0,0,0,0,1,0,0,0,0,…);
cat=(0,0,0,0,0,0,0,1,0,…) ;
eat=(0,1,0,0,0,0,0,0,0,…)

可是 one-hot 表示法有諸多的缺陷,還是稠密的向量表示更好一些,那么怎么轉換呢?加一個矩陣映射一下就好!

映射之后的向量層如果單獨拿出來看,還有辦法找到原本的詞是什么嗎?
One-hot表示法這時候就作為一個索引字典了,可以通過映射矩陣對應到具體的詞向量。

這個層內部維護一個矩陣:E∈RV×d
一、詞表(V)
-
詞表就是你模型認識的所有詞的集合。
-
比如你的語料中只出現過這些詞:
["我", "愛", "學習", "AI", "今天", "天氣", "好"]那么詞表大小 V = 7 。
-
每個詞會被分配一個唯一的編號(索引):
我 → 0 愛 → 1 學習 → 2 AI → 3 今天 → 4 天氣 → 5 好 → 6
二、嵌入維度(d)
-
嵌入維度 d 是指每個詞要用多少個數字(即向量的長度)來表示。
-
比如 d = 4 ,那么每個詞會被表示成一個 4 維的向量,像這樣:
"我" → [0.2, -0.5, 0.8, 0.1] "愛" → [0.6, 0.3, 0.4, -0.2] ...
三、嵌入矩陣 E
- 為了高效存儲和計算,我們把所有詞的向量堆在一起,形成一個大矩陣,叫做 嵌入矩陣 E。它的形狀是 V×d:
- 有 V 行(每行對應一個詞)
- 有 d 列(每列對應向量的一個維度)
【示例】
V = 3 (詞表:[“貓”, “狗”, “牛奶”])
d = 4 (每個詞用 4 個數字表示)
嵌入矩陣 E 長這樣:
E=[0.1?0.30.80.5←“貓”的向量0.20.40.70.6←“狗”的向量?0.10.90.20.3←“牛奶”的向量]∈R3×4E = \begin{bmatrix} 0.1 & -0.3 & 0.8 & 0.5 \\ \leftarrow \text{“貓”的向量} \\ 0.2 & 0.4 & 0.7 & 0.6 \\ \leftarrow \text{“狗”的向量} \\ -0.1 & 0.9 & 0.2 & 0.3 \\ \leftarrow \text{“牛奶”的向量} \end{bmatrix} \in \mathbb{R}^{3 \times 4} E=?0.1←“貓”的向量0.2←“狗”的向量?0.1←“牛奶”的向量??0.30.40.9?0.80.70.2?0.50.60.3??∈R3×4
所以:
- 第 0 行:是 “貓” 的詞向量
- 第 1 行:是 “狗” 的詞向量
- 第 2 行:是 “牛奶” 的詞向量
當你輸入一個詞,比如 “狗”,它的編號是 1,模型就會去嵌入矩陣 E 中查找第 1 行,取出對應的向量 [0.2, 0.4, 0.7, 0.6],作為這個詞的表示。
這個過程叫做 查表(lookup),也叫 嵌入查找(embedding lookup)。
# 偽代碼
E = [[0.1, -0.3, 0.8, 0.5], # 貓[0.2, 0.4, 0.7, 0.6], # 狗[-0.1, 0.9, 0.2, 0.3]] # 牛奶word_id = 1 # “狗”
word_vector = E[word_id] # 取出第二行 → [0.2, 0.4, 0.7, 0.6]
實現步驟
在 PyTorch 中,我們可以使用 nn.Embedding 詞嵌入層來實現輸入詞的向量化。接下來,我們將會學習如何將詞轉換為詞向量,其步驟如下:
- 先將語料進行分詞,構建詞與索引的映射,我們可以把這個映射叫做詞表,詞表中每個詞都對應了一個唯一的索引;
- 然后使用 nn.Embedding 構建詞嵌入矩陣,詞索引對應的向量即為該詞對應的數值化后的向量表示。
【示例】文本數據為: “北京冬奧的進度條已經過半,不少外國運動員在完成自己的比賽后踏上歸途。”
- 首先,將文本進行分詞;
- 然后,根據詞構建詞表;
- 最后,使用嵌入層將文本轉換為向量表示。
步驟 1:首先使用 jieba 對文本進行分詞操作,將連續的文本切分為詞語列表。
import jiebatext = '北京冬奧的進度條已經過半,不少外國運動員在完成自己的比賽后踏上歸途。'
words = jieba.lcut(text) # 使用精確模式分詞
print("分詞結果:", words)
輸出示例:
分詞結果: ['北京', '冬奧', '的', '進度', '條', '已經', '過半', ',', '不少', '外國', '運動員', '在', '完成', '自己', '的', '比賽', '后', '踏上', '歸途', '。']
步驟 2: 將分詞后的詞語去重,并為每個詞分配唯一的索引(ID),構建詞表(vocabulary)。
# 去重并保留順序
unique_words = list(set(words))
word_to_index = {word: idx for idx, word in enumerate(unique_words)}
index_to_word = {idx: word for idx, word in enumerate(unique_words)}print("詞表大小:", len(unique_words))
print("詞到索引的映射示例:", {k: v for k, v in list(word_to_index.items())[:5]})
輸出示例:
詞表大小: 20
詞到索引的映射示例: {'北京': 0, '冬奧': 1, '的': 2, '進度': 3, '條': 4...}
步驟 3:使用 nn.Embedding 構建詞嵌入矩陣。
需要指定兩個關鍵參數:
num_embeddings: 詞表大小(即len(unique_words))embedding_dim: 每個詞的向量維度(例如 128)
import torch
import torch.nn as nn# 設置嵌入維度
embedding_dim = 128# 初始化嵌入層
embedding_layer = nn.Embedding(num_embeddings=len(unique_words), embedding_dim=embedding_dim)
步驟 4: 將文本轉換為索引序列
將分詞后的詞語轉換為對應的索引,并封裝為 PyTorch 張量作為輸入。
# 將分詞后的詞語轉換為索引序列
input_indices = [word_to_index[word] for word in words]
input_tensor = torch.tensor(input_indices)print("輸入索引序列:", input_indices)
print("輸入張量形狀:", input_tensor.shape)
輸出示例:
輸入索引序列: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 2, 14, 15, 16, 17, 18]
輸入張量形狀: torch.Size([20])
步驟 5: 獲取詞向量
將索引序列輸入嵌入層,得到對應的詞向量表示。
# 獲取詞向量
embedded_vectors = embedding_layer(input_tensor)print("詞向量形狀:", embedded_vectors.shape)
print("第一個詞的向量示例:", embedded_vectors[0].detach().numpy()[:5]) # 顯示前5個維度
輸出示例:
詞向量形狀: torch.Size([20, 128])
第一個詞的向量示例: [ 0.012 -0.034 0.045 -0.067 0.023]
完整代碼整合
import jieba
import torch
import torch.nn as nn# 1. 分詞
text = '北京冬奧的進度條已經過半,不少外國運動員在完成自己的比賽后踏上歸途。'
words = jieba.lcut(text)# 2. 構建詞表
unique_words = list(set(words))
word_to_index = {word: idx for idx, word in enumerate(unique_words)}
index_to_word = {idx: word for idx, word in enumerate(unique_words)}# 3. 初始化嵌入層
embedding_dim = 128
embedding_layer = nn.Embedding(num_embeddings=len(unique_words), embedding_dim=embedding_dim)# 4. 轉換為索引序列
input_indices = [word_to_index[word] for word in words]
input_tensor = torch.tensor(input_indices)# 5. 獲取詞向量
embedded_vectors = embedding_layer(input_tensor)# 6. 輸出結果
print("分詞結果:", words)
print("詞表大小:", len(unique_words))
print("詞向量形狀:", embedded_vectors.shape)
print("第一個詞的向量示例:", embedded_vectors[0].detach().numpy()[:5])
3.2 word2vec
Word2Vec 是一種高效學習詞向量(Word Embedding)的神經網絡模型,由 Google 的 Tomas Mikolov 團隊于 2013 年提出。它通過捕捉詞語的上下文關系,將詞語映射到低維連續向量空間中,使得語義相似的詞在向量空間中距離更近。Word2Vec 的提出標志著自然語言處理(NLP)從傳統基于規則和統計的方法轉向基于深度學習的分布式表示方法。
Word2Vec 的核心思想:
1. 分布式表示
- 傳統方法:將詞語表示為獨熱編碼(One-Hot),例如詞匯表大小為 V 時,每個詞的向量維度為 V × 1,且只有一個位置為 1,其余為 0。這種表示方式稀疏且無法捕捉語義關系。
- Word2Vec:通過神經網絡將詞語映射到低維稠密向量(例如 100 維、300 維),這些向量能夠捕捉語義和句法關系。例如:
- 語義相似性:
king - man + woman ≈ queen - 句法關系:
Paris - France + Italy ≈ Rome
- 語義相似性:
2. Word2Vec 的兩種模型架構
左邊CBOW,右邊skip-gram

CBOW 連續詞袋模型
目標:根據上下文詞預測中心詞。
-
輸入:多個上下文詞的 One-Hot 向量(平均后作為隱藏層輸入)。
-
輸出:中心詞的概率分布。
P(wt∣wt?1,wt?2,…,wt+n)P(w_t \mid w_{t-1}, w_{t-2}, \dots, w_{t+n}) P(wt?∣wt?1?,wt?2?,…,wt+n?)
模型結構:
- 輸入層:上下文詞的 One-Hot 向量(維度 C×V,其中 C 是窗口大小)。
- 投影層:
- 通過嵌入矩陣 W*(維度 V×N*),將每個上下文詞的 One-Hot 向量轉換為嵌入向量(維度 N×1)。
- 對所有上下文詞的嵌入向量求平均,得到隱藏層向量 h(維度 N×1)。
- 輸出層:
- 通過嵌入矩陣 W′(維度 N×V),將隱藏層向量 hh 轉換為輸出層的得分(維度 1×V)。
- 使用 Softmax 將得分轉換為概率分布


import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim# 設置張量數據類型為 32 位浮點數
dtype = torch.FloatTensor# 1. 準備語料庫
sentences = ["i like dog","i like cat","i like animal","dog cat animal","apple cat dog like","cat like fish","dog like meat","i like apple","i hate apple","i like movie book music apple","dog like bark","dog friend cat"
]# 2. 構建詞匯表及詞典
# 將所有句子合并為一個詞列表,并去重
word_list = list(set(" ".join(sentences).split()))
print("詞匯表:", word_list)# 構建詞 → ID 和 ID → 詞 的雙向映射
word2id = {word: i for i, word in enumerate(word_list)}
id2word = {i: word for i, word in enumerate(word_list)}
print("詞 → ID 映射:", word2id)# 3. 構建 CBOW 訓練數據
# 目標:根據上下文詞預測中心詞
cbow_data = []
for sentence in sentences:words = sentence.split()for i in range(1, len(words) - 1): # 跳過首尾詞,只處理中間詞context = [word2id[words[i - 1]], word2id[words[i + 1]]] # 上下文詞(前后各1個)target = word2id[words[i]] # 中心詞cbow_data.append([context, target])print("示例訓練數據 (上下文詞索引, 中心詞索引):")
print(cbow_data[:5]) # 打印前5個樣本# 4. 隨機批次生成函數
def random_batch(data, batch_size=3):"""從訓練數據中隨機抽取 batch_size 個樣本參數:data: 訓練數據,格式為 [[上下文詞索引], 中心詞索引]batch_size: 批次大小返回:input_batch: 上下文詞索引組成的張量 [batch_size, 2]label_batch: 中心詞索引組成的張量 [batch_size]"""random_inputs = []random_labels = []# 隨機選擇 batch_size 個樣本的索引random_index = np.random.choice(range(len(data)), batch_size, replace=False)for i in random_index:random_inputs.append(data[i][0]) # 上下文詞random_labels.append(data[i][1]) # 中心詞return torch.LongTensor(random_inputs), torch.LongTensor(random_labels)# 5. 模型參數
vocab_size = len(word_list) # 詞匯表大小
embedding_size = 2 # 詞向量維度(可調,此處設為2便于可視化)# 6. 定義 CBOW 模型
class CBOW(nn.Module):def __init__(self):super(CBOW, self).__init__()# 嵌入層:將詞索引轉換為低維稠密向量self.embed = nn.Embedding(vocab_size, embedding_size)# 輸出層:將上下文詞向量的平均值映射到詞匯表大小self.output = nn.Linear(embedding_size, vocab_size)def forward(self, input_batch):"""前向傳播邏輯參數:input_batch: [batch_size, 2],每個樣本包含兩個上下文詞的索引返回:output: [batch_size, vocab_size],每個詞的概率分布"""# 1. 嵌入層:將上下文詞索引轉換為嵌入向量 [batch_size, 2, embedding_size]x = self.embed(input_batch)# 2. 取上下文詞向量的平均值 [batch_size, embedding_size]x = torch.mean(x, dim=1)# 3. 輸出層:線性變換到詞匯表大小 [batch_size, vocab_size]x = self.output(x)return x# 7. 實例化模型、損失函數和優化器
model = CBOW()
criterion = nn.CrossEntropyLoss() # 分類損失
optimizer = optim.Adam(model.parameters(), lr=0.001) # 優化器# 8. 訓練循環
for epoch in range(5000):# 1. 生成隨機批次數據input_batch, label_batch = random_batch(cbow_data)# 2. 前向傳播output = model(input_batch) # [batch_size, vocab_size]# 3. 計算損失loss = criterion(output, label_batch)# 4. 反向傳播optimizer.zero_grad() # 清空梯度loss.backward() # 反向傳播計算梯度optimizer.step() # 更新參數# 5. 打印訓練進度if (epoch + 1) % 1000 == 0:print(f"Epoch: {epoch + 1}/5000, Loss: {loss.item():.4f}")# 9. 查看訓練后的詞向量
with torch.no_grad():weights = model.embed.weight.data.numpy() # 獲取嵌入層權重for i, word in enumerate(word_list):print(f"{word} 的詞向量: {weights[i]}")
Skip-gram
給定一個中心詞,預測其上下文詞(即周圍的詞)
- 輸入:一個中心詞的 One-Hot 向量。
- 輸出:上下文詞的概率分布(通過 Softmax 計算)
模型結構:
- 輸入層:中心詞的 One-Hot 向量(維度為V×1)。
- 投影層:
- 通過嵌入矩陣 WW(維度 V×N,其中 N 是嵌入維度),將 One-Hot 向量轉換為嵌入向量(維度 N×1)。
- 公式:h=WTx,其中x 是輸入的 One-Hot 向量。
- 輸出層:
- 通過另一個嵌入矩陣 W′(維度 N×V),將嵌入向量轉換為輸出層的得分(維度 1×V)。
- 公式:u=h?W′。
- 使用 Softmax 將得分轉換為概率分布

import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import math# 定義數據類型為浮點數
dtype = torch.FloatTensor# 語料庫,包含訓練模型的句子
sentences = ["i like dog", "i like cat", "i like animal","dog cat animal", "apple cat dog like", "cat like fish","dog like meat", "i like apple", "i hate apple","i like movie book music apple", "dog like bark", "dog friend cat"
]# 將所有句子拼接為一個字符串并按空格分詞
word_sequence = ' '.join(sentences).split()
# 獲取詞匯表中的所有唯一詞
word_list = list(set(word_sequence))
print("詞匯表(word_list):", word_list)# 創建詞典,詞匯表中的每個詞都分配一個唯一的索引
word2id = {w: i for i, w in enumerate(word_list)}
id2word = {i: w for w, i in word2id.items()} # 用于根據索引還原詞
print("詞典(word2id):", word2id)# 詞匯表大小
voc_size = len(word_list)
# 定義嵌入維度(嵌入向量的大小)為2
embedding_size = 2
# 每次訓練的批量大小
batch_size = 5# 創建 Skip-gram 模型的訓練數據
skip_grams = [] # 訓練數據:[中心詞ID, 上下文詞ID]
for i in range(len(word_sequence)):# 當前詞作為中心詞target = word2id[word_sequence[i]]# 獲取上下文詞(窗口大小為1)left_context = word2id[word_sequence[i - 1]] if i > 0 else Noneright_context = word2id[word_sequence[i + 1]] if i < len(word_sequence) - 1 else None# 將目標詞與上下文詞配對if left_context:skip_grams.append([target, left_context]) # [中心詞ID, 左側詞ID]if right_context:skip_grams.append([target, right_context]) # [中心詞ID, 右側詞ID]# 打印生成的 Skip-gram 數據示例
print("生成的 Skip-gram 數據示例(前5條):")
for i in range(5):center_word = id2word[skip_grams[i][0]]context_word = id2word[skip_grams[i][1]]print(f"[中心詞: {center_word}, 上下文詞: {context_word}]")# 定義隨機批量生成函數
def random_batch(data, size):"""從 skip_grams 數據中隨機選擇 size 個樣本,生成 one-hot 編碼的輸入和標簽"""random_inputs = [] # 輸入批次(one-hot 編碼)random_labels = [] # 標簽批次(上下文詞ID)# 從數據中隨機選擇 size 個索引random_index = np.random.choice(range(len(data)), size, replace=False)# 根據隨機索引生成輸入和標簽批次for i in random_index:# 目標詞 one-hot 編碼# np.eye(voc_size) 創建 voc_size x voc_size 的單位矩陣random_inputs.append(np.eye(voc_size)[data[i][0]])# 上下文詞的索引作為標簽random_labels.append(data[i][1])return random_inputs, random_labels# 定義 Word2Vec 模型
class Word2Vec(nn.Module):def __init__(self):super(Word2Vec, self).__init__()# 定義詞嵌入矩陣 W,大小為 (voc_size, embedding_size)self.W = nn.Parameter(torch.rand(voc_size, embedding_size)).type(dtype)# 定義上下文矩陣 WT,大小為 (embedding_size, voc_size)self.WT = nn.Parameter(torch.rand(embedding_size, voc_size)).type(dtype)# 前向傳播def forward(self, x):# 通過嵌入矩陣 W 得到詞向量weight_layer = torch.matmul(x, self.W) # [batch_size, embedding_size]# 通過上下文矩陣 WT 得到輸出output_layer = torch.matmul(weight_layer, self.WT) # [batch_size, voc_size]return output_layer# 創建模型實例
model = Word2Vec()# 定義損失函數為交叉熵損失
criterion = nn.CrossEntropyLoss()
# 使用 Adam 優化器
optimizer = optim.Adam(model.parameters(), lr=0.001)# 訓練模型
for epoch in range(10000):# 獲取隨機的輸入和目標inputs, labels = random_batch(skip_grams, batch_size)# 轉為張量input_batch = torch.Tensor(inputs)label_batch = torch.LongTensor(labels)optimizer.zero_grad() # 梯度清零output = model(input_batch) # 前向傳播# 計算損失函數loss = criterion(output, label_batch)# 每 1000 輪打印一次損失if (epoch + 1) % 1000 == 0:print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))loss.backward() # 反向傳播optimizer.step() # 參數更新# 訓練完成后,打印學習到的詞向量
print("\n學習到的詞向量(嵌入矩陣 W):")
for i in range(voc_size):print(f"{id2word[i]}: {model.W.data[i].numpy()}")# 計算詞向量之間的余弦相似度
def cosine_similarity(vec1, vec2):return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))print("\n詞向量的余弦相似度示例:")
print(f"i 和 like 的相似度: {cosine_similarity(model.W.data[word2id['i']].numpy(), model.W.data[word2id['like']].numpy())}")
print(f"like 和 dog 的相似度: {cosine_similarity(model.W.data[word2id['like']].numpy(), model.W.data[word2id['dog']].numpy())}")
print(f"dog 和 cat 的相似度: {cosine_similarity(model.W.data[word2id['dog']].numpy(), model.W.data[word2id['cat']].numpy())}")
Gensim 中 Word2Vec 使用
1. 安裝 Gensim
pip install gensim
2. 常用參數
| 參數名 | 默認值 | 說明 |
|---|---|---|
sentences | 無(必需) | 輸入語料,應為分詞后的句子列表,如 [["word1"], ["word2"]]。大語料建議使用 LineSentence 流式讀取。 |
vector_size | 100 | 詞向量的維度,常用 100、200、300。維度越高表達能力越強,但需要更多數據和計算資源。 |
window | 5 | 上下文窗口大小,即目標詞前后最多考慮的詞數。一般設置為 3~10。 |
min_count | 5 | 忽略出現次數少于該值的詞語。用于過濾低頻詞,小語料可設為 1 或 2。 |
sg | 0 | 訓練算法:0 表示使用 CBOW,1 表示使用 Skip-gram。Skip-gram 更適合小語料和低頻詞。 |
workers | 3 | 訓練時使用的 CPU 線程數,建議根據 CPU 核心數設置以提升訓練速度。 |
alpha | 0.025 | 初始學習率,訓練過程中會線性衰減。一般無需調整。 |
sample | 1e-3 | 高頻詞的下采樣閾值,用于減少常見詞(如“的”、“是”)的訓練樣本,提升效果和速度。 |
hs | 0 | 是否使用層次 Softmax:1 表示使用,0 表示不使用。通常與負采樣互斥。 |
negative | 5 | 負采樣數量,0 表示不使用負采樣。推薦值為 5~20,適合大規模語料。 |
seed | 1 | 隨機數種子,設置后可保證訓練結果可重現。 |
model.wv 的常用且重的方法
-
model.wv.most_similar(positive, negative, topn)
查找與給定詞語最相似的詞,支持類比推理。model.wv.most_similar('apple') # 找與 apple 相似的詞 model.wv.most_similar(positive=['king', 'woman'], negative=['man']) # king - man + woman ≈ queen -
model.wv.similarity(word1, word2)
計算兩個詞之間的語義相似度(余弦相似度),返回值在 -1 到 1 之間。model.wv.similarity('man', 'woman') # 返回如 0.78 -
model.wv.doesnt_match(list_of_words)
找出列表中語義上“最不合群”的詞。model.wv.doesnt_match(['cat', 'dog', 'mouse', 'table']) # 返回 'table' -
model.wv[word]或model.wv.get_vector(word)
獲取某個詞的詞向量(numpy 數組)。vec = model.wv['hello'] # 獲取 'hello' 的向量 -
model.wv.key_to_index
獲取詞到索引的映射字典,可用于查看詞在詞匯表中的位置。index = model.wv.key_to_index['python'] -
model.wv.index_to_key
獲取索引到詞的映射列表,與key_to_index對應。word = model.wv.index_to_key[100] # 獲取索引為 100 的詞 -
model.wv.save()和model.wv.load()
保存或加載訓練好的詞向量,便于后續使用或共享。model.wv.save("vectors.kv") from gensim.models import KeyedVectors wv = KeyedVectors.load("vectors.kv")
| 概念 | 定義 | 示例 |
|---|---|---|
| 詞向量(Word Vector) | 將一個詞語表示為一個低維稠密向量,捕捉其語義信息 | “貓” → [0.8, -0.3, 0.5] |
| 句向量(Sentence Vector) | 將一個完整句子表示為一個向量,反映整個句子的語義 | “我愛學習” → [0.6, 0.1, -0.4, ...] |
【示例】
sentence = "Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers."需要把這句話通過api的方法,轉成句向量
from gensim.models import Word2Vec
import numpy as np
import resentence = "Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers."# 1.文本處理
def preprocess(text):text = re.sub(r'[^a-zA-Z0-9\s]', '', text)text = text.lower()text = text.split()return textwords = preprocess(sentence)
print('分詞后:', words)# 2.訓練模型
model = Word2Vec(sentences=[words],vector_size=100,window=5,min_count=1, # 所有詞都保留workers=1
)
# 3.獲得句向量
def sentence2vec(sentence,model,vector_size=100):words = preprocess(sentence)word_vectors = []for word in words:if word in model.wv:# 確保詞在詞匯表中word_vectors.append(model.wv[word])if len(word_vectors) == 0:return np.zeros(vector_size)sentence_vector = np.mean(word_vectors, axis=0)return sentence_vectorvec = sentence2vec(sentence, model,vector_size=100)
print('句向量形狀:', vec.shape)
print('句向量:', vec)
)





系統架構:如何構建一個能查資料的大語言模型系統)




)




)


