
🐇明明跟你說過:個人主頁
🏅個人專欄:《深度探秘:AI界的007》?🏅
🔖行路有良友,便是天堂🔖
目錄
一、前言?
1、LLM 的局限:模型知識“封閉” vs 現實知識“動態”
2、什么是RAG
3、為什么需要“檢索 + 生成”結合?
二、RAG 的整體架構與流程
1、檢索增強生成的基本結構
2、核心流程
三、核心模塊解析
1、向量檢索模塊(Retriever)
1.1、文檔預處理與切分(Chunking)
1.2、向量化(Embedding)原理
1.3、向量數據庫簡介
2、生成模塊(Generator)
2.1、提示模板設計(Prompt Template)
2.2、插入檢索內容的方式
四、RAG 與傳統 QA 系統的對比
1、檢索式 QA(BM25 / Elasticsearch)
2、生成式 QA(LLM 單獨輸出)
3、RAG相比檢索式 QA和生成式 QA的優勢
一、前言
1、LLM 的局限:模型知識“封閉” vs 現實知識“動態”
🤖 大語言模型 LLM 的“大腦”怎么來的?
LLM(比如 ChatGPT)是通過“喂大量文字資料”訓練出來的。
這些資料可能包括:
-
維基百科 📚
-
新聞、小說 🗞?📖
-
技術文檔、網站內容 🧑?💻
-
訓練時截?于某?年(比如 2023 年)
? 優點:
-
訓練完之后,它能“理解語言”和“生成回答”,就像人一樣 ??
🚫 但問題來了!
訓練完之后,這些模型的知識就“封閉”了!
就像你在 2023 年讀完所有百科,然后被關進了房間…
以后就不能接觸外面的新東西了 🙈
📅 現實世界是“動態”的!
現實世界每天都在變:
-
新技術、新產品 💡
-
股市波動 📉📈
-
社會新聞 📰
-
法律、政策變化 🏛?
-
你公司的文檔不斷更新 📂
🤔 舉個例子
你問 ChatGPT:
“蘋果 iPhone 16 有哪些新功能?”
-
? 普通 LLM(沒聯網)只能告訴你:
“截至訓練時,最新的是 iPhone 14 或 15…” -
? 使用 RAG 或聯網增強的模型能回答:
“iPhone 16 加入了 AI 拍照助手、無邊框屏幕…”(實時查的!)
📌 所以說…
? LLM 的局限:
-
它的知識是靜態的、封閉的 🧱
-
無法主動感知“此時此刻”發生了什么 ?
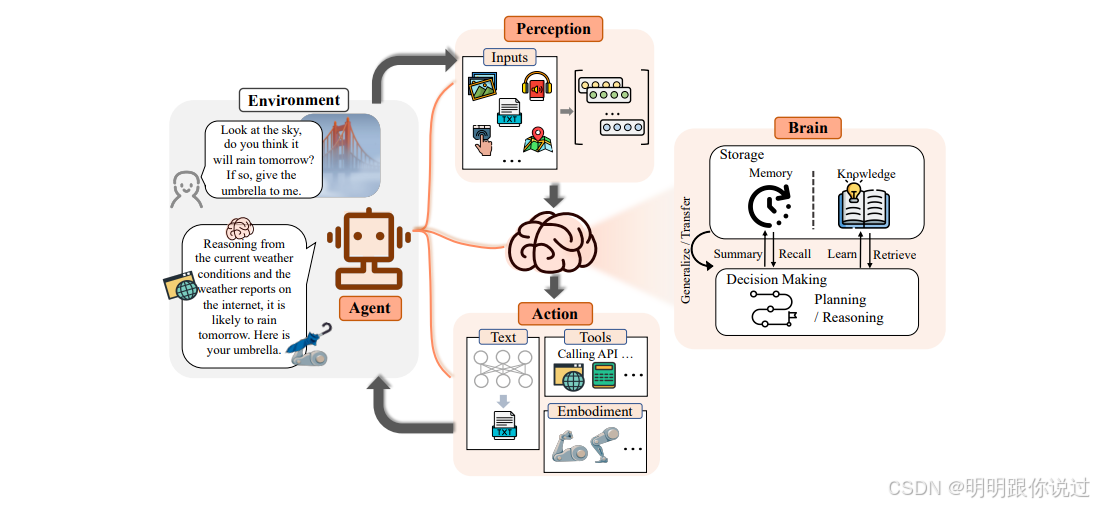
2、什么是RAG
你有沒有和 ChatGPT 聊天時發現,它有時候回答得不太準確?🤔
那是因為它只靠“記憶”回答問題,而不是實時“查資料”。
RAG 就是來解決這個問題的!🎯
💡RAG 的全稱
RAG = Retrieval-Augmented Generation
中文意思是:“檢索增強生成”
聽起來是不是很學術?別急,我們來舉個栗子🌰
🍜 用“點外賣”舉個例子
假設你在點外賣 🍱,你問:
哪家餐廳最近評價最好?
-
如果是普通大模型(沒有 RAG):
它會靠以前學過的資料告訴你:
“大眾點評上XX餐廳評價不錯哦~” -
如果是帶 RAG 的模型:
它會先去實時搜索:
“當前最新的餐廳評價”,
然后結合自己的理解,告訴你答案!
?是不是更靠譜了!

3、為什么需要“檢索 + 生成”結合?
簡單說一句話:
👉 “檢索”找資料,“生成”來表達
合在一起,就成了聰明又靠譜的問答助手 🧠?
🎓 一句話區分兩者
| 模塊 | 是誰 | 作用 |
|---|---|---|
| 🔍 檢索 | 類似 Google、百度 | 從知識庫里“找答案” |
| ?? 生成 | 類似 ChatGPT、文心一言 | 把資料“說人話”告訴你 |
📦 為什么不能只靠“生成”?
生成模型(LLM)很強大,但有兩個大問題:
-
知識是封閉的
它只能回答訓練時學過的內容,不能訪問新數據 📅 -
可能張口就來(幻覺)
它有時會“瞎編”一個聽起來像真的答案 🤯“Python 6.0 已發布”?(其實根本沒有)
🔍 那只用“檢索”行不行?
只用檢索就像自己去 Google 搜資料:
-
你得自己讀、自己理解 🧾
-
內容零碎,用戶體驗不好 😩
? 所以“檢索 + 生成”強在哪?
它把 兩者的優點結合起來:
| 模塊 | 優點 |
|---|---|
| 檢索 | 提供實時、可靠、準確的“資料來源” 📚 |
| 生成 | 自動理解內容,用自然語言表達答案 ? |
就像你有了個聰明秘書👇
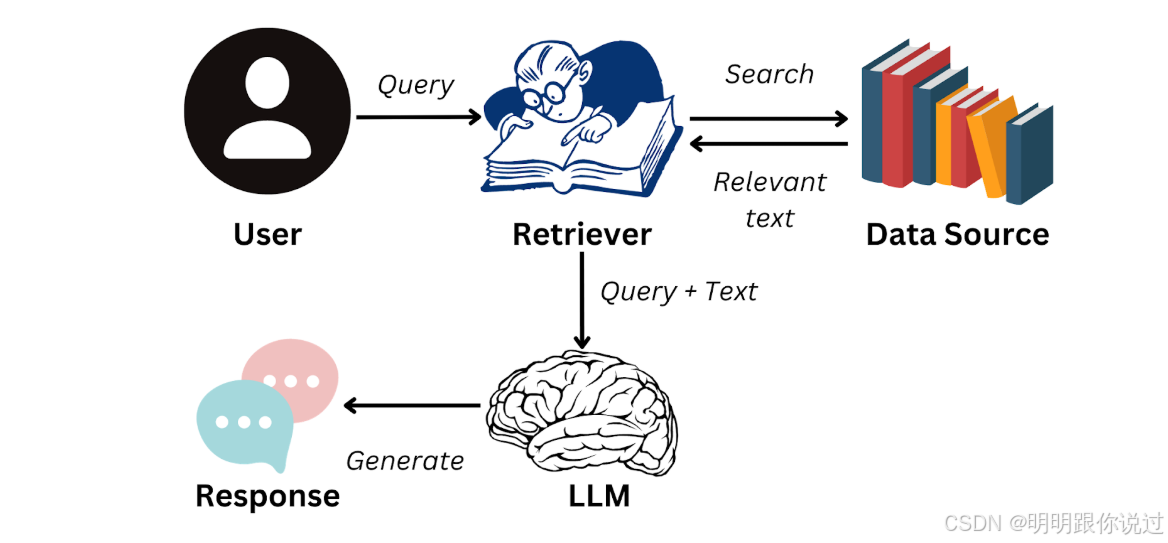
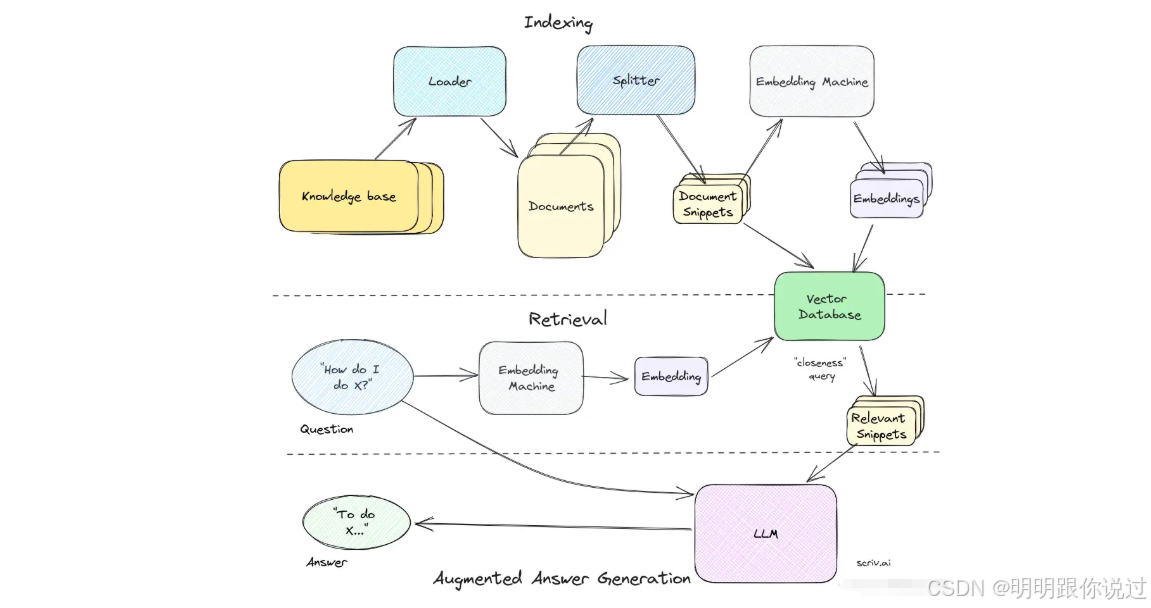
二、RAG 的整體架構與流程
1、檢索增強生成的基本結構
🧱 RAG 的基本結構組成
[用戶問題] ?
? ? ?↓ ?
🔍 檢索模塊(Retriever) ?
? ? ?↓ ?
📄 相關文檔(Document Store / 向量數據庫) ?
? ? ?↓ ?
🤖 生成模塊(LLM) ?
? ? ?↓ ?
? 最終回答
1?? 用戶問題(User Query)🗣?
用戶提出一個自然語言的問題,比如:
“我們公司今年的假期安排是怎樣的?”
2?? 檢索模塊(Retriever)🔍
它會把這個問題變成“向量”或關鍵詞,
去知識庫里找“相關資料”,比如 Word 文檔、PDF、數據庫記錄等。
常用方式有:
-
向量搜索(embedding 檢索)🔢
-
關鍵詞搜索(BM25等)🔡
3?? 文檔庫 / 知識源(Document Store)📚
這是你提供給系統的“專屬資料庫”:
可以是:
-
內部文檔系統(如 Confluence)
-
產品手冊、公司制度文檔
-
FAQ 問答庫
-
向量數據庫(如 Faiss、Weaviate、Pinecone)
4?? 生成模塊(LLM)??
將檢索到的資料 + 用戶問題
一起輸入給大語言模型(如 GPT-4)
👉 它會生成一個貼合問題、參考資料的自然語言答案。
5?? 最終輸出 ?
模型輸出的回答結合了“當前資料”與語言表達能力,
能給出“有依據、不瞎編”的智能答復。
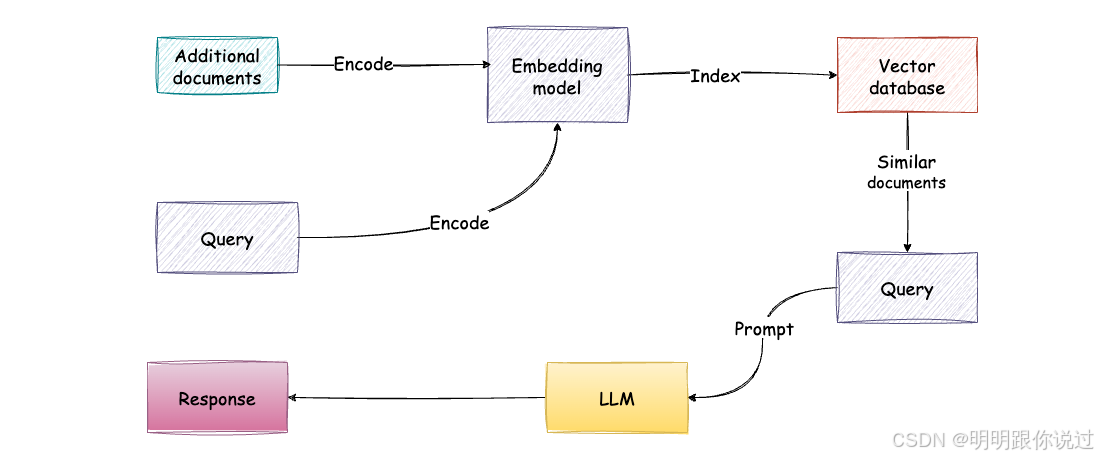
2、核心流程
🧭 1. 用戶輸入 query(提問)💬
用戶輸入自然語言問題,比如:
“公司 VPN 連不上怎么處理?”
🔍 2. 檢索相關文檔(Retriever)📂
將用戶問題轉化為向量(或關鍵詞),
在知識庫中查找相關資料片段,如:
-
公司 IT 支持文檔
-
網絡故障手冊
-
FAQ 問答庫
🔸 輸出:若干條相關內容(上下文)
🧠 3. 拼接上下文 + 問題輸入 LLM(Generator)🧾
把這些檢索到的內容 + 用戶問題
打包送入大語言模型(如 GPT-4)
🔸 模型可以“理解”上下文,結合已有知識進行回答。
? 4. 返回回答結果 ?
LLM 輸出一個貼合上下文、語義流暢的回答,例如:
“您好,請嘗試重啟 VPN 客戶端,若仍無法連接,請聯系 IT 支持人員并提供錯誤碼。”
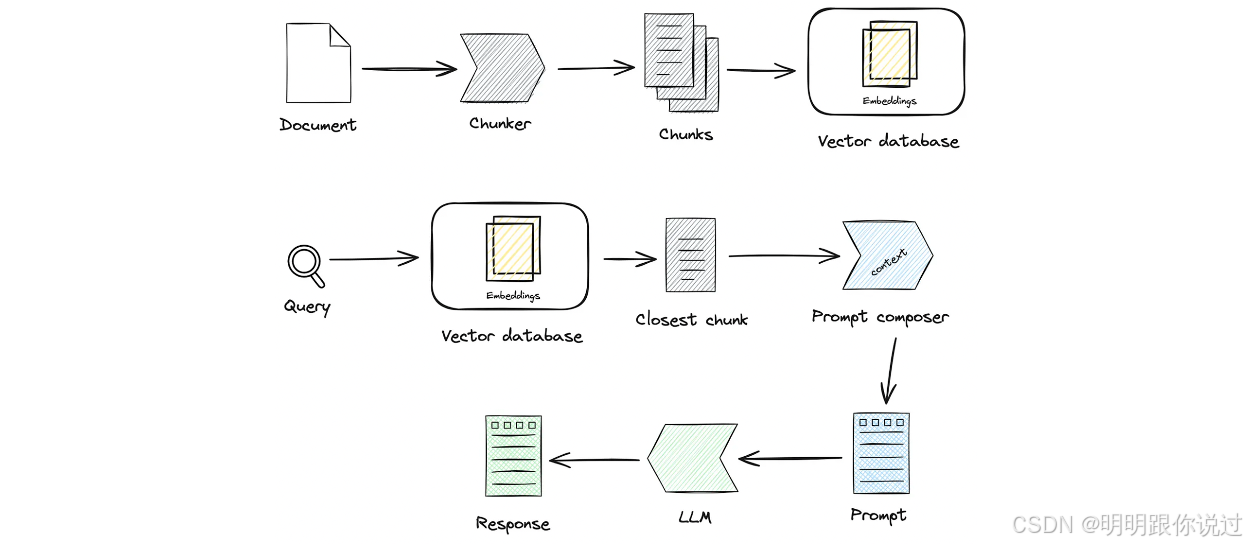
三、核心模塊解析
1、向量檢索模塊(Retriever)
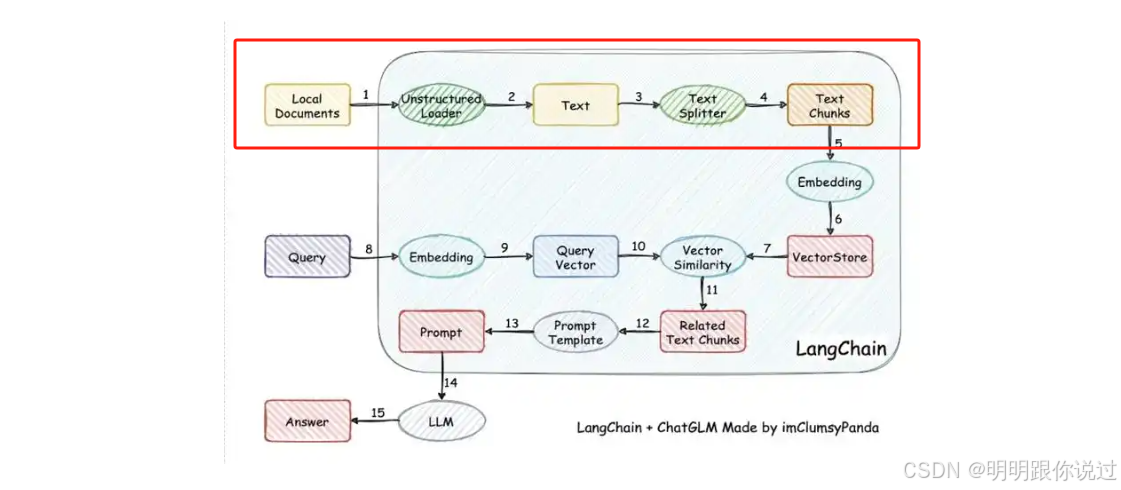
1.1、文檔預處理與切分(Chunking)
🧐 為什么要切分文檔?
我們不能直接把整本 PDF、整篇網頁丟給模型或向量數據庫!
因為:
-
太大,無法一次處理(LLM 有長度限制)📏
-
不利于精確匹配關鍵詞或語義 🎯
所以要把大文檔 ?? 切成小塊(Chunk)!
🔨 文檔預處理與切分流程
原始文檔(PDF / Word / 網頁等)📄 ?
? ? ? ? ↓ ?
1. 文本提取(OCR / Parser)🔍 ?
? ? ? ? ↓ ?
2. 清洗格式(去除 HTML 標簽、多余空格等)🧼 ?
? ? ? ? ↓ ?
3. 切分成小段(Chunking)?? ?
? ? ? ? ↓ ?
4. 生成每段的向量 Embedding(文本 → 數字)🔢 ?
? ? ? ? ↓ ?
存入向量數據庫(如 Faiss / Weaviate / Milvus)📦
1.2、向量化(Embedding)原理
🎯 一句話理解:
把一句話或一段文字 ??
轉換成一個可以在“數字世界”中比大小、量距離的 向量 📍
👉 方便讓機器“理解語義”和“做相似度檢索”!
🧠 舉個例子:
| 原始文本 | 向量化后 |
|---|---|
| “貓是一種動物” | [0.12, -0.85, 0.33, ..., 0.05] |
| “狗是哺乳動物” | [0.11, -0.80, 0.30, ..., 0.07] |
| “咖啡是一種飲料” | [0.95, 0.02, -0.30, ..., 0.88] |
📌 可以看到:“貓”和“狗”的向量相近,說明語義上相關。
“咖啡”離它們就遠了,語義無關 🧭
🧩 Embedding 是怎么做的?
過程如下圖(概念流程):
輸入文本:"如何重置公司郵箱密碼?" ?
? ? ?↓ ?
🔤 分詞(Tokenizer) ?
? ? ?↓ ?
🔢 編碼(Embedding 模型) ?
? ? ?↓ ?
輸出一個 N 維向量:[0.23, -0.45, 0.88, ..., -0.19]
? 每一維都代表了某種“語義特征”,比如技術性、辦公場景、問題類型等。
?🚀 常見的文本向量模型(Embedding Models)
| 模型 | 來源 | 特點 |
|---|---|---|
OpenAI text-embedding-3-small | GPT家族 | 準確度高、商用常用 |
bge-small / bge-large | BAAI(北京智源) | 中文支持優秀 🇨🇳 |
E5 / Instructor | Hugging Face 社區 | 多語言、檢索效果好 |
MiniLM / MPNet | 微軟 | 輕量快、適合端側部署 |
🧭 向量的價值在哪?
-
? 可以通過“距離”判斷文本間的語義相似度
-
常見方式:余弦相似度 cosine similarity
-
例如:
“公司如何申請年假?” 與 “怎樣請假?”
向量距離近,說明意思接近,Retriever 會成功召回!
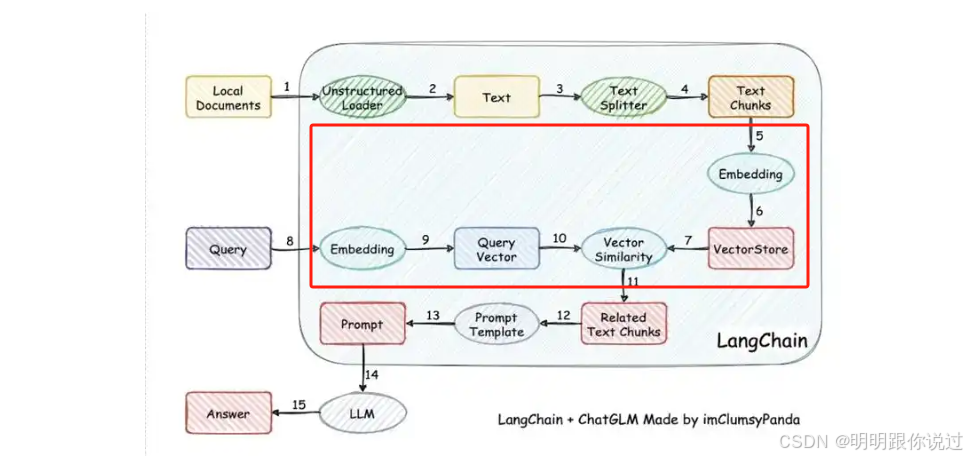
1.3、向量數據庫簡介
🧭 什么是向量數據庫?
向量數據庫是專門用來存儲、管理、搜索「向量(Embedding)」的數據庫 📦,
它能干的事情主要是👇:
-
? 存:將文本、圖像等向量數據存起來
-
? 查:支持「相似度檢索」——找出“語義最相近”的內容
-
? 快:可處理數百萬、甚至數十億條向量數據
-
? 強:支持高維向量、支持 GPU、分布式擴展能力強
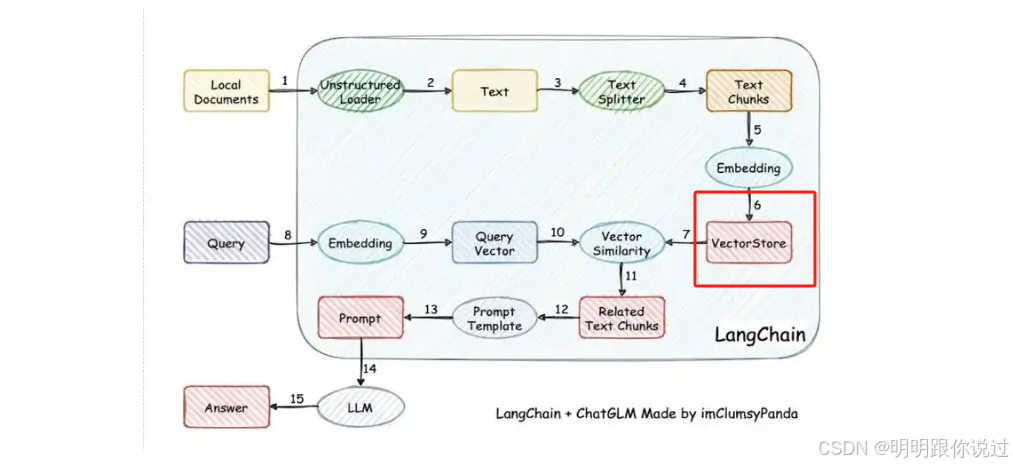
🔍 所以,在 RAG 架構中,它就是連接 檢索模塊 和 知識庫 的超級引擎!
?📦 常見向量數據庫介紹一覽:
| 名稱 | 產地 / 背景 | 優勢亮點 | 使用方式 | 是否開源 |
|---|---|---|---|---|
| FAISS 🧱 | Meta / Facebook | 極快的本地向量搜索 | Python 為主,嵌入式用多 | ? 是 |
| Milvus 🚀 | Zilliz(國產) | 云原生、分布式強 | REST / Python / Java | ? 是 |
| Weaviate 🧠 | 歐洲公司 | 集成好(支持 OpenAI / Cohere 等) | RESTful API,易部署 | ? 是 |
| Qdrant ? | 開發者友好 | 支持過濾器、打分高效 | Web UI + API 易用 | ? 是 |
🔹 FAISS(Facebook AI Similarity Search)
-
🌱 輕量級、單機版神器
-
🚀 支持 GPU,百萬級向量檢索毫秒級
-
😅 不適合做分布式、管理功能弱
-
🔧 適合離線處理、大量批量匹配任務
🔹 Milvus
-
🇨🇳 開源之光,Zilliz 維護
-
?? 支持云部署、分布式、多副本
-
🔌 可接 Elastic、S3、MySQL 等
-
💬 非常適合企業級大規模向量服務
🔹 Weaviate
-
🔗 天生就是為 RAG 服務的向量庫
-
🎁 內置向量模型集成(OpenAI / HuggingFace)
-
🌐 提供 GraphQL/REST API,簡單易上手
-
💡 適合快速搭建語義搜索原型
🔹 Qdrant
-
💻 支持結構化 + 非結構化過濾查詢(很靈活)
-
🧪 擁有 Web 控制臺、API 易用
-
💨 檢索性能強,開源活躍
-
👍 很適合開發者 / 中小型 RAG 項目

2、生成模塊(Generator)
2.1、提示模板設計(Prompt Template)
?為什么要設計提示模板?
因為直接把檢索結果 + 用戶問題喂給 LLM,模型未必能「懂你想要什么」。
所以我們需要一個“引導話術”,像“說明書”一樣告訴模型如何回答。📋
? 最常見的提示結構如下:
你是一位 [角色設定]。
請根據以下已知信息回答用戶的問題:
【已知信息】
{{context}}【用戶問題】
{{question}}請用簡潔、準確的語言回答:
📌 {{context}} 是 Retriever 檢索出來的內容
📌 {{question}} 是用戶輸入的問題
💡 示例:技術支持場景
你是一名經驗豐富的 IT 支持工程師。
請根據以下信息回答用戶的問題:【已知信息】
1. VPN 客戶端連接錯誤代碼為 809。
2. 錯誤 809 常見于防火墻未開放 UDP 500 和 UDP 4500 端口。
3. 建議聯系網絡管理員確認 VPN 協議設置。【用戶問題】
VPN 連接一直失敗,提示錯誤 809,怎么解決?請用中文簡潔說明處理方案。
🔍 這個模板能讓 LLM:
-
更清楚角色定位(你是誰)
-
更聚焦已知信息(別胡編)
-
更精確響應問題(不要答非所問)
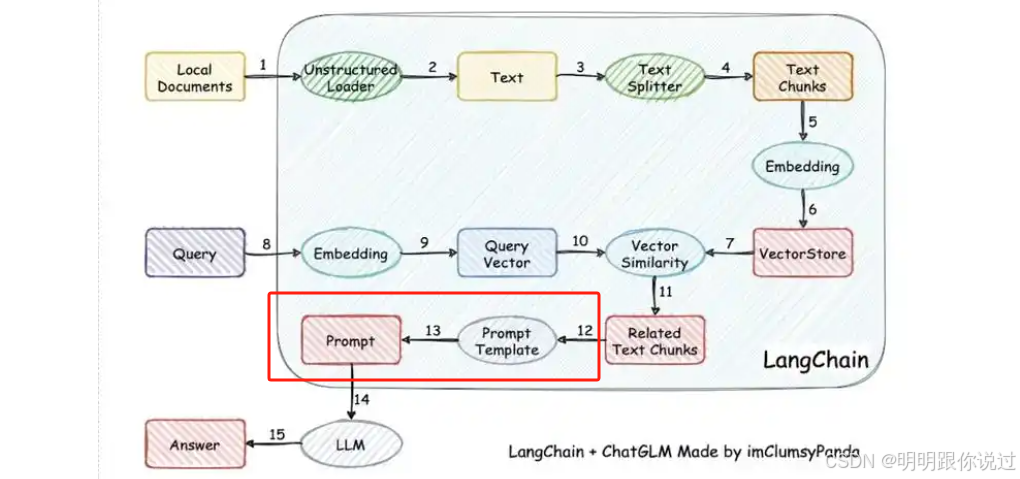
2.2、插入檢索內容的方式
🛠? 插入檢索內容的幾種方式
1?? 經典方式:直接拼接 Prompt(RAG-原始版)
👉 把檢索結果(Top-K 文檔)直接用 Prompt 拼到用戶問題前面:
[文檔1內容]
[文檔2內容]
...
問題:請總結上述內容的要點。
優點:簡單直接
缺點:信息可能冗余,文檔質量參差不齊導致生成結果不穩定 😵
2?? RAG Fusion 🧪
👉 靈感來自“多樣性增強”。做法是:
-
對一個問題,向 多個不同視角的查詢(Query variations) 檢索文檔(比如改寫問題)
-
把多個檢索結果合并、去重、排序
-
拼接后交給生成模塊
🌟 優點:
-
檢索結果更全面、不容易漏信息
-
減少模型對單一文檔的偏見
📌 舉例:
問題:“公司的假期制度是怎樣的?”
你可能會生成多個查詢:
-
“公司節假日規定”
-
“年假政策”
-
“加班與調休”
然后將多個檢索結果融合為一個 Prompt。
3?? RAG with Rerank 🔁
👉 在 Top-K 檢索結果出來后,使用一個 重排序(Reranker)模型,對這些文檔按“相關性”重新排序 ?
流程如下:
-
原始Retriever → 拿到Top-20候選文檔
-
使用Reranker模型(如 BGE-Reranker、ColBERT)評分
-
選出 Top-N 最相關文檔拼 Prompt
🌟 優點:
-
提升質量,去掉干擾文檔
-
對復雜問答場景更有效,比如醫療、法律
4?? (加分項)Chunk Merging、信息整合式 Prompt 🧩
針對文檔太長、碎片多的問題,有些系統會先:
-
對多個文檔內容做摘要或融合(比如提取共同主題)
-
然后再生成回答,減少重復和沖突
| 方式 | 特點 | 適用場景 |
|---|---|---|
| 📜 原始拼接 | 簡單、快速 | 小型項目、簡單問答 |
| 🧪 RAG Fusion | 多視角、全面 | 信息分散型問題 |
| 🔁 Rerank | 精準提取、抗噪性強 | 復雜、高質量要求的問答 |
| 🧩 Chunk融合 | 減冗余 | 文檔重復率高、大模型Token受限時 |

四、RAG 與傳統 QA 系統的對比
1、檢索式 QA(BM25 / Elasticsearch)
🧠 傳統 QA 系統是怎么工作的?
傳統 QA 系統的核心是:直接檢索文檔段落,作為回答返回。
🧱 架構核心:
-
用戶提問:“公司的加班政策是什么?”
-
系統使用 關鍵詞匹配算法(如 BM25)在文檔庫中查找最相關的段落。
-
把 相關段落原文返回給用戶。
🔍 BM25 / Elasticsearch 是主力選手:
-
BM25 是一種基于詞頻 + 逆文檔頻率的打分機制(TF-IDF 的升級版)
-
Elasticsearch 是支持 BM25 的流行全文搜索引擎
📦 舉個例子:
🧑?💼 你問:“我們公司節假日有哪些?”
🧾 傳統 QA(BM25)返回結果:
第5章 節假日安排:
1. 元旦放假1天;
2. 春節放假7天;
3. 清明節放假1天;
...
? 優點:直接、可查證
? 缺點:用戶得自己讀、自己理解

2、生成式 QA(LLM 單獨輸出)
? 生成式 QA 是什么?
生成式問答(Generative QA)就是指:
只用大語言模型(LLM) 來回答問題,不借助外部知識庫或檢索系統。
也就是說,模型完全靠 自己“腦子里”的知識 來作答📦。
🧱 它的工作方式非常簡單:
-
用戶提問:“黑洞為什么是黑的?”
-
模型在它的訓練知識中找答案(比如 GPT-4 訓練時學到的物理知識)
-
生成一段自然語言的回答
📦 舉個例子
🧑?💬 用戶問:
“牛頓三大定律分別是什么?”
🤖 生成式 QA(單獨 LLM)回答:
“牛頓三大定律包括慣性定律、加速度定律和作用反作用定律,分別為:1. 物體不受外力將保持靜止或勻速直線運動;2. F=ma;3. 作用力與反作用力大小相等方向相反。”
? 回答清晰、自然,不需要引用外部資料。
🧠 它的“知識庫”來自哪里?
就是它訓練時候用的大量數據,比如:
-
書籍、百科、論文
-
互聯網上的網頁、論壇
-
GitHub、博客、維基百科...
一旦模型訓練完成,它就像一位博覽群書的“閉卷考生”,可以根據腦中的“印象”來作答📚🧠

3、RAG相比檢索式 QA和生成式 QA的優勢
三種 QA 模型的區別:
| 模型類型 | 數據來源 | 回答方式 | 是否有“理解力” | 是否會幻覺 |
|---|---|---|---|---|
| 🔍 檢索式 QA | 外部文檔庫(如 ES / BM25) | 直接返回原文片段 | ? 沒有,靠關鍵詞匹配 | ? 基本不會 |
| 🧾 生成式 QA | 模型訓練時的知識 | 自由生成 | ? 有語義能力 | ?? 高,容易胡編 |
| 🤖 RAG | 檢索結果 + LLM | 先檢索再生成 | ? 有理解能力 | ? 較低,可控 |
? 那么,RAG 到底比它們強在哪兒?一起來看!👇
🎯 對比優勢一:結合了“知識準確性”和“語言表達能力”
| 能力 | 檢索式 QA | 生成式 QA | ? RAG |
|---|---|---|---|
| 🎯 找到正確知識 | ? | ? | ? |
| 🗣? 表達自然語言 | ? | ? | ? |
RAG = 檢索準確性(靠 Retriever) + 表達通順性(靠 Generator)
→ 既懂又會說 💡🧠🗣?
🔍 對比優勢二:支持開放域問答
傳統檢索式 QA 往往只適用于特定知識文檔,
生成式 QA 又容易“張口就來”。
🎯 RAG 則可以面向任意問題,只要資料在知識庫中,就能通過檢索 + 推理生成高質量回答。
🧠 對比優勢三:降低幻覺風險
幻覺 = 模型一本正經地編!
-
? 生成式 QA:幻覺高(完全靠記憶)
-
? RAG:只在模型讀了真實資料后生成,幻覺概率大大降低
-
? 檢索式 QA:無幻覺,但用戶要自己讀
📚 對比優勢四:回答內容有“證據”可查
RAG 可將使用過的文檔片段一起返回,形成“可追溯”的問答系統。
💡 示例:
問題:公司的帶薪年假制度是什么?
🤖 RAG 回答:
-
🗣? 回答:你每年有5天帶薪年假,未使用的部分可延期1年。
-
📎 來源文檔片段:
“員工年假為每年5個工作日,未休部分可結轉至次年使用。”
? 回答可信 + 有出處
(相比之下,生成式 QA 沒法告訴你“這句話是哪來的”)
🔄 對比優勢五:知識可隨時更新,無需重訓
| 模型 | 知識更新方式 | 難度 |
|---|---|---|
| 生成式 QA | 重訓練 LLM | 😖 非常難 |
| 檢索式 QA | 更新文檔庫 | 😀 簡單 |
| ? RAG | 更新知識庫 + 檢索器 | ? 非常靈活! |
💡 RAG 只要更新知識庫和 Embedding 就能快速響應新內容,例如法規變化、產品更新、新聞實時問答等。
🧩 總結一句話:
RAG = 檢索的嚴謹 + 生成的聰明 🧠 + 知識的可控 📚
是目前大多數企業級智能問答系統的首選!
🎁 用表格總結一下三者對比:
| 維度 | 檢索式 QA | 生成式 QA | ? RAG |
|---|---|---|---|
| 數據來源 | 文檔庫 | 模型記憶 | 文檔庫 |
| 回答風格 | 原文復制 | 自由生成 | 生成回答 |
| 表達能力 | ? 弱 | ? 強 | ? 強 |
| 知識更新 | ? 易更新 | ? 難(需重訓) | ? 易更新 |
| 是否可溯源 | ? 可 | ? 否 | ? 可 |
| 幻覺概率 | ? 無 | ? 高 | ?? 低 |
| 技術難度 | ?? | ?? | ???? |
💕💕💕每一次的分享都是一次成長的旅程,感謝您的陪伴和關注。希望這些文章能陪伴您走過技術的一段旅程,共同見證成長和進步!😺😺😺
🧨🧨🧨讓我們一起在技術的海洋中探索前行,共同書寫美好的未來!!!???




)




)





)
)
)

