目錄
一、LLaVA-3D
1、概述
2、方法
3、訓練過程
4、實驗
二、Video-3D LLM
1、概述
2、方法
3、訓練過程
4、實驗
三、SPAR
1、概述
2、方法
4、實驗
四、VG-LLM
1、概述?
2、方法
3、方法? ? ?
4、實驗
一、LLaVA-3D
1、概述
? ? ? ? 空間關系不足:傳統LMMs(如LLaVA)專注于2D圖像/視頻理解,缺乏對??3D空間關系??(深度、距離、物體相對位置)的感知能力。
? ? ? ? 數據與模型斷層:3D點云數據稀缺且質量低,難以大規模訓練。點云編碼器性能弱于成熟的2D CLIP模型,導致特征表達能力不足。
? ? ? ? 傳統3D LMMs需要對3D實例分割提取物體特征,流程冗長。點云特征與2D視覺特征表示空間不兼容。
? ? ? ? 所以LLaVA-3D不需要點云信息,直接利用多視圖信息,并繼承2D LMM的語義先驗(多視圖輸入LLaVA-Video)
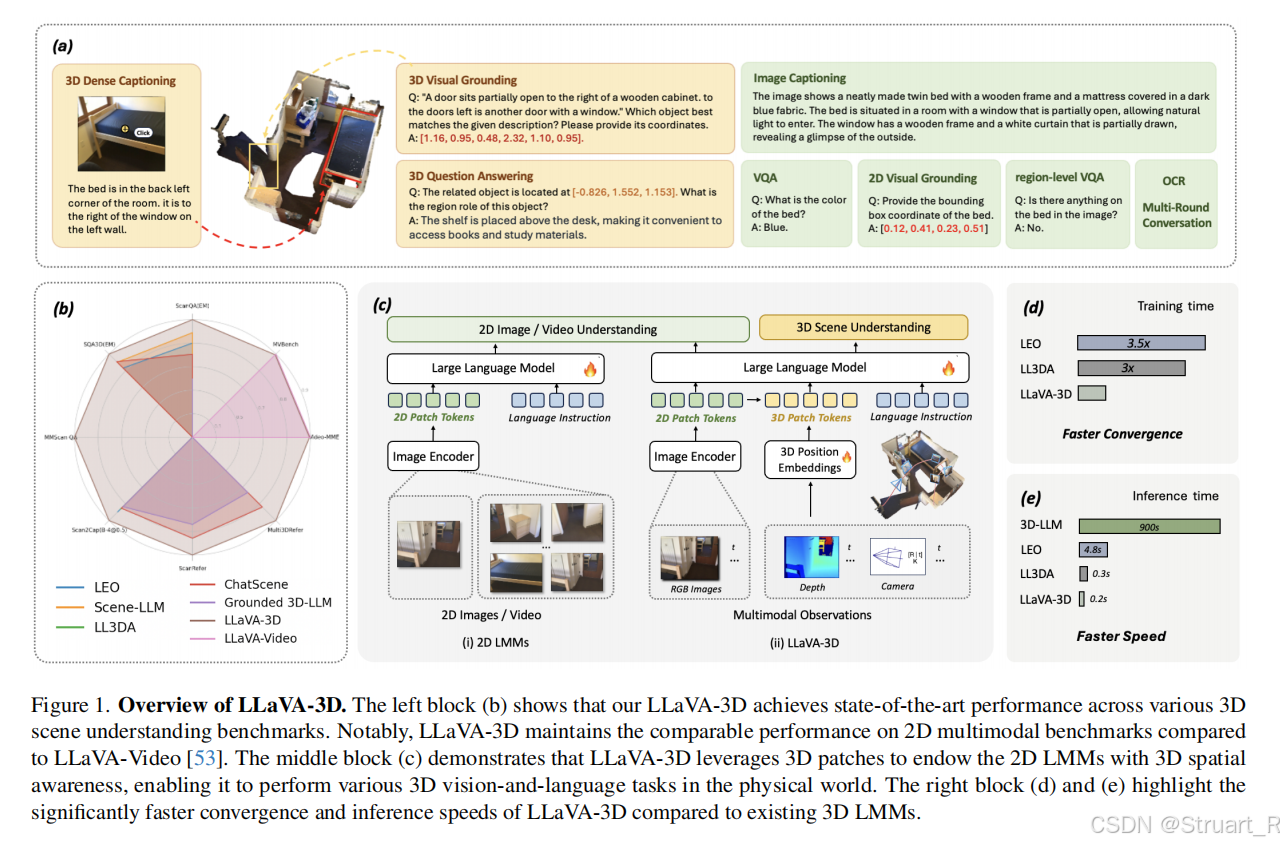
2、方法
架構
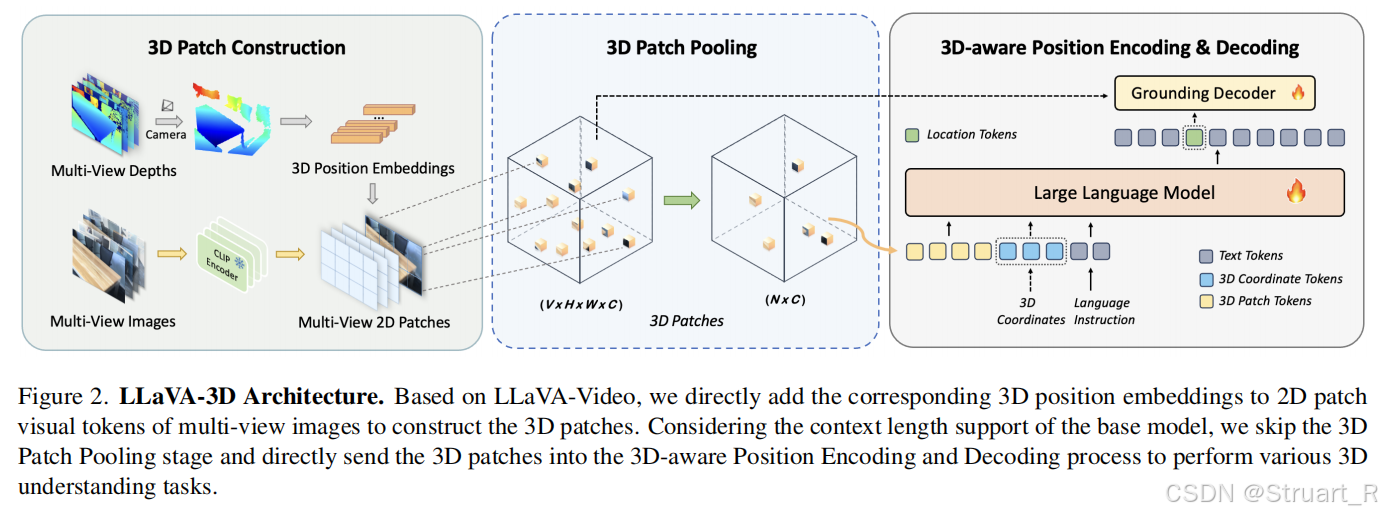
? ? ? ? 首先使用預訓練的LLaVA-Video-7B作為基礎模型,將多視圖圖像作為視頻幀序列輸入保留多視圖圖像處理能力,延續CLIP-ViT的視覺編碼器,來提取2D patch的特征(2D patch tokens)。
? ? ? ? 另外利用深度圖信息,相機內外參,通過深度反投影到像素3D世界坐標中,并對每一個patch都計算平均3D坐標,并通過兩層MLP將坐標編碼為特征向量(3D patch tokens)
? ? ? ? 如果用戶的問題中存在坐標信息時(比如:[1.2,0.8,0.9]位置的物體有什么作用),那么在LLM中不僅要輸入2D和3D特征信息,同時要輸入一個特定token,相當于把坐標信息從文字中提前解析出來,丟到LLM中。LLM完全依賴LLaVA-Video架構。
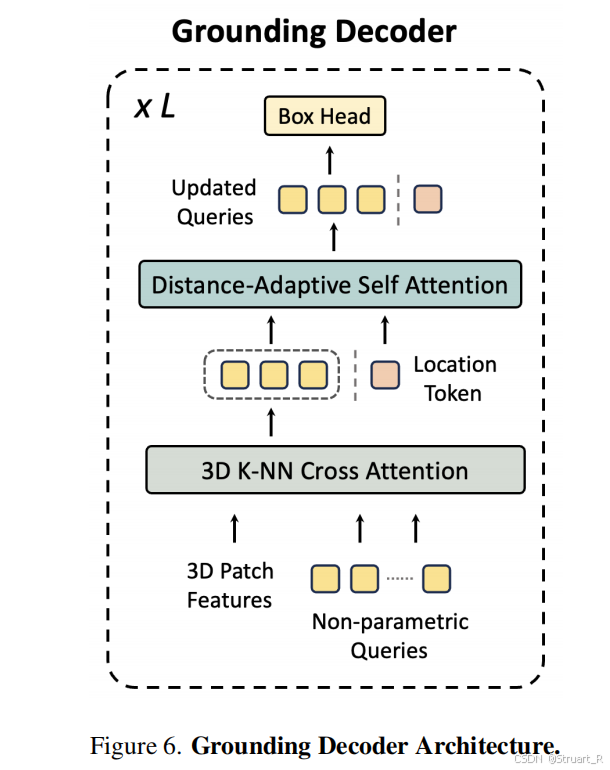
? ? ? ? 3D邊界框生成(解碼):并不是采用直接通過LLM輸出坐標信息,而是對tokens進行了解碼,利用Grounding Decoder,回歸物體中心坐標(x,y,z) + 尺寸(w,h,d) + 旋轉角(ψ,θ,φ)。具體來說,首先輸入3D patch features(應該是2D+3D的features信息,輸入到LLM的那部分,并進行了采樣),之后通過3D knn cross attn.之后再輸入LLM輸出中的location tokens,進行自注意力機制,最后回歸box 參數。
3D patch pooling? ? ?
? ? ? ? 針對于多視圖或者視頻序列過長時,可能會超過大語言模型能夠接受的范圍,所以要對輸入的patch進行壓縮。LLaVA-3D提出兩個方法,體素池化和最遠點采樣。
? ? ? ? 體素池化:可以理解為,將圖像降采樣,對于同一個體素內的patch特征取平均,并只保留該平均特征。
? ? ? ? 最遠點采樣:從大規模點集中選取有代表性的子集,比如第一輪先初始一個點到采樣點集合S中,之后計算所有點到S的最小距離,選擇距離最遠的點加入S,反復迭代,直到滿足所需的采樣點數量。
3、訓練過程
數據
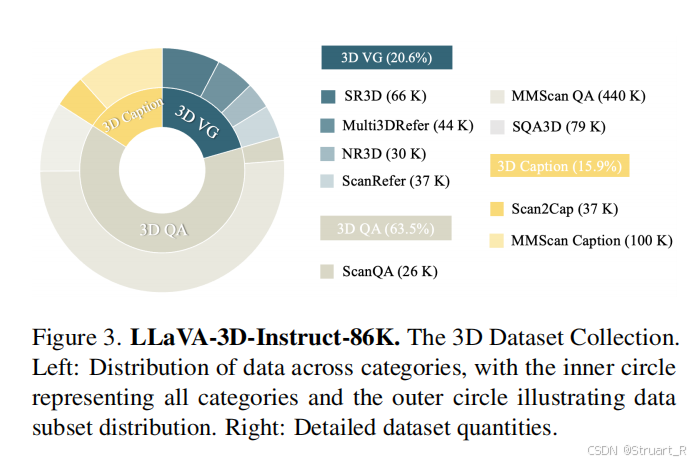
訓練過程
? ? ? ? 先對LLaVA-3D的2D和3D模塊同時訓練2D部分輸入LLaVA-Video的數據,3D部分輸入上圖的LLaVA-3D-Instruct-86K。
? ? ? ? 凍結其他模塊,單獨微調Grounding decoder。
4、實驗
? ? ? ? LLaVA-3D可以實現多模態3D問答(坐標空間推理,場景關系推理),3D密集描述生成,3D視覺定位,并同時兼具視頻視覺理解能力。

? ? ? ? 對于3DQA問題,關注基礎3D空間理解ScanQA,SQA3D,MMScanQA是幾何-語言對齊的,比如某一坐標下物體的材質是怎樣的。OpenEQA是具身智能真實場景的推理。
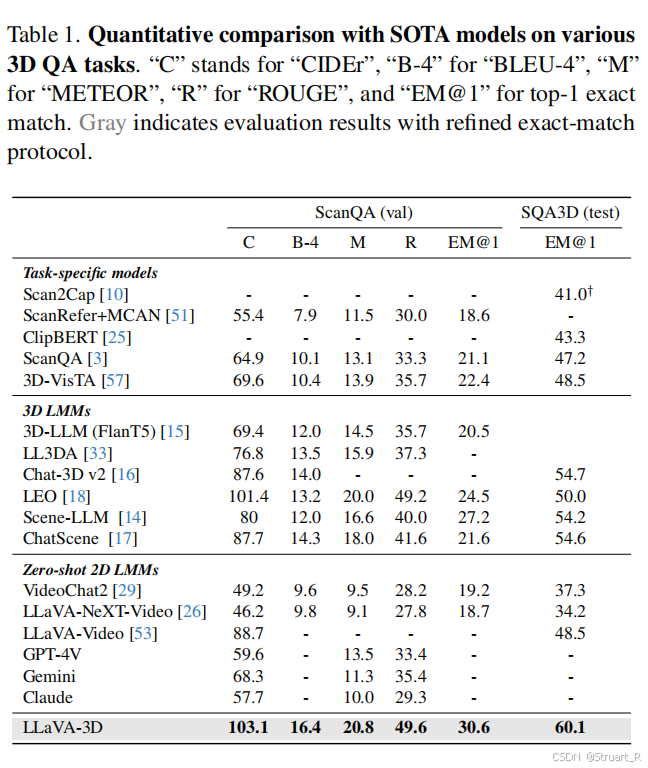
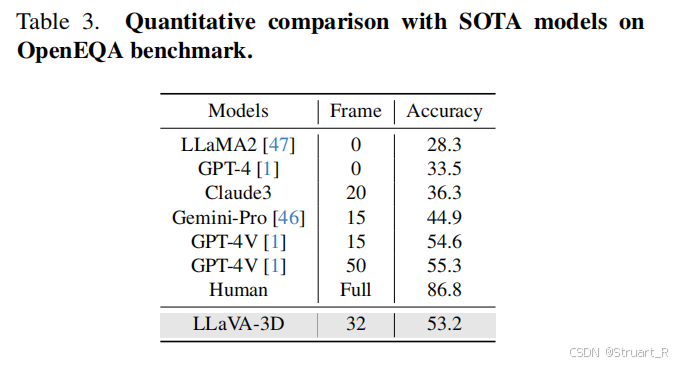
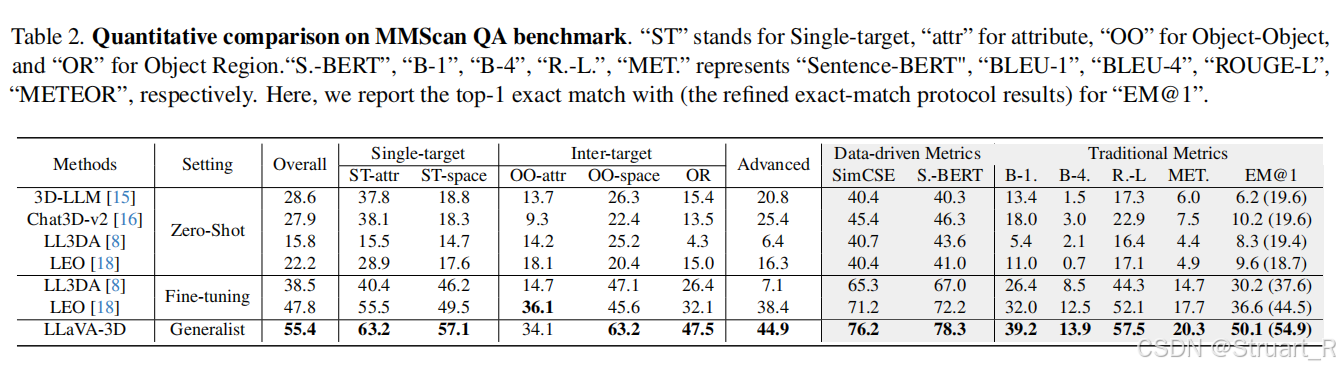
? ? ? ? 3D視覺定位中對比了3D-LLM,Grounded 3D-LLM。
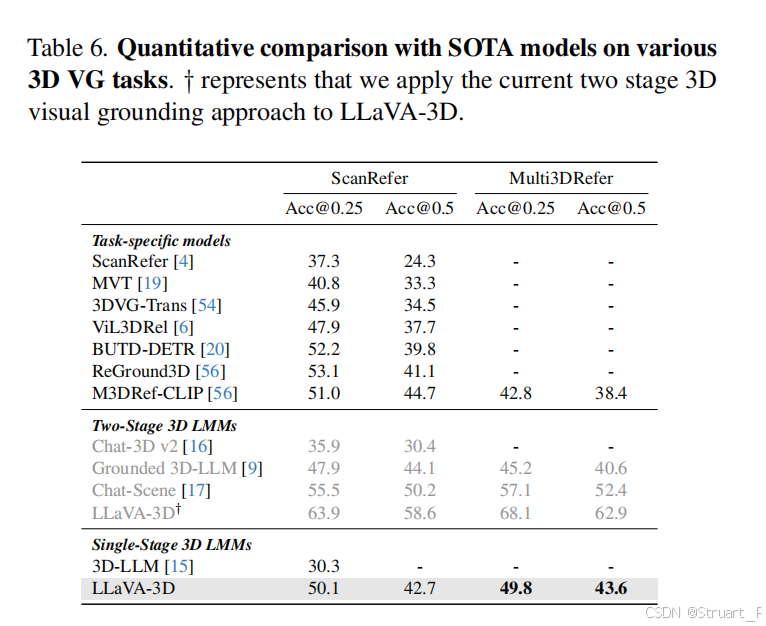
? ? ? ? 3D密集描述上,采用Scan2Cap和MMScan的描述,后者應該是帶有定位的QA。
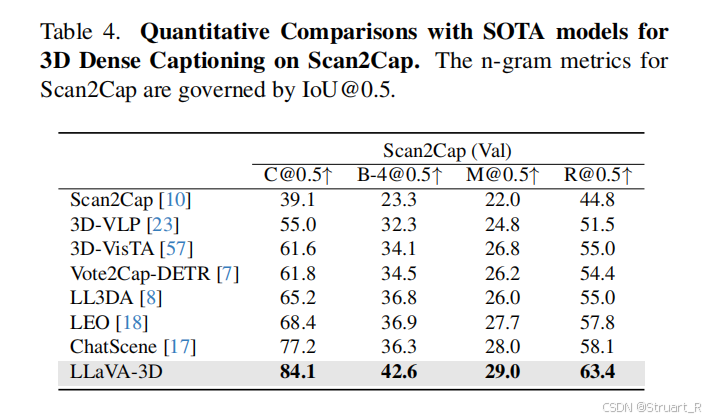
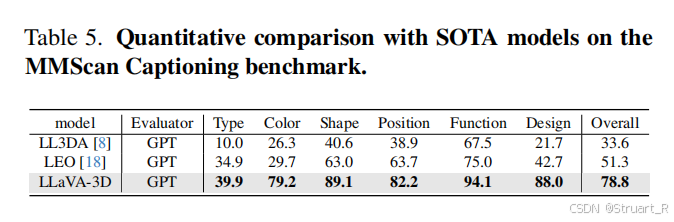
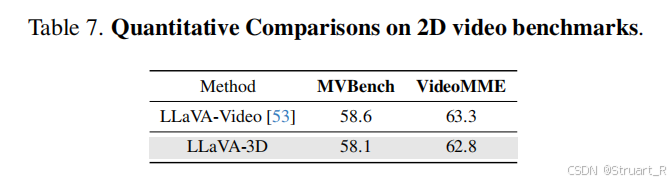
? ? ? ? 同樣對于LLaVA-Video原本的能力,沒有下降(MVBench,VideoMME)。
二、Video-3D LLM
1、概述
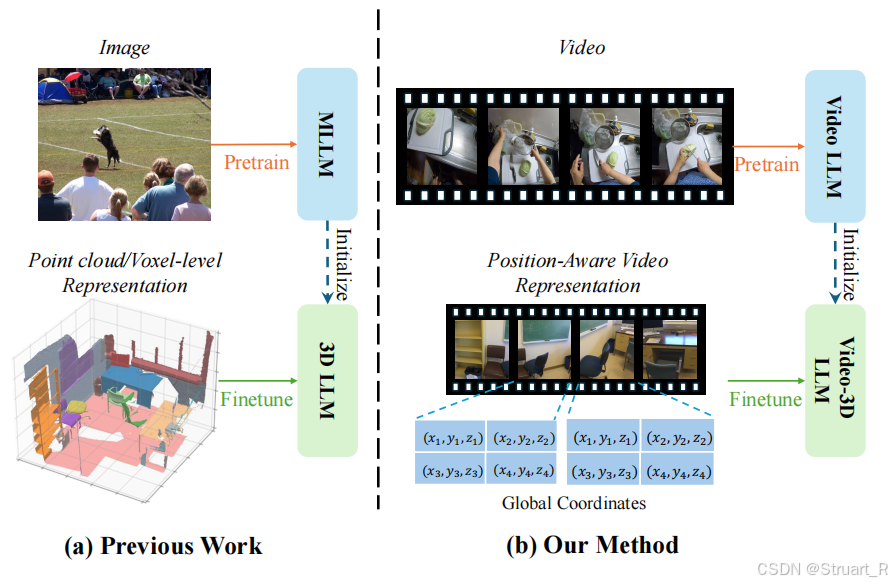
? ? ? ? 對比LLaVA-3D,其實也是視頻幀中獲得空間信息。而且點云信息和體素信息的標注成本過高,不容易實現。
? ? ? ? LLaVA-3D是復用預訓練的2D encoder,避免2D到3D轉換困難。Video-3D LLM是直接利用RGB視頻,不在考慮2D的問題,直接全面采用VideoLLM。在計算效率上,LLaVA-3D采用池化策略,而Video-3D LLM采用最大覆蓋采樣,通過貪婪算法,加速推理時間。同樣的兩者均實現視覺定位問題,LLaVA-3D則引入一個特定的3D感知解碼器,而Video-3D LLM則直接規定一個分類問題,減少架構的繁瑣性。
? ? ? ? 下圖為傳統3D方法的操作,點云標注困難,2D與3D難以對齊。新方法下直接利用視頻并在視頻中標注坐標信息來訓練LLM。
2、方法
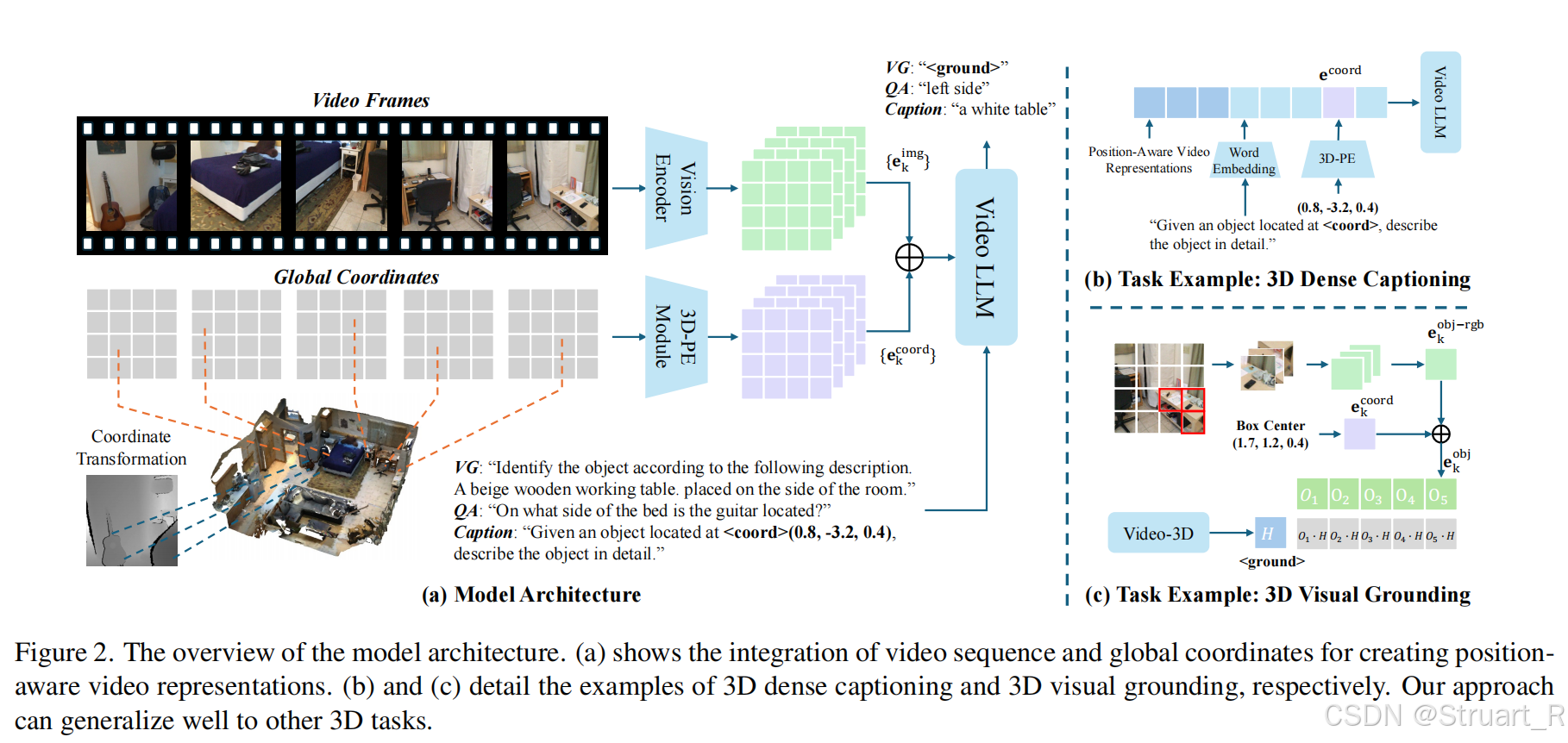
架構
? ? ? ? 輸入:從RGB-D掃描的3D場景中采樣幀序列,通過深度圖反投影得到全局坐標
。
? ? ? ? 視頻幀提取特征:對每一幀通過ViT,先進行patchify之后得到
個圖像并提取特征
。之后對每一個圖像塊
內對應的3D坐標取平均,得到一個塊級的3D坐標。
????????????????????????????????????????
? ? ? ? 3D位置編碼:利用剛才得到的3D坐標進行正弦編碼。
? ? ? ? 對于Video LLM同樣采用LLaVa-Video 7B架構(利用Qwen2.5訓練的,這與LLaVA-3D相同)
? ? ? ? 解碼部分與LLaVA-3D區別非常大,針對于描述問題和定位問題采用了完全不同的結構來計算損失。首先對于描述問題,采用傳統的文本生成問題計算交叉熵損失,對于定位問題,只考慮基于圖片和深度信息得到的與LLM輸出的<ground>tokens部分隱藏層特征
之間的InfoNCE對比損失。
可以理解為圖片經過2D encoder輸出得到
與3D位置編碼
的和。f和g都是可學習的MLP,
為溫度系數。
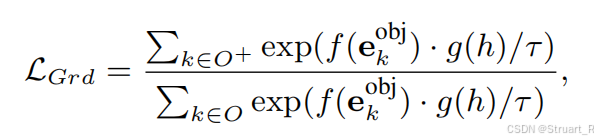
3、訓練過程
? ? ? ? 注意,我們不可能對場景中每一個物體進行描述,,也不能把每一幀作為一個整體來提取caption,這樣物體會存在模糊。所以在訓練過程和推理過程中,都會引入候選框信息。訓練過程中依賴真實的標注物體,而推理過程則利用Mask3D進行標注。
? ? ? ? 假設訓練過程中,我們現在已經根據已知的深度圖獲得了點云信息,那么根據給定的3D標注框,就可以對應到與之重疊的視覺塊(相當于2D的掩碼),并對這一部分視覺特征進行平均池化并加以位置編碼,得到了他這一個掩碼下的tokens信息。
4、實驗
? ? ? ? 為什么要采用與LLaVA-3D不同的采樣方法,因為均勻采樣會失去一些小物體的信息。

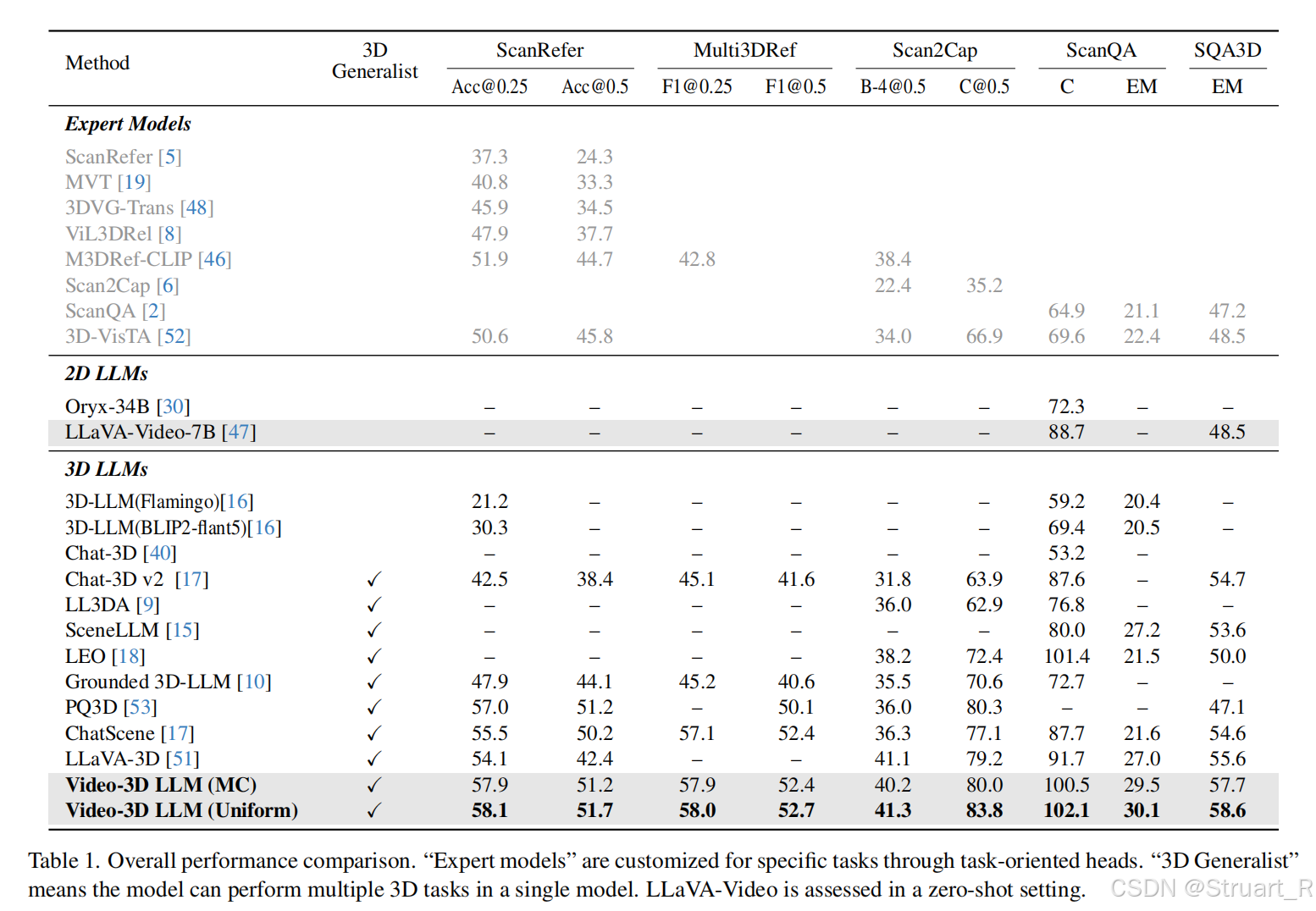
? ? ? ? 定位問題上同樣測試ScanRefer和Multi3DRef指標,這兩個分別是單目標定位和多目標定位。然后同樣對比3D問答,視覺定位,密集描述問題。
三、SPAR
1、概述
? ? ? ? SPAR論文原文是這個《From Flatland to Space: Teaching Vision-Language Models to Perceive and Reason in 3D》
? ? ? ? 動機:由于視覺語言模型在3D空間感知上存在明顯局限,傳統方案依賴顯式3D數據(如點云),但此類數據稀缺且分布不均。SPAR提出核心問題:??能否僅通過2D圖像數據讓VLMs學習3D空間理解??? 其靈感源于人類通過2D觀察隱式重建3D空間的能力。
? ? ? ? 所以,SPAR模型中,在訓練過程中,文本QA標簽由3D真值生成,但模型中并不直接接觸3D點云信息,推理過程中采用純圖像作為輸入。可以理解為SPAR實現了3D到2D的轉換,將3D真值,轉換為大規模生成的2DQA信息。
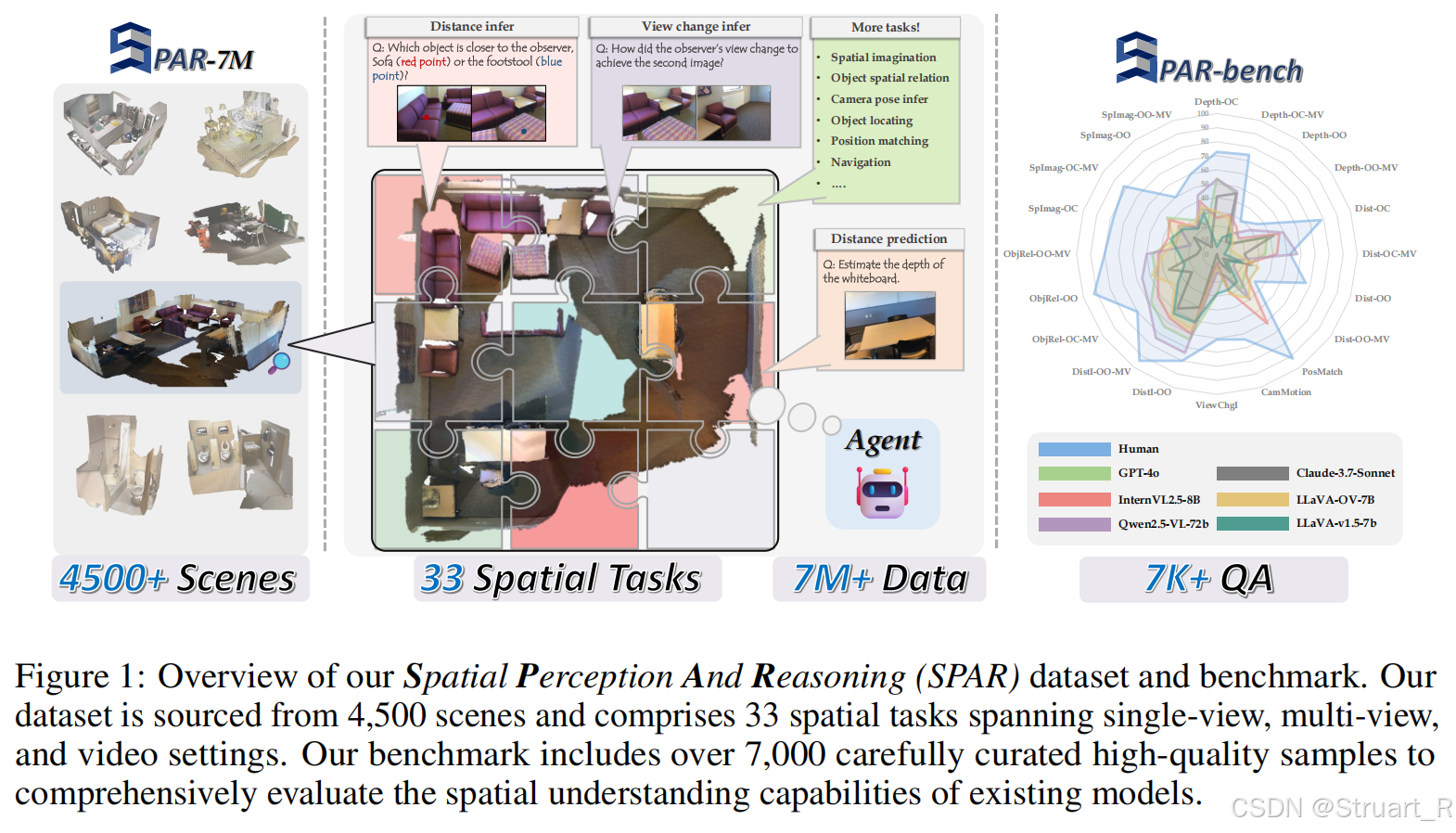
? ? ? ? SPAR為了引入3D數據所以建立了一個7M的數據,補充了單視圖和多視圖的問答信息。但是缺點就是數據量太大了,不容易訓練。同時生成了一個基于SPAR-7M的benchmark。
2、方法
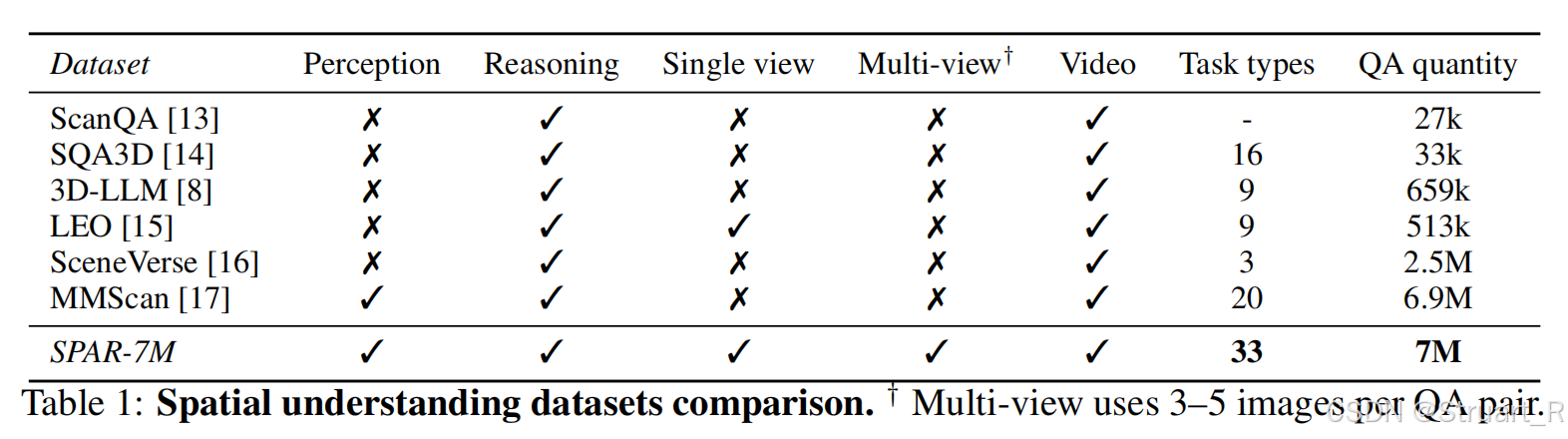
數據集
? ? ? ??數據集來自于ScanNet,ScanNet++,Structured3D的場景共4500+,包含精確地3D網格,物體bbox,相機位姿信息,并且過濾掉相似幀。
? ? ? ? 數據集中包含了每一個物體的位置,在哪一個場景中,在哪一幀中,所以可以用它來建立QA。QA共包含33類任務,覆蓋深度估計,距離預測,甚至視角變換,物體匹配,空間想象等任務。
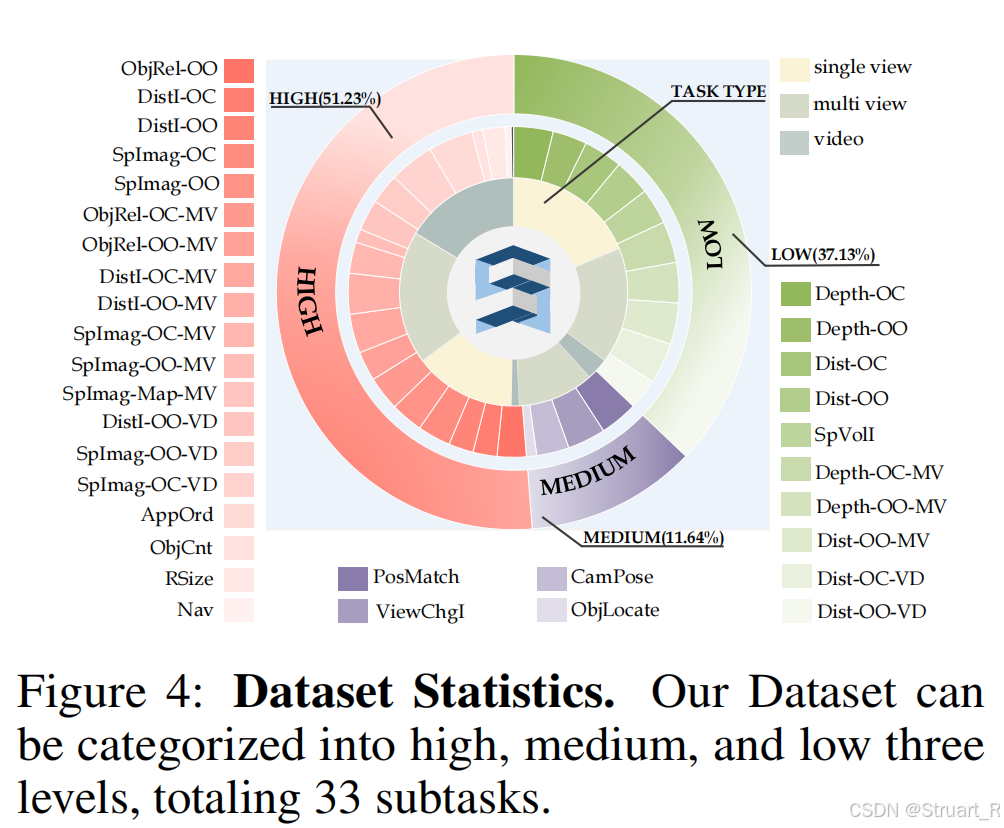
SPAR-Bench
? ? ? ? 從33類任務中精選20類核心任務,排除視頻時序任務。每類任務抽取400個驗證集樣本 → 人工校驗 → 保留 ??7,207高質量QA對?,并且進行人工驗證,剔除模糊/誤導性問題。?
架構
? ? ? ? 主干采用InternVL2.5-8B,沒有別的改進,訓練過程中數據集采用SPAR-mix(SPAR-7M+通用數據混合),并將EMOVA-2M作為通用能力基線,這是一個大規模的通用視覺問答數據集。
? ? ? ? 訓練過程并未描述。
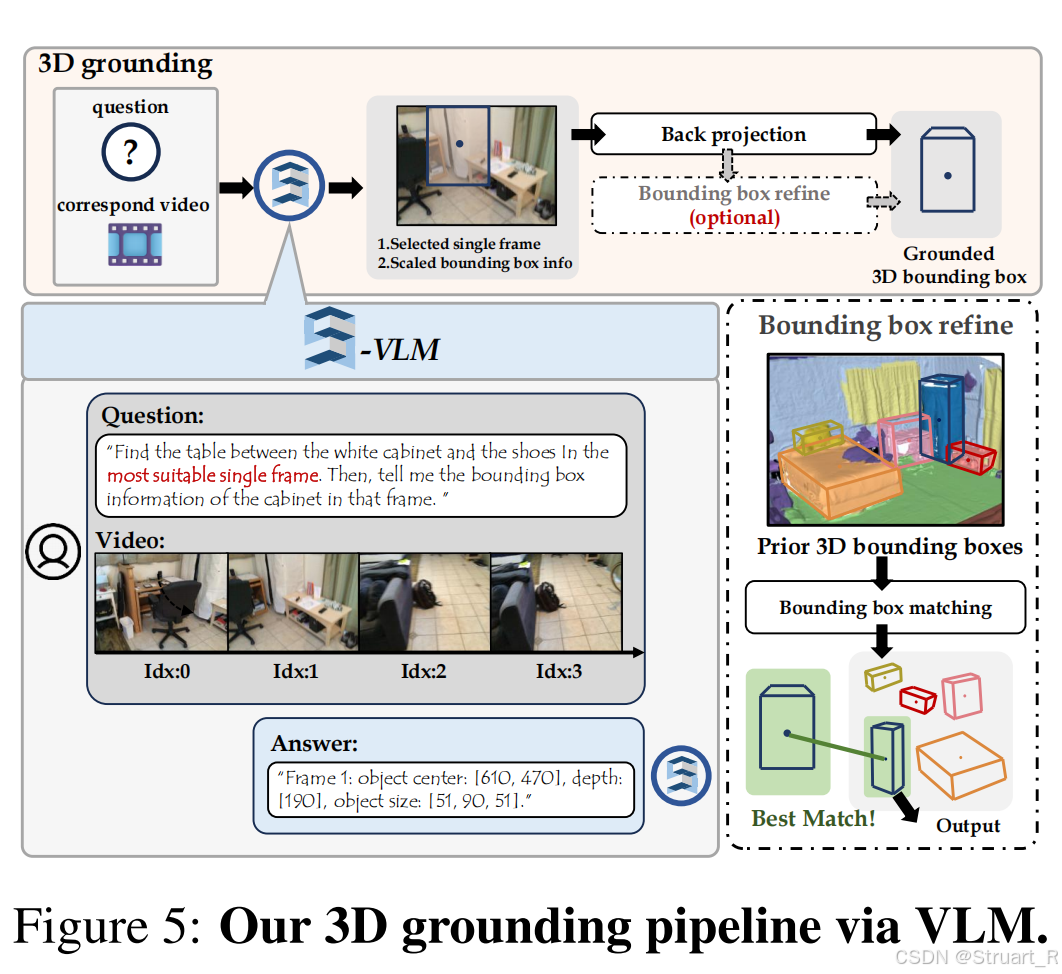
? ? ? ? 對于輸出的文字中的3D定位框部分,通過提前Mask3D得到的檢測框來進行IoU計算,優化3D定位的準確性。但是后面的VG LLM看到,其實這個方式不如直接接一個空間編碼器,而且空間編碼器可以學到更多的空間信息,不需要大量的數據訓練。
4、實驗
? ? ? ? 對于2D通用benchmark和空間理解問題進行評估,主要對比的是baseVLM(internvl2.5),在2D指標上存在明顯的下降,3D性能提高。
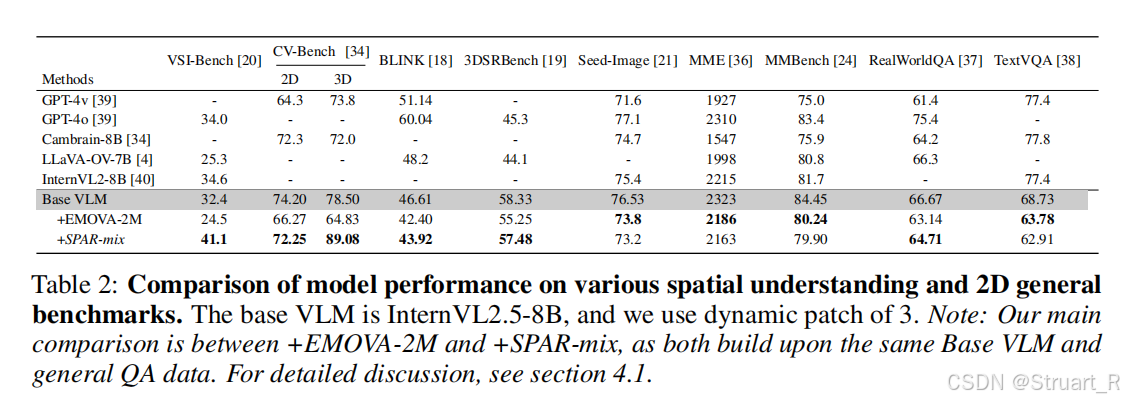
????????SPAR-Bench上不高就奇怪了,數據量在那擺著呢。
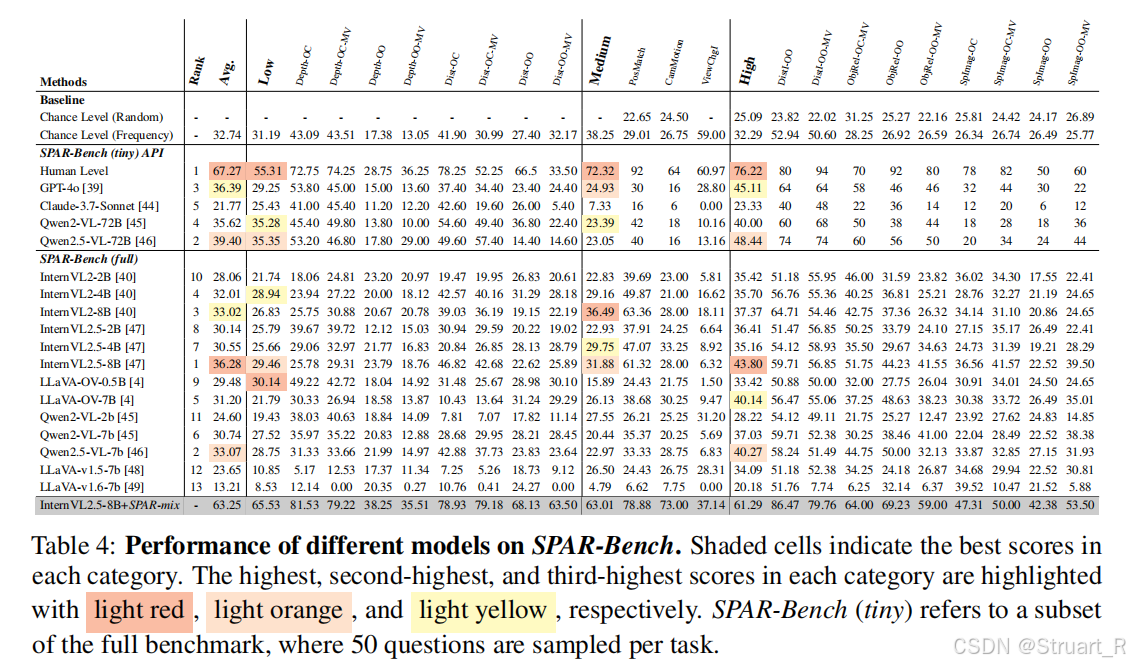
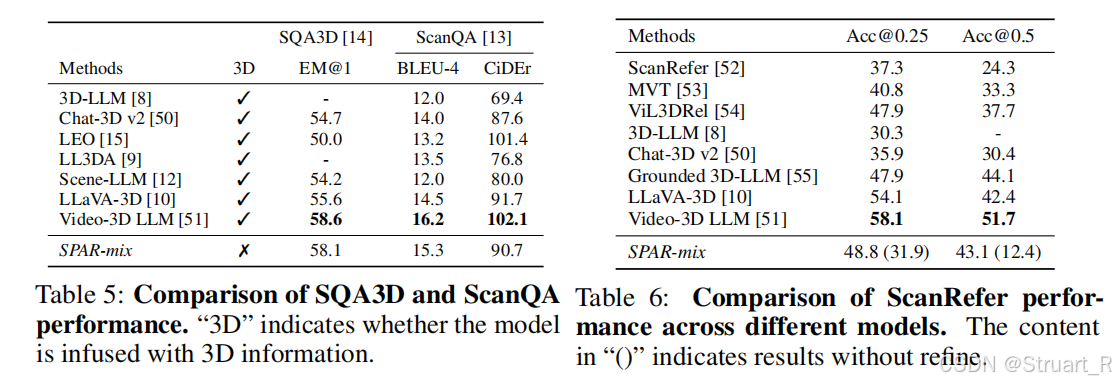
? ? ? ? 其他的定位,描述指標上,不如Video 3D LLM。
四、VG-LLM
1、概述?
? ? ? ? 這個模型解決的是現有方法依賴顯式3D輸入的問題,并不限于最傳統的輸入點云信息,bev地圖,甚至Video-3D LLM這種輸入深度圖的信息。VG-LLM只輸入RGB視頻,無需顯式的3D數據信息。另外相比于后面將介紹的SPAR模型,不僅VG-LLM只需要其3%的數據量就可以訓練,而且不需要隱式的引入3D數據信息。
? ? ? ? 在后續對比實驗中,仍然采用上面的定位,描述,目標檢測問題,甚至對比空間推理性能和通用多模態能力。
2、方法
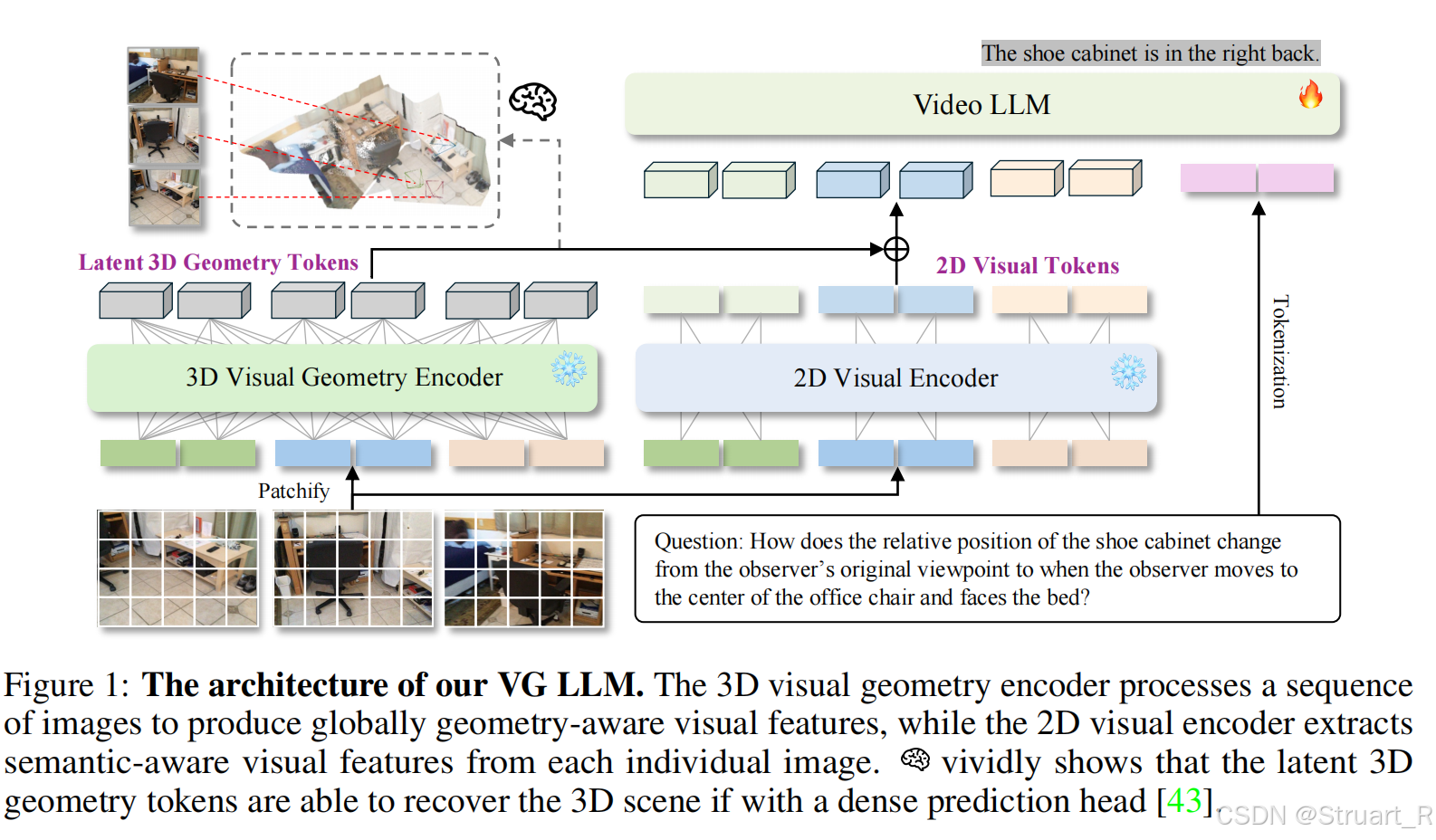
? ? ? ? 這個模型也用到了3D encoder用來提取幾何信息(Spatial-MLLM)
? ? ? ? 首先輸入完全采用RGB圖片,并采用雙流融合設計。
2D Visual Encoder
? ? ? ??2D編碼器不跨幀交互,僅提取單幀語義特征,所以對于輸入的視頻序列,也就是n幀圖形,應該每一幀單獨處理,單獨輸入到編碼器中。
? ? ? ? 視覺編碼器采用Qwen2.5-VL的視覺編碼器,圖像先patchify成若干塊,之后丟入編碼器中生成初始tokens,之后對相鄰的2x2個patches合并為一個token
,減少75%的tokens數量。
? ? ? ? 最后將所有幀的tokens按照索引順序拼接,形成一個完整的2d visual tokens序列
3D Visual Geometry Encoder
? ? ? ? 輸入視頻序列,并輸出幾何特征信息,并且根據2D visual tokens的尺寸,進行下采樣到
。
MLLM
? ? ? ? 主體架構采用Qwen2.5-VL-3B,VGGT采用1B架構。
3、方法? ? ?
數據集
????????VG-LLM 的訓練數據分為三大類,空間推理指令數據,通用視頻指令數據,3D場景理解數據。
? ? ? ? 空間推理指令數據:從三大 3D 數據集人工標注生成:??ScanNet??(室內場景)、??ScanNet++??[(高精度重建)、??Structure3D??(合成場景),覆蓋 ??33 類空間任務??,but僅使用數據集的3%。
? ? ? ? 通用視頻指令數據:從 ??LLaVA-Video-178K??,抽取 ??Hound 子集,聚焦動態場景描述,視頻幀數限制在4-8幀,混合簡單描述和復雜推理任務,保留模型原有的視頻理解能力。
????????3D 場景理解數據:(ScanRefer/Scan2Cap/EmbodiedScan),分別是ScanRefer:3D視覺定位,利用EmbodiedScan的逐幀物體可見性標注,Scan2Cap:密集描述,利用LEO模型預先檢測得到的,視頻目標檢測三類。在標記中完全將3D框轉化為文本信息。
訓練過程
? ? ? ? 對于2D視覺編碼器和3D視覺編碼器均凍結,只訓練幾何與語義對齊的MLP和MLLM骨干網絡。?
? ? ? ? VG-LLM采用統一的文本序列生成問題,并將坐標信息文本化,采用標準交叉熵損失。? ? ??
????????推理過程中對于不同的任務,如果是視覺定位和檢測任務,則輸出特定的文本格式。比如第五幀時,給我棕色椅子的坐標,輸出{"frame":5, "bbox":[1.20,3.45,...]},比如給一個連續的視頻信息,檢測視頻中的物體,輸出{"objects":[{"category":"chair", "bbox":[...]}]},對于3D密集描述信息和空間推理則直接輸出文本信息即可,不需要解析。
4、實驗
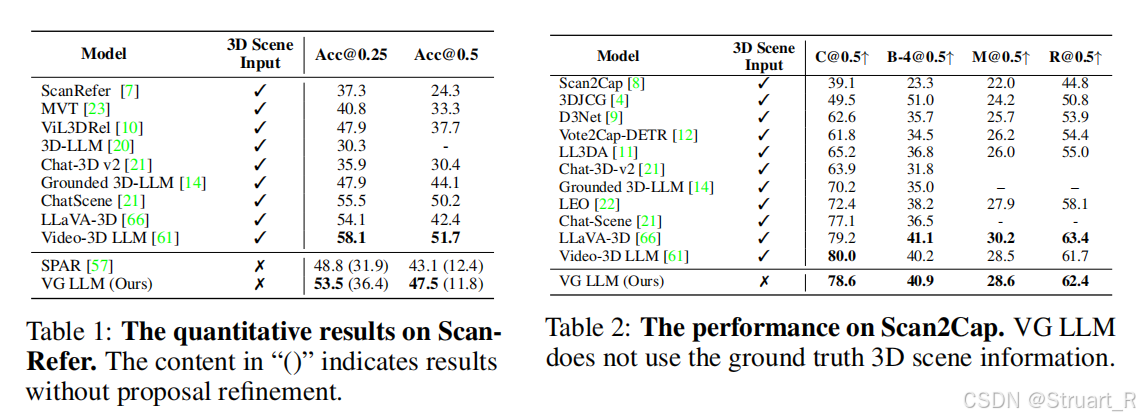
? ? ? ? 定位問題和密集描述上,在不需要3D場景輸入的情況下,超過了SPAR模型,并且逐漸接近Video-3D LLM(并沒有完全超越)
? ? ? ? 對于多模態模型對比上VSI-Bench,距離,尺寸,計數上分數很高。
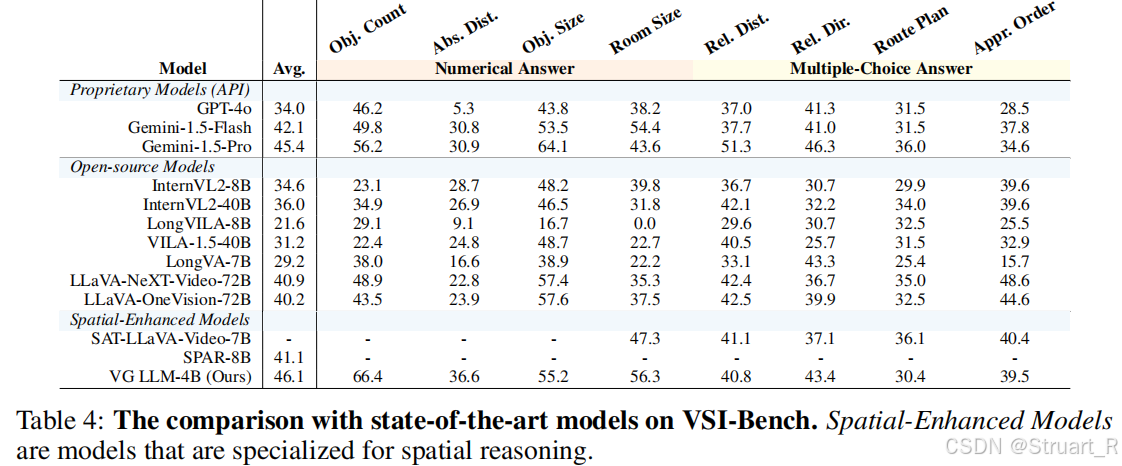
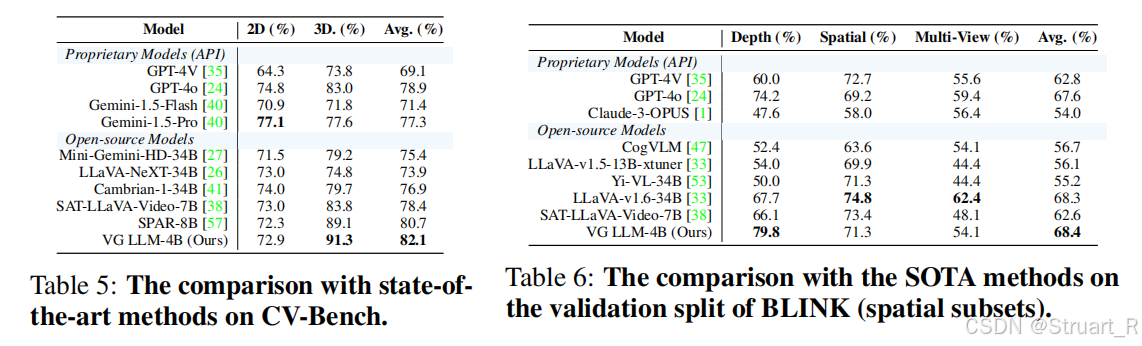
? ? ? ? 跨任務模型BLINK是深度估計性能,CV-Bench是評測MLLM的2D、3D空間感知能力,依賴于傳統CV數據集,在2D,3D上均超過了SPAR-8B模型。
參考論文:
[2409.18125] LLaVA-3D: A Simple yet Effective Pathway to Empowering LMMs with 3D-awareness
???????[2505.24625] Learning from Videos for 3D World: Enhancing MLLMs with 3D Vision Geometry Priors
[2503.22976] From Flatland to Space: Teaching Vision-Language Models to Perceive and Reason in 3D
[2412.00493] Video-3D LLM: Learning Position-Aware Video Representation for 3D Scene Understanding
)
——言語、判斷推理(強化訓練))


)












)
)
保姆級教學)